
I would be very interested in seeing this too as your numbers look extremely good ------Original Message------ From: OvermindDL1 Sender: boost-bounces@lists.boost.org To: boost@lists.boost.org ReplyTo: boost@lists.boost.org Sent: Jul 17, 2009 3:30 PM Subject: Re: [boost] [xpressive] Performance Tuning? On Wed, Jul 15, 2009 at 6:57 AM, OvermindDL1<overminddl1@gmail.com> wrote:
/* snip */
So has anyone tried the code I posted to see how it compared? _______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost Sent from my Verizon Wireless BlackBerry

On Fri, Jul 17, 2009 at 5:10 PM, <raindog@macrohmasheen.com> wrote:
I would be very interested in seeing this too as your numbers look extremely good
As stated, the numbers are basically hogwash until all three forms are all tested on the same hardware using the same compiler. I *might* have time tonight to work on the code that the others posted above to get it compilable, although it is rather irritating that they posted code that was incomplete, but meh. If I have time tonight then I can test all three versions using MSVC8 on WinXP on my old 1.8ghz Opteron CPU. Who knows, one of the other version may still be faster, MSVC does tend to handle optimizing heavy templated code better then other compilers, and Spirit is nothing but basically to be inlined templated code, so it might be able to optimize the xpressive version better as well, and who knows how it will handle the original code.

OvermindDL1 wrote:
On Fri, Jul 17, 2009 at 5:10 PM, <raindog@macrohmasheen.com> wrote:
I would be very interested in seeing this too as your numbers look extremely good
As stated, the numbers are basically hogwash until all three forms are all tested on the same hardware using the same compiler. I *might* have time tonight to work on the code that the others posted above to get it compilable, although it is rather irritating that they posted code that was incomplete, but meh. If I have time tonight then I can test all three versions using MSVC8 on WinXP on my old 1.8ghz Opteron CPU.
Who knows, one of the other version may still be faster, MSVC does tend to handle optimizing heavy templated code better then other compilers, and Spirit is nothing but basically to be inlined templated code, so it might be able to optimize the xpressive version better as well, and who knows how it will handle the original code.
I thought Rob posted his code as an attachment here: http://lists.boost.org/Archives/boost/2009/07/153845.php Is that not complete? -- Eric Niebler BoostPro Computing http://www.boostpro.com
On Fri, Jul 17, 2009 at 5:51 PM, Eric Niebler<eric@boostpro.com> wrote:
OvermindDL1 wrote:
On Fri, Jul 17, 2009 at 5:10 PM, <raindog@macrohmasheen.com> wrote:
I would be very interested in seeing this too as your numbers look extremely good
As stated, the numbers are basically hogwash until all three forms are all tested on the same hardware using the same compiler. I *might* have time tonight to work on the code that the others posted above to get it compilable, although it is rather irritating that they posted code that was incomplete, but meh. If I have time tonight then I can test all three versions using MSVC8 on WinXP on my old 1.8ghz Opteron CPU.
Who knows, one of the other version may still be faster, MSVC does tend to handle optimizing heavy templated code better then other compilers, and Spirit is nothing but basically to be inlined templated code, so it might be able to optimize the xpressive version better as well, and who knows how it will handle the original code.
I thought Rob posted his code as an attachment here:
http://lists.boost.org/Archives/boost/2009/07/153845.php
Is that not complete?
Have you tried compiling it? No, it is not complete, first of all it is missing the includes, as well as a main function to run the loops and test the timings in. :)
On Fri, Jul 17, 2009 at 6:35 PM, OvermindDL1<overminddl1@gmail.com> wrote:
/* snip */
Okay, I cannot for the life of me get that above attached price.cpp file to compile. It is missing includes (apparently expressive needs something that I cannot find either). It is missing a whole core:: namespace worth of functions that both the custom and the xpressive code reference. Other things too. This code is completely worthless until someone gives me something complete that I can actually compile.
On Fri, Jul 17, 2009 at 8:07 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Fri, Jul 17, 2009 at 6:35 PM, OvermindDL1<overminddl1@gmail.com> wrote:
/* snip */
Okay, I cannot for the life of me get that above attached price.cpp file to compile. It is missing includes (apparently expressive needs something that I cannot find either). It is missing a whole core:: namespace worth of functions that both the custom and the xpressive code reference. Other things too. This code is completely worthless until someone gives me something complete that I can actually compile.
Okay, I finally got the xpressive version running, and I made a threadsafe version of the spirit version and a grammar version of the spirit version. All I need now is some code of the original version to get that working. I also put in a high-resolution timer and a testing setup. Here is one run: Loop count: 10000000 Parsing: 42.5 xpressive: 48.3714 spirit-quick(static): 2.73373 spirit-quick_new(threadsafe): 2.8916 spirit-grammar(threadsafe/reusable): 11.5694 Yes, 7 zero's, not 6, so this test is 10 times slower then what the other email linked. xpressive is about 50% faster then the times that other email gave, so my compiler and processor probably optimize better and run faster. The Spirit version, even the slowest method, blows it out of the water though, to put it mildly. So, if anyone can give me an actual USEFUL version of the above price.cpp that someone else attached, then I can test the original customized version.
On Fri, Jul 17, 2009 at 11:32 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Fri, Jul 17, 2009 at 8:07 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Fri, Jul 17, 2009 at 6:35 PM, OvermindDL1<overminddl1@gmail.com> wrote:
/* snip */
Okay, I cannot for the life of me get that above attached price.cpp file to compile. It is missing includes (apparently expressive needs something that I cannot find either). It is missing a whole core:: namespace worth of functions that both the custom and the xpressive code reference. Other things too. This code is completely worthless until someone gives me something complete that I can actually compile.
Okay, I finally got the xpressive version running, and I made a threadsafe version of the spirit version and a grammar version of the spirit version. All I need now is some code of the original version to get that working. I also put in a high-resolution timer and a testing setup. Here is one run: Loop count: 10000000 Parsing: 42.5 xpressive: 48.3714 spirit-quick(static): 2.73373 spirit-quick_new(threadsafe): 2.8916 spirit-grammar(threadsafe/reusable): 11.5694
Er, correction, the grammar version I forgot to cache something, making it much slower then it should have been. Here are two other correct runs: Loop count: 1000000 Parsing: 42.5 xpressive: 4.62519 spirit-quick(static): 0.27437 spirit-quick_new(threadsafe): 0.278761 spirit-grammar(threadsafe/reusable): 0.311138 Loop count: 10000000 Parsing: 42.5 xpressive: 46.1108 spirit-quick(static): 2.72641 spirit-quick_new(threadsafe): 2.84515 spirit-grammar(threadsafe/reusable): 3.1393 So yea, this looks a *lot* better.

OvermindDL1 wrote:
Er, correction, the grammar version I forgot to cache something, making it much slower then it should have been. Here are two other correct runs:
Loop count: 1000000 Parsing: 42.5 xpressive: 4.62519 spirit-quick(static): 0.27437 spirit-quick_new(threadsafe): 0.278761 spirit-grammar(threadsafe/reusable): 0.311138
Loop count: 10000000 Parsing: 42.5 xpressive: 46.1108 spirit-quick(static): 2.72641 spirit-quick_new(threadsafe): 2.84515 spirit-grammar(threadsafe/reusable): 3.1393
So yea, this looks a *lot* better. _______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost
Thank you for pulling this together. Would you mind sharing your test suite? -- ---------------------------------- Michael Caisse Object Modeling Designs www.objectmodelingdesigns.com
Michael Caisse wrote:
OvermindDL1 wrote:
Parsing: 42.5 <snip> spirit-grammar(threadsafe/reusable): 3.1393
Thank you for pulling this together. Would you mind sharing your test suite?
Yes, please. I know Spirit2 is great tech, but I have to wonder how it's over 10X faster than the hand-coded parser. -- Eric Niebler BoostPro Computing http://www.boostpro.com
On Sat, Jul 18, 2009 at 2:13 AM, Eric Niebler<eric@boostpro.com> wrote:
Michael Caisse wrote:
OvermindDL1 wrote:
Parsing: 42.5
<snip>
spirit-grammar(threadsafe/reusable): 3.1393
Thank you for pulling this together. Would you mind sharing your test suite?
Er, I meant to attach it, it is attached now. :) It requires Boost trunk, and the timer file hpp I include is part of the Boost.Spirit2.1 examples/test/somewhere_in_there area, but I included it with my cpp file too so you do not need to hunt for it. The defines at the top control what parts to compile or not, 0 to disable compiling for that part, 1 to enable it. My build is built with Visual Studio 8 (2005) with SP1. Compiler options are basically defaults, except getting rid of the secure crt crap that Microsoft screwed up (enabling that crap slows down Spirit parsers on my system, a *lot*). The exe I built is in the 7zip file attached. As stated, I have heard that Visual Studio handles template stuff like Spirit better then GCC, so I am very curious how GCC's timings on this file would be. There are still more changes to make that I intend to make, but I really want the original code in a way that I can use it. To be honest, I had to change the core::to_number lines (commented out) to boost::lexical_cast (right below the commented version), so the xpressive version could be slightly faster if I actually had the implementation of core::to_number available, and core::to_number was well made. The xpressive code also throws a nice 100 line long warning in my build log, all just about a conversion warning from double to int_64, no clue how to fix that, I do not know xpressive, so I would gladly like it if someone could get rid of that nasty warning in my nice clean buildlog. In my compiler, my Spirit2.1 grammar builds perfectly clean, I would like it if xpressive was the same way. I honestly do not know *why* the Spirit version is so much faster then the xpressive version, the spirit-quick version (the non-threadsafe) I whipped up in about 2 minutes. The threadsafe version took about 5 minutes, the grammar/threadsafe/reusable version took about 10 minutes, and I know a lot more work was put into the xpressive version, especially with the auto macros added and all such as well. I would love it if someone could find out way. If someone else with MSVC, and someone with GCC and perhaps other things could build it and display the results that it prints out too, I would be much appreciative. I do have a linux computer here, but, to be honest, no clue what to pass to gcc to build something, the command line switches I pass to MSVC's version is rather monstrous, so trying to convert that to GCC's seems nightmarish from my point of view. On Sat, Jul 18, 2009 at 2:13 AM, Eric Niebler<eric@boostpro.com> wrote:
Yes, please. I know Spirit2 is great tech, but I have to wonder how it's over 10X faster than the hand-coded parser. And I have not tested the hand-coded parser as I cannot get it to compile. If you can get me a code-complete standalone version of it, I would be very happy. :)
Either way, Windows users, could you please run the attached exe (that is in the 7zip file) and paste the results it tells you in an email to this thread, along with your windows version and basic hardware? Before I attach this, I am going to run the release exe through a profiler right quick. With 1000000 iterations (one million so the xpressive version does not take so long), with just the xpressive version enabled, the top 10 slowest functions: CS:EIP Symbol + Offset 64-bit CPU clocks IPC DC miss rate DTLB L1M L2M rate Misalign rate Mispredict rate 0x421860 strcmp 2248 1.98 0 0 0 0 0x42bc84 __strgtold12_l 1196 1.1 0 0 0.02 0.01 0x4068a0 std::operator<<<std::char_traits<char> > 744 1.06 0 0 0 0.02 0x41d864 TrailUpVec 686 0.03 0.11 0 0 0 0x40e0e0 std::num_get<char,std::istreambuf_iterator<char,std::char_traits<char>
::_Getffld
571 0.94 0 0 0 0.01 0x42d344 __mtold12 447 2.2 0 0 0 0 0x4170a0 std::basic_istream<char,std::char_traits<char> >::operator>> 406 0.38 0 0 0.05 0.08 0x414150 boost::xpressive::detail::posix_charset_matcher<boost::xpressive::cpp_regex_traits<char>
::match<std::_String_const_iterator<char,std::char_traits<char>,std::allocator<char> ,boost::xpressive::detail::static_xpression<boost::xpressive::detail::true_matcher, 358 1.36 0 0 0 0 0x419231 std::_Lockit::~_Lockit
334 0.26 0 0 0 0 0x42b200 _ld12tod 333 1.05 0 0 0.01 0.01 10 functions, 700 instructions, Total: 48191 samples, 50.01% of samples in the module, 31.99% of total session samples So it looks like strcmp i massively hobbling it, taking almost twice the time of the next highest user. Now for 1000000 (one million) of just the spirit quick version (all calls, surprisingly few): CS:EIP Symbol + Offset 64-bit CPU clocks IPC DC miss rate DTLB L1M L2M rate Misalign rate Mispredict rate 0x4188c9 _pow_pentium4 358 1.04 0 0 0 0 0x404d70 ??$phrase_parse@PBDU?$expr@Ubitwise_or@tag@proto@boost@@U?$list2@ABU?$expr@Ushift_right@tag@proto@boost@@U?$list2@ABU?$expr@Ushift_right@tag@proto@boost@@U?$list2@ABU?$expr@Usubscript@tag@proto@boost@@U?$list2@ABU?$terminal073d7121f2c9203b84cbac5f1ea1214c 116 1.71 0 0 0 0 0x405080 boost::spirit::qi::detail::real_impl<double,boost::spirit::qi::real_policies<double>
::parse<char const *,double>
76 1.21 0 0 0 0 0x405f90 boost::spirit::qi::detail::extract_int<__int64,10,1,-1,boost::spirit::qi::detail::positive_accumulator<10>,0>::parse_main<char const *,__int64> 68 2.35 0 0 0 0 0x405550 boost::spirit::qi::detail::extract_int<double,10,1,-1,boost::spirit::qi::detail::positive_accumulator<10>,0>::parse_main<char const *,double> 66 1.82 0 0 0 0 0x4053e0 boost::spirit::qi::detail::`anonymous namespace'::scale_number<double> 63 1.14 0 0 0 0 0x404300 parse_price_spirit_quick<char const *> 62 1.31 0 0 0 0.03 0x4054e0 boost::spirit::qi::detail::fail_function<char const *,boost::fusion::unused_type const ,boost::spirit::qi::char_class<boost::spirit::tag::char_code<boost::spirit::tag::blank,boost::spirit::char_encoding::ascii>
::operator()<boost::spirit::qi::action<boost: 59 1.78 0 0 0 0 0x404f30 boost::spirit::qi::skip_over<char const *,boost::spirit::qi::char_class<boost::spirit::tag::char_code<boost::spirit::tag::blank,boost::spirit::char_encoding::ascii>
58 1.59 0 0 0 0 0x417b90 floor
48 0.67 0 0 0 0 0x417b16 _ftol2 46 2.37 0 0 0 0 0x4018f0 dotNumber 42 0.86 0 0 0 0 0x404fa0 boost::spirit::qi::action<boost::spirit::qi::real_parser_impl<double,boost::spirit::qi::real_policies<double>
,void (__cdecl*)(double)>::parse<char const *,boost::fusion::unused_type const ,boost::spirit::qi::char_class<boost::spirit::tag::char_code<boost::s 41 1.12 0 0 0 0 0x405660 boost::spirit::qi::detail::extract_int<double,10,1,-1,boost::spirit::qi::detail::positive_accumulator<10>,1>::parse_main<char const *,double>
31 1.29 0 0 0 0 0x417890 _CIpow 31 1.68 0 0 0 0 0x405af0 boost::spirit::qi::int_parser_impl<__int64,10,1,-1>::parse<char const *,boost::fusion::unused_type const ,boost::spirit::qi::char_class<boost::spirit::tag::char_code<boost::spirit::tag::blank,boost::spirit::char_encoding::ascii>
,__int64> 29 0.48 0 0 0 0 0x405010 boost::spirit::qi::action<boost::spirit::qi::real_parser_impl<double,boost::spirit::qi::real_policies<double> ,void (__cdecl*)(double)>::parse<char const *,boost::fusion::unused_type const ,boost::spirit::qi::char_class<boost::spirit::tag::char_code<boost::s 27 1.04 0 0 0 0 0x4174c0 _allmul
27 1 0 0 0 0 0x405b60 boost::spirit::qi::not_predicate<boost::spirit::qi::literal_char<boost::spirit::char_encoding::standard,1,0>
::parse<char const *,boost::fusion::unused_type const ,boost::spirit::qi::char_class<boost::spirit::tag::char_code<boost::spirit::tag::blank,boost::s 25 1 0 0 0 0 0x404ec0 bo$phrase_parse@PBDU?$expr@Ubitwise_or@tag@proto@boost@@U?$list2@ABU?$expr@Ushift_right@tag@proto@boost@@U?$list2@ABU?$expr@Ushift_right@tag@proto@boost@@U?$list2@ABU?$expr@Usubscript@tag@proto@boost@@U?$list2@ABU?$terminal073d7121f2c9203b84cbac5f1ea1214c 23 0.17 0 0 0 0.12 0x417bd0 _floor_pentium4
17 0.24 0 0 0 0 0x4188b0 _CIpow_pentium4 14 0 0 0 0 0 0x401970 main 9 0.11 0 0 0 0.3 0x404f10 boost::spirit::qi::skip_over<char const *,boost::spirit::qi::char_class<boost::spirit::tag::char_code<boost::spirit::tag::blank,boost::spirit::char_encoding::ascii>
4 0 0 0 0 0 0x40cc02 _flsbuf
1 0 0 0 0 0 0x40e8b0 __SEH_prolog4 0 0 0 0 0 0 26 functions, 447 instructions, Total: 6513 samples, 100.00% of samples in the module, 69.20% of total session samples Now for the same, but with the spirit grammar version, since it is so much slower then the quick for some reason (all calls again, not that many): CS:EIP Symbol + Offset 64-bit CPU clocks IPC DC miss rate DTLB L1M L2M rate Misalign rate Mispredict rate 0x419909 _pow_pentium4 365 0.97 0 0 0 0 0x4056a0 boost::function4<bool,char const * &,char const * const &,boost::spirit::context<boost::fusion::cons<__int64 &,boost::fusion::nil>,boost::fusion::vector0<void> > &,boost::spirit::qi::char_class<boost::spirit::tag::char_code<boost::spirit::tag::blank,boost::sp 129 1.19 0 0 0 0.02 0x405780 boost::detail::function::function_obj_invoker4<boost::spirit::qi::detail::parser_binder<boost::spirit::qi::alternative<boost::fusion::cons<boost::spirit::qi::reference<boost::spirit::qi::rule<char const *,__int64 __cdecl(void),boost::proto::exprns_::expr<boos 99 1.12 0 0 0 0.03 0x406f50 boost::spirit::qi::detail::extract_int<__int64,10,1,-1,boost::spirit::qi::detail::positive_accumulator<10>,0>::parse_main<char const *,__int64> 81 1.28 0 0 0 0 0x406100 boost::spirit::qi::detail::real_impl<double,boost::spirit::qi::real_policies<double>
::parse<char const *,double>
77 1.38 0 0 0 0 0x406bc0 boost::spirit::qi::rule<char const *,__int64 __cdecl(void),boost::proto::exprns_::expr<boost::proto::tag::terminal,boost::proto::argsns_::term<boost::spirit::tag::char_code<boost::spirit::tag::blank,boost::spirit::char_encoding::ascii>
,0>,boost::fusion::unu 77 0.87 0 0 0 0.04 0x406c30 boost::spirit::qi::action<boost::spirit::qi::int_parser_impl<__int64,10,1,-1>,boost::phoenix::actor<boost::phoenix::composite<boost::phoenix::assign_eval,boost::fusion::vector<boost::spirit::attribute<0>,boost::phoenix::composite<boost::phoenix::multiplies_ev 74 1.61 0 0 0 0 0x406620 boost::spirit::qi::detail::extract_int<double,10,1,-1,boost::spirit::qi::detail::positive_accumulator<10>,0>::parse_main<char const *,double>
64 1.22 0 0 0 0 0x4050b0 boost::spirit::qi::phrase_parse<char const *,price_grammar<char const *>,boost::proto::exprns_::expr<boost::proto::tag::terminal,boost::proto::argsns_::term<boost::spirit::tag::char_code<boost::spirit::tag::blank,boost::spirit::char_encoding::ascii>
,0>,__in 56 0.29 0 0 0 0.11 0x406460 boost::spirit::qi::detail::`anonymous namespace'::scale_number<double>
53 1.79 0 0 0 0 0x405810 boost::detail::function::function_obj_invoker4<boost::spirit::qi::detail::parser_binder<boost::spirit::qi::alternative<boost::fusion::cons<boost::spirit::qi::reference<boost::spirit::qi::rule<char const *,__int64 __cdecl(void),boost::proto::exprns_::expr<boos 52 1.98 0 0 0 0.02 0x418b56 _ftol2 50 1.68 0 0 0 0 0x401940 main 45 0.67 0 0 0 0.04 0x405fe0 boost::spirit::traits::action_dispatch<boost::spirit::qi::real_parser_impl<double,boost::spirit::qi::real_policies<double>
::operator()<dot_number_to_long_long_function,double,boost::spirit::context<boost::fusion::cons<__int64 &,boost::fusion::nil>,boost:: 43 1.19 0 0 0 0 0x405f70 boost::spirit::qi::action<boost::spirit::qi::real_parser_impl<double,boost::spirit::qi::real_policies<double> ,dot_number_to_long_long_function>::parse<char const *,boost::spirit::context<boost::fusion::cons<__int64 &,boost::fusion::nil>,boost::fusion::vecto 41 0.83 0 0 0 0 0x405930 boost::detail::function::function_obj_invoker4<boost::spirit::qi::detail::parser_binder<boost::spirit::qi::action<boost::spirit::qi::real_parser_impl<double,boost::spirit::qi::real_policies<double> ,dot_number_to_long_long_function>,boost::mpl::bool_<0> >,bo 36 2 0 0 0 0 0x418bd0 floor
34 1.12 0 0 0 0 0x405e60 boost::spirit::qi::action<boost::spirit::qi::real_parser_impl<double,boost::spirit::qi::real_policies<double>
,dot_number_to_long_long_function>::parse<char const *,boost::spirit::context<boost::fusion::cons<__int64 &,boost::fusion::nil>,boost::fusion::vecto 33 0.15 0 0 0 0.28 0x4182a0 _allmul
33 3.42 0 0 0 0 0x4188d0 _CIpow 27 0.52 0 0 0 0 0x406730 boost::spirit::qi::detail::extract_int<double,10,1,-1,boost::spirit::qi::detail::positive_accumulator<10>,1>::parse_main<char const *,double> 26 2.62 0 0 0 0 0x406560 boost::spirit::qi::int_parser_impl<__int64,10,1,-1>::parse<char const *,boost::spirit::context<boost::fusion::cons<__int64 &,boost::fusion::nil>,boost::fusion::vector0<void>
,boost::spirit::qi::char_class<boost::spirit::tag::char_code<boost::spirit::tag::bla 19 0.16 0 0 0 0 0x418c10 _floor_pentium4
16 0 0 0 0 0 0x406ca0 boost::spirit::qi::not_predicate<boost::spirit::qi::literal_char<boost::spirit::char_encoding::standard,1,0>
::parse<char const *,boost::spirit::context<boost::fusion::cons<__int64 &,boost::fusion::nil>,boost::fusion::vector0<void> ,boost::spirit::qi::char_ 11 0.36 0 0 0 0 0x4198f0 _CIpow_pentium4
11 0 0 0 0 0 0x40b090 _flush 1 0 0 0 0 0 26 functions, 451 instructions, Total: 7342 samples, 100.00% of samples in the module, 71.73% of total session samples
OvermindDL1 wrote:
To be honest, I had to change the core::to_number lines (commented out) to boost::lexical_cast (right below the commented version), so the xpressive version could be slightly faster if I actually had the implementation of core::to_number available, and core::to_number was well made.
This could very well be the source of a major slow-down. Doesn't lexical_cast use string streams to do the conversion? It seems to me that you're comparing apples to oranges. Also, the warning you saw came from the user-created semantic action, not from xpressive. Robert, can you please post your complete code so that we can actually have meaningful numbers to look at? Thanks. -- Eric Niebler BoostPro Computing http://www.boostpro.com

Eric Niebler wrote:
Robert, can you please post your complete code so that we can actually have meaningful numbers to look at? Thanks.
I will do so as soon as I'm able. _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.
Stewart, Robert wrote:
Eric Niebler wrote:
Robert, can you please post your complete code so that we can actually have meaningful numbers to look at? Thanks.
I will do so as soon as I'm able.
As a step in that direction, I have placed a file in the vault which contains test inputs and the corresponding result, as gleaned from a run of my test suite: http://tinyurl.com/n77jt4. _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.

OvermindDL1 wrote: <snip>
As stated, I have heard that Visual Studio handles template stuff like Spirit better then GCC, so I am very curious how GCC's timings on this file would be.
Alas, gcc doesn't do so well. I had to make a few tweaks to your code (you typedefed int64_t at global scope which clashes with the one in the C library headers, and you used an INT64 macro which doesn't exist here) but then I got a very long error ending with this: .../boost-trunk/boost/proto/transform/call.hpp:146: internal compiler error: Segmentation fault I guess the metaprogramming is too much for it :(. That was with -O3 -DNDEBUG -march=native and gcc version: gcc (Gentoo 4.3.3-r2 p1.2, pie-10.1.5) 4.3.3 So then I tried icc 10.1 (essentially same options) which takes over a minute to compile this, but does succeed. With that I got: $ ./price-icc Loop count: 10000000 Parsing: 42.5 xpressive: 27.4704 spirit-quick(static): 1.58132 spirit-quick_new(threadsafe): 1.52971 spirit-grammar(threadsafe/reusable): 1.64666 which are much the same as your results (except ~1.7 times faster all round), but the Parsing result is obviously meaningless and the xpressive also dubious because of lexical_cast. I then tried with icc's inter-procedural optimisations turned on too, which improves the xpressive code significantly, but doesn't obviously affect spirit: $ ./price-icc-ipo Loop count: 10000000 Parsing: 42.5 xpressive: 17.3577 spirit-quick(static): 1.52487 spirit-quick_new(threadsafe): 1.51834 spirit-grammar(threadsafe/reusable): 1.65164 Finally I used static linking, and the xpressive time improved again, and maybe the others a little. This surprised me. $ ./price-icc-ipo-static Loop count: 10000000 Parsing: 42.5 xpressive: 12.6157 spirit-quick(static): 1.49887 spirit-quick_new(threadsafe): 1.48146 spirit-grammar(threadsafe/reusable): 1.62731 John Bytheway
On Sat, Jul 18, 2009 at 9:15 AM, Eric Niebler<eric@boostpro.com> wrote:
OvermindDL1 wrote:
To be honest, I had to change the core::to_number lines (commented out) to boost::lexical_cast (right below the commented version), so the xpressive version could be slightly faster if I actually had the implementation of core::to_number available, and core::to_number was well made.
This could very well be the source of a major slow-down. Doesn't lexical_cast use string streams to do the conversion? It seems to me that you're comparing apples to oranges.
Yes, as I complained about multiple times in this thread about people not posting complete code snippets, what am I supposed to make of a function call that does not exist? On Sat, Jul 18, 2009 at 1:51 PM, John Bytheway<jbytheway+boost@gmail.com> wrote:
OvermindDL1 wrote: <snip>
As stated, I have heard that Visual Studio handles template stuff like Spirit better then GCC, so I am very curious how GCC's timings on this file would be.
Alas, gcc doesn't do so well. I had to make a few tweaks to your code (you typedefed int64_t at global scope which clashes with the one in the C library headers, and you used an INT64 macro which doesn't exist here) but then I got a very long error ending with this:
.../boost-trunk/boost/proto/transform/call.hpp:146: internal compiler error: Segmentation fault
I guess the metaprogramming is too much for it :(.
That was with -O3 -DNDEBUG -march=native and gcc version: gcc (Gentoo 4.3.3-r2 p1.2, pie-10.1.5) 4.3.3
I do not get that, GCC usually handles more templates then MSVC ever has, just usually not as optimized, so I do not understand how you could be getting a compiler error. On Sat, Jul 18, 2009 at 1:51 PM, John Bytheway<jbytheway+boost@gmail.com> wrote:
So then I tried icc 10.1 (essentially same options) which takes over a minute to compile this, but does succeed. With that I got:
$ ./price-icc Loop count: 10000000 Parsing: 42.5 xpressive: 27.4704 spirit-quick(static): 1.58132 spirit-quick_new(threadsafe): 1.52971 spirit-grammar(threadsafe/reusable): 1.64666
which are much the same as your results (except ~1.7 times faster all round), but the Parsing result is obviously meaningless and the xpressive also dubious because of lexical_cast.
I then tried with icc's inter-procedural optimisations turned on too, which improves the xpressive code significantly, but doesn't obviously affect spirit:
$ ./price-icc-ipo Loop count: 10000000 Parsing: 42.5 xpressive: 17.3577 spirit-quick(static): 1.52487 spirit-quick_new(threadsafe): 1.51834 spirit-grammar(threadsafe/reusable): 1.65164
Finally I used static linking, and the xpressive time improved again, and maybe the others a little. This surprised me.
$ ./price-icc-ipo-static Loop count: 10000000 Parsing: 42.5 xpressive: 12.6157 spirit-quick(static): 1.49887 spirit-quick_new(threadsafe): 1.48146 spirit-grammar(threadsafe/reusable): 1.62731
Regardless, all of these numbers and times are vastly higher then what the previous person posted, so very nice. We just need the compilable original code to see how it compares now. Hmm, I might try to replace all the lexical_cast's with a spirit parser for just that number, for a single extraction like that, Spirit compiles to *very* little assembly, quite impressive actually.

OvermindDL1 wrote:
Parsing: 42.5
<snip>
spirit-grammar(threadsafe/reusable): 3.1393
Thank you for pulling this together. Would you mind sharing your test suite?
Er, I meant to attach it, it is attached now. :) It requires Boost trunk, and the timer file hpp I include is part of the Boost.Spirit2.1 examples/test/somewhere_in_there area, but I included it with my cpp file too so you do not need to hunt for it. The defines at the top control what parts to compile or not, 0 to disable compiling for that part, 1 to enable it.
My build is built with Visual Studio 8 (2005) with SP1. Compiler options are basically defaults, except getting rid of the secure crt crap that Microsoft screwed up (enabling that crap slows down Spirit parsers on my system, a *lot*). The exe I built is in the 7zip file attached. As stated, I have heard that Visual Studio handles template stuff like Spirit better then GCC, so I am very curious how GCC's timings on this file would be. There are still more changes to make that I intend to make, but I really want the original code in a way that I can use it. To be honest, I had to change the core::to_number lines (commented out) to boost::lexical_cast (right below the commented version), so the xpressive version could be slightly faster if I actually had the implementation of core::to_number available, and core::to_number was well made. The xpressive code also throws a nice 100 line long warning in my build log, all just about a conversion warning from double to int_64, no clue how to fix that, I do not know xpressive, so I would gladly like it if someone could get rid of that nasty warning in my nice clean buildlog. In my compiler, my Spirit2.1 grammar builds perfectly clean, I would like it if xpressive was the same way.
Here are my results (platform: Windows7, Intel Core Duo(tm) Processor, 2.8GHz, 4GByte RAM), I reduced the number of iterations to 1e6. VC8SP1/32Bit Loop count: 1000000 Parsing: 42.5 xpressive: 4.53867 spirit-quick(static): 0.213174 spirit-quick_new(threadsafe): 0.255517 spirit-grammar(threadsafe/reusable): 0.228167 VC10 beta/32Bit: Loop count: 1000000 Parsing: 42.5 xpressive: 4.68044 spirit-quick(static): 0.245641 spirit-quick_new(threadsafe): 0.279981 spirit-grammar(threadsafe/reusable): 0.252697 VC10 beta/64Bit: Loop count: 1000000 Parsing: 42.5 xpressive: 3.7877 spirit-quick(static): 0.17625 spirit-quick_new(threadsafe): 0.175377 spirit-grammar(threadsafe/reusable): 0.137707 gcc 4.4.1 (MinGW)/32bit Loop count: 1000000 Parsing: 42.5 xpressive: 13.5003 spirit-quick(static): 0.274027 spirit-quick_new(threadsafe): 0.261029 spirit-grammar(threadsafe/reusable): 0.325813 gcc 4.4.1 (MinGW)/64bit Loop count: 1000000 Parsing: 42.5 xpressive: 10.2381 spirit-quick(static): 0.0868965 spirit-quick_new(threadsafe): 0.0820163 spirit-grammar(threadsafe/reusable): 0.228892 Regards Hartmut
On Sat, Jul 18, 2009 at 7:50 PM, Hartmut Kaiser<hartmut.kaiser@gmail.com> wrote:
OvermindDL1 wrote:
Parsing: 42.5
<snip>
spirit-grammar(threadsafe/reusable): 3.1393
Thank you for pulling this together. Would you mind sharing your test suite?
Er, I meant to attach it, it is attached now. :) It requires Boost trunk, and the timer file hpp I include is part of the Boost.Spirit2.1 examples/test/somewhere_in_there area, but I included it with my cpp file too so you do not need to hunt for it. The defines at the top control what parts to compile or not, 0 to disable compiling for that part, 1 to enable it.
My build is built with Visual Studio 8 (2005) with SP1. Compiler options are basically defaults, except getting rid of the secure crt crap that Microsoft screwed up (enabling that crap slows down Spirit parsers on my system, a *lot*). The exe I built is in the 7zip file attached. As stated, I have heard that Visual Studio handles template stuff like Spirit better then GCC, so I am very curious how GCC's timings on this file would be. There are still more changes to make that I intend to make, but I really want the original code in a way that I can use it. To be honest, I had to change the core::to_number lines (commented out) to boost::lexical_cast (right below the commented version), so the xpressive version could be slightly faster if I actually had the implementation of core::to_number available, and core::to_number was well made. The xpressive code also throws a nice 100 line long warning in my build log, all just about a conversion warning from double to int_64, no clue how to fix that, I do not know xpressive, so I would gladly like it if someone could get rid of that nasty warning in my nice clean buildlog. In my compiler, my Spirit2.1 grammar builds perfectly clean, I would like it if xpressive was the same way.
Here are my results (platform: Windows7, Intel Core Duo(tm) Processor, 2.8GHz, 4GByte RAM), I reduced the number of iterations to 1e6.
VC8SP1/32Bit Loop count: 1000000 Parsing: 42.5 xpressive: 4.53867 spirit-quick(static): 0.213174 spirit-quick_new(threadsafe): 0.255517 spirit-grammar(threadsafe/reusable): 0.228167
VC10 beta/32Bit: Loop count: 1000000 Parsing: 42.5 xpressive: 4.68044 spirit-quick(static): 0.245641 spirit-quick_new(threadsafe): 0.279981 spirit-grammar(threadsafe/reusable): 0.252697
VC10 beta/64Bit: Loop count: 1000000 Parsing: 42.5 xpressive: 3.7877 spirit-quick(static): 0.17625 spirit-quick_new(threadsafe): 0.175377 spirit-grammar(threadsafe/reusable): 0.137707
gcc 4.4.1 (MinGW)/32bit Loop count: 1000000 Parsing: 42.5 xpressive: 13.5003 spirit-quick(static): 0.274027 spirit-quick_new(threadsafe): 0.261029 spirit-grammar(threadsafe/reusable): 0.325813
gcc 4.4.1 (MinGW)/64bit Loop count: 1000000 Parsing: 42.5 xpressive: 10.2381 spirit-quick(static): 0.0868965 spirit-quick_new(threadsafe): 0.0820163 spirit-grammar(threadsafe/reusable): 0.228892
Regards Hartmut
Very nice and detailed, thanks. I just changed the file to use spirit for parsing where I had used lexical_cast got very different timings for xpressive now, so now, with xpressive using a bit of spirit I get: Loop count: 10000000 Parsing: 42.5 xpressive: 15.4841 spirit-quick(static): 3.01117 spirit-quick_new(threadsafe): 3.10548 spirit-grammar(threadsafe/reusable): 3.81694 Vast increase, 3x faster xpressive is now. Also, how do you fix that rather bloody massive warning about double->int64 truncation? I also changed all int64_t to boost::long_long_type since they are the same thing anyway (on 32-bit at least?), as well as it being multi-platform unlike int64_t. My changed file is attached. Do not know if this is considered cheating now that xpressive is using some spirit now. ;-)
OvermindDL1 wrote:
I just changed the file to use spirit for parsing where I had used lexical_cast got very different timings for xpressive now, so now, with xpressive using a bit of spirit I get: Loop count: 10000000 Parsing: 42.5 xpressive: 15.4841 spirit-quick(static): 3.01117 spirit-quick_new(threadsafe): 3.10548 spirit-grammar(threadsafe/reusable): 3.81694
Vast increase, 3x faster xpressive is now. Also, how do you fix that rather bloody massive warning about double->int64 truncation? I also changed all int64_t to boost::long_long_type since they are the same thing anyway (on 32-bit at least?), as well as it being multi-platform unlike int64_t. My changed file is attached. Do not know if this is considered cheating now that xpressive is using some spirit now. ;-)
That one doesn't compile for me. On line 402: boost::spirit::qi::parse(va.begin(), va.end(), boost::spirit::double_[boost::phoenix::ref(value)]); I get no instance of overloaded function "boost::spirit::qi::parse" matches the argument list (and the same on all the similar lines) and indeed I see can't see an appropriate overload in the spirit headers (in boost trunk), but it's hard to be sure since there are so many functions called parse! John Bytheway
On Sun, Jul 19, 2009 at 2:29 AM, John Bytheway<jbytheway+boost@gmail.com> wrote:
OvermindDL1 wrote:
I just changed the file to use spirit for parsing where I had used lexical_cast got very different timings for xpressive now, so now, with xpressive using a bit of spirit I get: Loop count: 10000000 Parsing: 42.5 xpressive: 15.4841 spirit-quick(static): 3.01117 spirit-quick_new(threadsafe): 3.10548 spirit-grammar(threadsafe/reusable): 3.81694
Vast increase, 3x faster xpressive is now. Also, how do you fix that rather bloody massive warning about double->int64 truncation? I also changed all int64_t to boost::long_long_type since they are the same thing anyway (on 32-bit at least?), as well as it being multi-platform unlike int64_t. My changed file is attached. Do not know if this is considered cheating now that xpressive is using some spirit now. ;-)
That one doesn't compile for me. On line 402:
boost::spirit::qi::parse(va.begin(), va.end(), boost::spirit::double_[boost::phoenix::ref(value)]);
I get
no instance of overloaded function "boost::spirit::qi::parse" matches the argument list
(and the same on all the similar lines)
and indeed I see can't see an appropriate overload in the spirit headers (in boost trunk), but it's hard to be sure since there are so many functions called parse!
You are running Boost Trunk? Compiles fine here in MSVC, and I last synced to trunk less then a week ago.
OvermindDL1 wrote:
On Sun, Jul 19, 2009 at 2:29 AM, John Bytheway<jbytheway+boost@gmail.com> wrote:
That one doesn't compile for me. On line 402:
boost::spirit::qi::parse(va.begin(), va.end(), boost::spirit::double_[boost::phoenix::ref(value)]);
I get
no instance of overloaded function "boost::spirit::qi::parse" matches the argument list
You are running Boost Trunk? Compiles fine here in MSVC, and I last synced to trunk less then a week ago.
The problem is that parse takes its first argument by reference, and va.begin() is a temporary. If I take a copy of va.begin() and pass that it works fine. I don't see how this compiled in MSVC (does string::begin() return a non-const reference?), but anyway. Here are the icc results (Intel Core2 Quad 2.83GHz, Gentoo): Loop count: 10000000 Parsing: 42.5 xpressive: 4.28591 spirit-quick(static): 1.4721 spirit-quick_new(threadsafe): 1.46949 spirit-grammar(threadsafe/reusable): 1.59846 and gcc-4.4.0: Loop count: 10000000 Parsing: 42.5 xpressive: 3.62948 spirit-quick(static): 1.02657 spirit-quick_new(threadsafe): 1.00637 spirit-grammar(threadsafe/reusable): 1.01748 gcc 4.3 is still ICEing. John Bytheway

John Bytheway wrote:
string::begin() return a non-const reference?), but anyway. Here are the icc results (Intel Core2 Quad 2.83GHz, Gentoo):
Loop count: 10000000 Parsing: 42.5 xpressive: 4.28591 spirit-quick(static): 1.4721 spirit-quick_new(threadsafe): 1.46949 spirit-grammar(threadsafe/reusable): 1.59846
and gcc-4.4.0:
Loop count: 10000000 Parsing: 42.5 xpressive: 3.62948 spirit-quick(static): 1.02657 spirit-quick_new(threadsafe): 1.00637 spirit-grammar(threadsafe/reusable): 1.01748
gcc 4.3 is still ICEing.
Those are good numbers. It shows that the effect of the virtual function call of the spirit grammar rules is obviated out of existence! For the record, this one shows the xpressive code using spirit numeric parsers to convert the string to numbers, right? Will the original OP please (PLEASE!) come forward and post his original hand-coded program? This is SOOO confusing! Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
Joel de Guzman wrote:
John Bytheway wrote:
string::begin() return a non-const reference?), but anyway. Here are the icc results (Intel Core2 Quad 2.83GHz, Gentoo):
Loop count: 10000000 Parsing: 42.5 xpressive: 4.28591 spirit-quick(static): 1.4721 spirit-quick_new(threadsafe): 1.46949 spirit-grammar(threadsafe/reusable): 1.59846
and gcc-4.4.0:
Loop count: 10000000 Parsing: 42.5 xpressive: 3.62948 spirit-quick(static): 1.02657 spirit-quick_new(threadsafe): 1.00637 spirit-grammar(threadsafe/reusable): 1.01748
gcc 4.3 is still ICEing.
Those are good numbers. It shows that the effect of the virtual function call of the spirit grammar rules is obviated out of existence!
For the record, this one shows the xpressive code using spirit numeric parsers to convert the string to numbers, right?
Correct.
Will the original OP please (PLEASE!) come forward and post his original hand-coded program? This is SOOO confusing!
Well, in case he doesn't, I've thrown together an implementation of core::to_number based on Robert's description of it. I had to guess at the interface, and I didn't verify correctness. I also had to implement two error routines; I made them both "throw 0;". I also tweaked the xpressive code so that it didn't copy the sub_match objects to strings before using qi to parse out the doubles and ints. That sped it up slightly (gcc 4.4.0 again): Loop count: 10000000 Parsing: 42.5 original-custom: 2.08637 xpressive: 2.94329 spirit-quick(static): 1.02784 spirit-quick_new(threadsafe): 1.03306 spirit-grammar(threadsafe/reusable): 1.00213 although I'm slightly concerned with what happened when I changed the string to be parsed: Loop count: 10000000 Parsing: 425/500 original-custom: 1.6307 xpressive: 116.992 spirit-quick(static): 0.552722 spirit-quick_new(threadsafe): 0.53429 spirit-grammar(threadsafe/reusable): 0.680257 Why is the xpressive code so slow here? The parsing is more complex in this case, but I wouldn't think it was this bad! Perhaps I broke it somehow... New code attached (also includes other minor changes I had to make to get things to compile). If someone writes core::numeric_cast then the 'original' xpressive code can be used. John Bytheway
On Sun, Jul 19, 2009 at 1:15 PM, John Bytheway<jbytheway+boost@gmail.com> wrote:
Loop count: 10000000 Parsing: 425/500 original-custom: 1.6307 xpressive: 116.992 spirit-quick(static): 0.552722 spirit-quick_new(threadsafe): 0.53429 spirit-grammar(threadsafe/reusable): 0.680257
First of all, from what I read of the grammar, "425/500" is not a valid 'price'. However, something like "0 425/500" would be, and from what I read of all parsers, none would parse your format, so I bet if you checked the return value of my parse function, the return would be false, indicating it failed parsing. I would wager that the xpressive probably is dieing because it does not know how to handle that value.

Hey, John. Your benchmark results make a very interesting addition to the discussion. Perhaps I can clear something up for you: On Sun, Jul 19, 2009 at 02:46:33PM +0100, John Bytheway wrote:
The problem is that parse takes its first argument by reference, and va.begin() is a temporary. If I take a copy of va.begin() and pass that it works fine. I don't see how this compiled in MSVC (does string::begin() return a non-const reference?), but anyway.
MSVC allows binding temporaries to non-const reference arguments, as an extension. It's sort of useful, but it's also sort of annoying - sometimes both at once. -- "He is strongly identified with rebels, you see, and very popular with rabbles. They will follow him and he will fight to the last drop of their blood." Chris Boucher, Blake's 7 D13 ‘Blake’ http://surreal.istic.org/ The Answer of the Oracle Is Always Death.
OvermindDL1 wrote:
I just changed the file to use spirit for parsing where I had used lexical_cast got very different timings for xpressive now, so now, with xpressive using a bit of spirit I get: Loop count: 10000000 Parsing: 42.5 xpressive: 15.4841 spirit-quick(static): 3.01117 spirit-quick_new(threadsafe): 3.10548 spirit-grammar(threadsafe/reusable): 3.81694
Vast increase, 3x faster xpressive is now. Also, how do you fix that rather bloody massive warning about double->int64 truncation? I also changed all int64_t to boost::long_long_type since they are the same thing anyway (on 32-bit at least?), as well as it being multi-platform unlike int64_t. My changed file is attached. Do not know if this is considered cheating now that xpressive is using some spirit now. ;-)
This is somewhat cheating. We've tuned the numeric parsers of Spirit with TMP tricks, loop unrolling, etc. Those are very finely tuned numeric parsers you see there that beats the fastest C code such as strtol and atoi. The following benchmarks reveal 2X+ speed against low level strtol and atoi (attached). I am getting: atoi: 0.82528 [s] strtol: 0.792227 [s] int_: 0.358016 [s] The first and second are the low-level C routines. The third is Spirit's int_ parser. I need not mention that the C routines only accept C strings while the Spirit int_ parser can accept any forward iterator. So, in a sense, we're comparing apples and oranges. But this goes to show that you can write highly optimized code in generic C++. Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net /*============================================================================= Copyright (c) 2001-2009 Joel de Guzman Distributed under the Boost Software License, Version 1.0. (See accompanying file LICENSE_1_0.txt or copy at http://www.boost.org/LICENSE_1_0.txt) =============================================================================*/ #if defined(BOOST_MSVC) #pragma inline_depth(255) #pragma inline_recursion(on) #define _SECURE_SCL 0 #endif // defined(BOOST_MSVC) #include "../high_resolution_timer.hpp" #include <boost/spirit/include/qi.hpp> #include <boost/lexical_cast.hpp> #include <climits> #include <cstdlib> #include <string> #include <vector> #define MAX_ITERATION 10000000 void check(int a, int b) { if (a != b) { std::cout << "Parse Error" << std::endl; abort(); } } int main() { namespace qi = boost::spirit::qi; using qi::int_; std::cout << "initializing input strings..." << std::endl; std::vector<int> src(MAX_ITERATION); std::vector<std::string> src_str(MAX_ITERATION); for (int i = 0; i < MAX_ITERATION; ++i) { src[i] = std::rand() * std::rand(); src_str[i] = boost::lexical_cast<std::string>(src[i]); } std::vector<int> v(MAX_ITERATION); // test the C libraries atoi function (the most low level function for // string conversion available) { util::high_resolution_timer t; for (int i = 0; i < MAX_ITERATION; ++i) { v[i] = atoi(src_str[i].c_str()); } std::cout << "atoi: " << t.elapsed() << " [s]" << std::flush << std::endl; for (int i = 0; i < MAX_ITERATION; ++i) { check(v[i], src[i]); } } // test the C libraries strtol function (the most low level function for // string conversion available) { util::high_resolution_timer t; for (int i = 0; i < MAX_ITERATION; ++i) { v[i] = strtol(src_str[i].c_str(), 0, 10); } std::cout << "strtol: " << t.elapsed() << " [s]" << std::flush << std::endl; for (int i = 0; i < MAX_ITERATION; ++i) { check(v[i], src[i]); } } // test the Qi int_ parser routines { std::vector<char const*> f(MAX_ITERATION); std::vector<char const*> l(MAX_ITERATION); // get the first/last iterators for (int i = 0; i < MAX_ITERATION; ++i) { f[i] = src_str[i].c_str(); l[i] = f[i]; while (*l[i]) l[i]++; } util::high_resolution_timer t; for (int i = 0; i < MAX_ITERATION; ++i) { qi::parse(f[i], l[i], int_, v[i]); } std::cout << "int_: " << t.elapsed() << " [s]" << std::flush << std::endl; for (int i = 0; i < MAX_ITERATION; ++i) { check(v[i], src[i]); } } return 0; }
Joel de Guzman wrote:
OvermindDL1 wrote:
I just changed the file to use spirit for parsing where I had used lexical_cast got very different timings for xpressive now, so now, with xpressive using a bit of spirit I get: Loop count: 10000000 Parsing: 42.5 xpressive: 15.4841 spirit-quick(static): 3.01117 spirit-quick_new(threadsafe): 3.10548 spirit-grammar(threadsafe/reusable): 3.81694
Vast increase, 3x faster xpressive is now. Also, how do you fix that rather bloody massive warning about double->int64 truncation? I also changed all int64_t to boost::long_long_type since they are the same thing anyway (on 32-bit at least?), as well as it being multi-platform unlike int64_t. My changed file is attached. Do not know if this is considered cheating now that xpressive is using some spirit now. ;-)
This is somewhat cheating. We've tuned the numeric parsers of Spirit with TMP tricks, loop unrolling, etc. Those are very finely tuned numeric parsers you see there that beats the fastest C code such as strtol and atoi. The following benchmarks reveal 2X+ speed against low level strtol and atoi (attached). I am getting:
atoi: 0.82528 [s] strtol: 0.792227 [s] int_: 0.358016 [s]
The first and second are the low-level C routines. The third is Spirit's int_ parser. I need not mention that the C routines only accept C strings while the Spirit int_ parser can accept any forward iterator. So, in a sense, we're comparing apples and oranges. But this goes to show that you can write highly optimized code in generic C++.
Oh, BTW, that's MSVC 9, on a Core 2 Duo 2.4 Ghz, 3MB RAM. Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net

This is somewhat cheating. We've tuned the numeric parsers of Spirit with TMP tricks, loop unrolling, etc. Those are very finely tuned numeric parsers you see there that beats the fastest C code such as strtol and atoi. The following benchmarks reveal 2X+ speed against low level strtol and atoi (attached). I am getting:
atoi: 0.82528 [s] strtol: 0.792227 [s] int_: 0.358016 [s]
The first and second are the low-level C routines. The third is Spirit's int_ parser. I need not mention that the C routines only accept C strings while the Spirit int_ parser can accept any forward iterator. So, in a sense, we're comparing apples and oranges. But this goes to show that you can write highly optimized code in generic C++.
Dear Joel, Would you mind trying out these examples with my timer? I'd like to see if it gives sensible answers for other people's code on other people's machines. Attached is a reworking of your testbed code using my timer which can be obtained from boost vault, http://tinyurl.com/ksbukc I haven't been able to try compiling the attached modification to your code myself as I don't have the boost spirit libraries. Even if I did it still wouldn't be your machine! Since I can't compile it there *will* be some errors! The ugly global variables are sadly an unavoidable side effect at the moment. I have pared down the number of iterations quite significantly. The generic_timer makes repeated calls to the functions under test - as many as necessary to 'get the job done' - so there's no need to have large run-times in order to effectively get an average time. Cheers, -ed
Edward Grace wrote:
This is somewhat cheating. We've tuned the numeric parsers of Spirit with TMP tricks, loop unrolling, etc. Those are very finely tuned numeric parsers you see there that beats the fastest C code such as strtol and atoi. The following benchmarks reveal 2X+ speed against low level strtol and atoi (attached). I am getting:
atoi: 0.82528 [s] strtol: 0.792227 [s] int_: 0.358016 [s]
The first and second are the low-level C routines. The third is Spirit's int_ parser. I need not mention that the C routines only accept C strings while the Spirit int_ parser can accept any forward iterator. So, in a sense, we're comparing apples and oranges. But this goes to show that you can write highly optimized code in generic C++.
Dear Joel,
Would you mind trying out these examples with my timer? I'd like to see if it gives sensible answers for other people's code on other people's machines. Attached is a reworking of your testbed code using my timer which can be obtained from boost vault,
Hi Edward, I tried a quick shot at it. There are compilation errors indeed. Please try to fix the errors first (*). You can get Spirit by getting the Boost trunk off SVN. (*) Also, please make sure you try it on Windows too. E.g. <sys/time.h> is non-standard, AFAIK. My main compiler is VC9. Your library is intended to be cross platform, right? Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
There are compilation errors indeed.
If you've tried building example_timer.cpp can you post up the errors you're getting? I don't have access to a Windows machine.
Please try to fix the errors first (*). You can get Spirit by getting the Boost trunk off SVN.
Ok, will do.
(*) Also, please make sure you try it on Windows too. E.g. <sys/ time.h> is non-standard, AFAIK.
No can do, I don't have access to a windows machine. The <sys/time.h> is just for gettimeofday(). The actual generic_timer is chronometer agnostic (or should be) so any function you have to get a given high precision time should just 'go'. Perhaps if you post up your timer I can try that - or at least make an interface that will work.
My main compiler is VC9. Your library is intended to be cross platform, right?
Indeed, *intended* is the operative word. I've only tried it on OS X and Linux. -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Edward Grace wrote:
The actual generic_timer is chronometer agnostic (or should be) so any function you have to get a given high precision time should just 'go'. Perhaps if you post up your timer I can try that - or at least make an interface that will work.
I believe Overmind posted that sometime ago included in the 7Z file "Spirit_Price_Code1.7z" Cheers, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
On 19 Jul 2009, at 14:34, Joel de Guzman wrote:
Edward Grace wrote:
The actual generic_timer is chronometer agnostic (or should be) so any function you have to get a given high precision time should just 'go'. Perhaps if you post up your timer I can try that - or at least make an interface that will work.
I believe Overmind posted that sometime ago included in the 7Z file "Spirit_Price_Code1.7z"
Hi Joel, It appears to be in your SVN tree - however it doesn't really help. It seems to be unapologetically Windows only. I tried to compile your example but was unsure of what to pull from the SVN tree. Is it Spirit2? Could you please supply the precise svn repository? I tried these two: svn checkout https://spirit.svn.sourceforge.net/svnroot/spirit/ trunk/final/boost/ svn checkout https://spirit.svn.sourceforge.net/svnroot/spirit/ trunk/Spirit2x/ but wasn't sure which (if anything) was correct, so didn't know if the errors I was getting were because I was looking at the wrong thing or doing something dim. Regarding a cross-platform high frequency timer, I have uploaded "cycle.h" from the FFTW project to the Boost Vault, http://tinyurl.com/maylnc This appears to support a wide variety of platforms and compilers in a transparent manner. You end up with a call to a function of the form. ticks getticks(); on whatever platform you are using (thanks to some macro magic). It should work just fine with Windows and MSVC. The following #include "cycle.h" #include <iostream> int main() { std::cout << getticks() << std::endl; return 0; } should spit out a large number, usually the number of clock cycles since the CPU started. $ g++-4 -ansi -pedantic test.cpp In file included from test.cpp:3: cycle.h:172: warning: ISO C++ 1998 does not support 'long long' $ ./a.out 32572590328070 If you could confirm that the above snippet works for you and the appropriate SVN repository I'll have a bash at that timing again. After all, if it's written in a standards compliant platform agnostic manner if it works for me it's got to work for you ---------- right? ;-) Cheers, -ed
The actual generic_timer is chronometer agnostic (or should be) so any function you have to get a given high precision time should just 'go'. Perhaps if you post up your timer I can try that - or at least make an interface that will work.
I believe Overmind posted that sometime ago included in the 7Z file "Spirit_Price_Code1.7z"
Hi Joel,
It appears to be in your SVN tree - however it doesn't really help. It seems to be unapologetically Windows only.
Nope, the high_resolution timer components is cross platform. I tested it on Windows, Linux, and MacOS.
I tried to compile your example but was unsure of what to pull from the SVN tree. Is it Spirit2? Could you please supply the precise svn repository? I tried these two:
svn checkout https://spirit.svn.sourceforge.net/svnroot/spirit/ trunk/final/boost/ svn checkout https://spirit.svn.sourceforge.net/svnroot/spirit/ trunk/Spirit2x/
but wasn't sure which (if anything) was correct, so didn't know if the errors I was getting were because I was looking at the wrong thing or doing something dim.
Please use Boost SVN trunk here: https://svn.boost.org/svn/boost/trunk/boost/spirit https://svn.boost.org/svn/boost/trunk/libs/spirit and make sure to put these directories in front of your normal Boost installation (V1.37 is required at minimum). The high_resultion_timer.hpp is here: https://svn.boost.org/svn/boost/trunk/libs/spirit/benchmarks/high_resolution _timer.hpp HTH Regards Hartmut
Dear Hartmut,
It appears to be in your SVN tree - however it doesn't really help. It seems to be unapologetically Windows only.
Nope, the high_resolution timer components is cross platform. I tested it on Windows, Linux, and MacOS.
This is what I found, when I went searching https://spirit.svn.sourceforge.net/svnroot/spirit/trunk/final/boost/ high_resolution_timer.hpp clearly I was looking in the wrong place! Thanks. -ed
Please use Boost SVN trunk here:
https://svn.boost.org/svn/boost/trunk/boost/spirit https://svn.boost.org/svn/boost/trunk/libs/spirit
and make sure to put these directories in front of your normal Boost installation (V1.37 is required at minimum). The high_resultion_timer.hpp is here:
https://svn.boost.org/svn/boost/trunk/libs/spirit/benchmarks/ high_resolution _timer.hpp
Hi Hartmut, So, I did the following and placed them in different directories. $ svn checkout https://svn.boost.org/svn/boost/trunk/boost/spirit $ svn checkout https://svn.boost.org/svn/boost/trunk/libs/spirit In both cases it states "Checked out revision 55030". And shoved high_resolution_timer.hpp in the appropriate place. After modifying "uint_parser.cpp" to add #include <iostream> I get the following error: $ g++-4 -I ~/Desktop/boost_spirit/ -I ~Desktop/libs_spirit/ -I ~/ Desktop/boost_1_39_0 -o uint_parser uint_parser.cpp uint_parser.cpp: In function 'int main()': uint_parser.cpp:37: error: 'qi::int_' has not been declared uint_parser.cpp:104: error: 'int_' was not declared in this scope which seems fairly fundamental. Do I have the correct revision of Spirit? Any suggestions? -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Please use Boost SVN trunk here:
https://svn.boost.org/svn/boost/trunk/boost/spirit https://svn.boost.org/svn/boost/trunk/libs/spirit
and make sure to put these directories in front of your normal Boost installation (V1.37 is required at minimum). The high_resultion_timer.hpp is here:
https://svn.boost.org/svn/boost/trunk/libs/spirit/benchmarks/ high_resolution _timer.hpp
Hi Hartmut,
So,
I did the following and placed them in different directories. $ svn checkout https://svn.boost.org/svn/boost/trunk/boost/spirit $ svn checkout https://svn.boost.org/svn/boost/trunk/libs/spirit
In both cases it states "Checked out revision 55030".
And shoved high_resolution_timer.hpp in the appropriate place.
After modifying "uint_parser.cpp" to add
#include <iostream>
I get the following error:
$ g++-4 -I ~/Desktop/boost_spirit/ -I ~Desktop/libs_spirit/ -I ~/ Desktop/boost_1_39_0 -o uint_parser uint_parser.cpp
You don't need to add the libs/spirit directory to your sinclude path. That's just where the examples, tests and documentation resides. Sorry, I should have been more explicit.
uint_parser.cpp: In function 'int main()': uint_parser.cpp:37: error: 'qi::int_' has not been declared uint_parser.cpp:104: error: 'int_' was not declared in this scope
which seems fairly fundamental.
I certainly can only guess what happens there, but I think the checkout svn checkout https://svn.boost.org/svn/boost/trunk/boost/spirit creates a directory ./spirit. Could you try moving this into a subdirectory boost, additionally. The final directory structure must be: $SPIRIT21_ROOT/boost/spirit (/include/...) And the -I $SPIRIT21_ROOT needs to be added to the compiler command line. All spirit headers are included as #include <boost/spirit/include/...> that means you need to tell the compiler the base directory the 'boost/spirit/...' is in.
Do I have the correct revision of Spirit? Any suggestions?
Seems to be the correct revision. HTH Regards Hartmut
creates a directory ./spirit. Could you try moving this into a subdirectory boost, additionally. The final directory structure must be:
$SPIRIT21_ROOT/boost/spirit (/include/...)
And the -I $SPIRIT21_ROOT needs to be added to the compiler command line. All spirit headers are included as
#include <boost/spirit/include/...>
that means you need to tell the compiler the base directory the 'boost/spirit/...' is in.
Bingo: Just a question of getting everything in the right place. $ g++-4 -I spirit21_root -I $HOME/Desktop/boost_1_39_0 -o uint_parser uint_parser.cpp $ ./uint_parser initializing input strings... atoi: 1.42 [s] strtol: 1.36 [s] int_: 6.53 [s] Clearly I need a faster laptop! ;-) -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Hi Joel,
I tried a quick shot at it. There are compilation errors indeed. Please try to fix the errors first (*). You can get Spirit by getting the Boost trunk off SVN.
Ok, once I knew where to look it was easy to get sorted. I've placed my example - based on your code - in the vault. A typical example using a much smaller buffer (1000) vs (1000000) by altering what you called MAX_ITERATION yields the following eye- popping stats: $ time ./ejg_uint_parser initializing input strings... Calibrating overhead......done Timer overhead (t_c) ~= : 0.000195267 Jitter ~= : 2.02505e-14 qi_parse vs atoi : 1656.34 1661.63 1683.63% faster. qi_parse vs strtol : 1521.71 1534.68 1547.75% faster. strtol vs atoi : 4.17706 8.94977 10.1224% faster. qi_parse vs qi_parse : -6.26613 -3.19258 -0.0182475% faster. Checking that the results are correct... atoi is behaving itself! strtol is behaving itself! qi is behaving itself! All done! real 7m37.575s user 6m47.978s sys 0m29.151s N.B. The final timing of qi_parse against itself is zero percent within the nominal precision. At first I thought the 1000% speedup of qi_parse was a fake due to some compiler shenanigans. Now I don't think so. I think it really is that much faster for small buffers! Note that this timing experiment took ~6mins. Using cycle.h: This was all compiled with: g++-4 -ansi -pedantic -DNDEBUG -O4 -I. -I spirit21_root -I $HOME/ Desktop/boost_1_39_0 -o ejg_uint_parser ejg_uint_parser.cpp Where spirit21_root is the spirit library I downloaded earlier. It passes the -ansi -pedantic test and is optimized to the max. Repeating this with getticks() from cycle.h instead of the boost based timer we get: $ time ./ejg_uint_parser initializing input strings... Calibrating overhead......done Timer overhead (t_c) ~= : 145.797 Jitter ~= : 5.31361 qi_parse vs atoi : 1672.05 1674.47 1677.3% faster. qi_parse vs strtol : 1543.36 1547.38 1555.7% faster. strtol vs atoi : 7.39392 7.79078 7.84302% faster. qi_parse vs qi_parse : 0 0 0% faster. Checking that the results are correct... atoi is behaving itself! strtol is behaving itself! qi is behaving itself! All done! real 0m25.254s user 0m22.124s sys 0m2.496s Same results - actually better since the experiment is quicker and the 95th percentile range is therefore narrower. Obviously I'm suspicious that something funny's going on - would you expect it to be capable of being ~10x faster?
(*) Also, please make sure you try it on Windows too. E.g. <sys/ time.h> is non-standard, AFAIK. My main compiler is VC9. Your library is intended to be cross platform, right?
Can you try compiling ejg_uint_parser.cpp? http://tinyurl.com/klh2hc Like I say it's -ansi -pedantic, so 'gotta work'! ;-) -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
On Sun, Jul 19, 2009 at 5:15 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Can you try compiling ejg_uint_parser.cpp?
No, because your tinyurl link goes directly to the root of the vault, not any file, and could not find the file when I placed the name in the search. :)
On 20 Jul 2009, at 00:20, OvermindDL1 wrote:
On Sun, Jul 19, 2009 at 5:15 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Can you try compiling ejg_uint_parser.cpp?
No, because your tinyurl link goes directly to the root of the vault, not any file, and could not find the file when I placed the name in the search. :)
As the grate [sic] mind Homer would have said "Doh" Try this: http://tinyurl.com/lro5ok file "ejg_uint_parser.cpp" -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
On Sun, Jul 19, 2009 at 5:24 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
On 20 Jul 2009, at 00:20, OvermindDL1 wrote:
On Sun, Jul 19, 2009 at 5:15 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Can you try compiling ejg_uint_parser.cpp?
No, because your tinyurl link goes directly to the root of the vault, not any file, and could not find the file when I placed the name in the search. :)
As the grate [sic] mind Homer would have said
"Doh"
Try this:
file "ejg_uint_parser.cpp"
Okay, compiled the code, got this: 1>------ Build started: Project: ejg_uint_parser_timing, Configuration: Release Win32 ------ 1>Compiling... 1>ejg_uint_parser.cpp 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.hpp(417) : error C2220: warning treated as error - no 'object' file generated 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.hpp(417) : warning C4244: 'return' : conversion from 'double' to 'unsigned int', possible loss of data 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.cpp(28) : error C2039: 'ptr_fun' : is not a member of 'std' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.cpp(28) : error C2873: 'ptr_fun' : symbol cannot be used in a using-declaration 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(273) : warning C4003: not enough actual parameters for macro 'max' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(384) : warning C4003: not enough actual parameters for macro 'min' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(385) : warning C4003: not enough actual parameters for macro 'max' 1>using native typeof 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.hpp(1018) : warning C4512: 'ejg::generic_timer<ticks>' : assignment operator could not be generated 1> with 1> [ 1> ticks=ticks 1> ] 1> .\ejg_uint_parser.cpp(133) : see reference to class template instantiation 'ejg::generic_timer<ticks>' being compiled 1> with 1> [ 1> ticks=ticks 1> ] 1>Build Time 0:09 1>Build log was saved at "file://r:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\Release\BuildLog.htm" 1>ejg_uint_parser_timing - 3 error(s), 5 warning(s) So yes, this is very much not usable for me, but there is your buildlog anyway. :)
On Sun, Jul 19, 2009 at 6:13 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Sun, Jul 19, 2009 at 5:24 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
On 20 Jul 2009, at 00:20, OvermindDL1 wrote:
On Sun, Jul 19, 2009 at 5:15 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Can you try compiling ejg_uint_parser.cpp?
No, because your tinyurl link goes directly to the root of the vault, not any file, and could not find the file when I placed the name in the search. :)
As the grate [sic] mind Homer would have said
"Doh"
Try this:
file "ejg_uint_parser.cpp"
Okay, compiled the code, got this: 1>------ Build started: Project: ejg_uint_parser_timing, Configuration: Release Win32 ------ 1>Compiling... 1>ejg_uint_parser.cpp 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.hpp(417) : error C2220: warning treated as error - no 'object' file generated 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.hpp(417) : warning C4244: 'return' : conversion from 'double' to 'unsigned int', possible loss of data 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.cpp(28) : error C2039: 'ptr_fun' : is not a member of 'std' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.cpp(28) : error C2873: 'ptr_fun' : symbol cannot be used in a using-declaration 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(273) : warning C4003: not enough actual parameters for macro 'max' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(384) : warning C4003: not enough actual parameters for macro 'min' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(385) : warning C4003: not enough actual parameters for macro 'max' 1>using native typeof 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.hpp(1018) : warning C4512: 'ejg::generic_timer<ticks>' : assignment operator could not be generated 1> with 1> [ 1> ticks=ticks 1> ] 1> .\ejg_uint_parser.cpp(133) : see reference to class template instantiation 'ejg::generic_timer<ticks>' being compiled 1> with 1> [ 1> ticks=ticks 1> ] 1>Build Time 0:09 1>Build log was saved at "file://r:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\Release\BuildLog.htm" 1>ejg_uint_parser_timing - 3 error(s), 5 warning(s)
So yes, this is very much not usable for me, but there is your buildlog anyway. :)
Er, and yes, this is with MSVC8(SP1) on Windows XP, using Boost Trunk from about a week ago and your vault files.
On Sun, Jul 19, 2009 at 6:13 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Sun, Jul 19, 2009 at 6:13 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Sun, Jul 19, 2009 at 5:24 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
On 20 Jul 2009, at 00:20, OvermindDL1 wrote:
On Sun, Jul 19, 2009 at 5:15 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Can you try compiling ejg_uint_parser.cpp?
No, because your tinyurl link goes directly to the root of the vault, not any file, and could not find the file when I placed the name in the search. :)
As the grate [sic] mind Homer would have said
"Doh"
Try this:
file "ejg_uint_parser.cpp"
Okay, compiled the code, got this: 1>------ Build started: Project: ejg_uint_parser_timing, Configuration: Release Win32 ------ 1>Compiling... 1>ejg_uint_parser.cpp 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.hpp(417) : error C2220: warning treated as error - no 'object' file generated 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.hpp(417) : warning C4244: 'return' : conversion from 'double' to 'unsigned int', possible loss of data 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.cpp(28) : error C2039: 'ptr_fun' : is not a member of 'std' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.cpp(28) : error C2873: 'ptr_fun' : symbol cannot be used in a using-declaration 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(273) : warning C4003: not enough actual parameters for macro 'max' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(384) : warning C4003: not enough actual parameters for macro 'min' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(385) : warning C4003: not enough actual parameters for macro 'max' 1>using native typeof 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.hpp(1018) : warning C4512: 'ejg::generic_timer<ticks>' : assignment operator could not be generated 1> with 1> [ 1> ticks=ticks 1> ] 1> .\ejg_uint_parser.cpp(133) : see reference to class template instantiation 'ejg::generic_timer<ticks>' being compiled 1> with 1> [ 1> ticks=ticks 1> ] 1>Build Time 0:09 1>Build log was saved at "file://r:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\Release\BuildLog.htm" 1>ejg_uint_parser_timing - 3 error(s), 5 warning(s)
So yes, this is very much not usable for me, but there is your buildlog anyway. :)
Er, and yes, this is with MSVC8(SP1) on Windows XP, using Boost Trunk from about a week ago and your vault files.
The main error there, the ptr_fun, you did not include <functional>.
On Sun, Jul 19, 2009 at 6:19 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Sun, Jul 19, 2009 at 6:13 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Sun, Jul 19, 2009 at 6:13 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Sun, Jul 19, 2009 at 5:24 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
On 20 Jul 2009, at 00:20, OvermindDL1 wrote:
On Sun, Jul 19, 2009 at 5:15 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Can you try compiling ejg_uint_parser.cpp?
No, because your tinyurl link goes directly to the root of the vault, not any file, and could not find the file when I placed the name in the search. :)
As the grate [sic] mind Homer would have said
"Doh"
Try this:
file "ejg_uint_parser.cpp"
Okay, compiled the code, got this: 1>------ Build started: Project: ejg_uint_parser_timing, Configuration: Release Win32 ------ 1>Compiling... 1>ejg_uint_parser.cpp 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.hpp(417) : error C2220: warning treated as error - no 'object' file generated 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.hpp(417) : warning C4244: 'return' : conversion from 'double' to 'unsigned int', possible loss of data 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.cpp(28) : error C2039: 'ptr_fun' : is not a member of 'std' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/statistics/statistics.cpp(28) : error C2873: 'ptr_fun' : symbol cannot be used in a using-declaration 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(273) : warning C4003: not enough actual parameters for macro 'max' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(384) : warning C4003: not enough actual parameters for macro 'min' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(385) : warning C4003: not enough actual parameters for macro 'max' 1>using native typeof 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.hpp(1018) : warning C4512: 'ejg::generic_timer<ticks>' : assignment operator could not be generated 1> with 1> [ 1> ticks=ticks 1> ] 1> .\ejg_uint_parser.cpp(133) : see reference to class template instantiation 'ejg::generic_timer<ticks>' being compiled 1> with 1> [ 1> ticks=ticks 1> ] 1>Build Time 0:09 1>Build log was saved at "file://r:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\Release\BuildLog.htm" 1>ejg_uint_parser_timing - 3 error(s), 5 warning(s)
So yes, this is very much not usable for me, but there is your buildlog anyway. :)
Er, and yes, this is with MSVC8(SP1) on Windows XP, using Boost Trunk from about a week ago and your vault files.
The main error there, the ptr_fun, you did not include <functional>.
Sorry for the noise, but the only error I could not get rid of with single-line edits to your files is: 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(117) : error C2676: binary '-' : 'ticks' does not define this operator or a conversion to a type acceptable to the predefined operator 1> R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(109) : while compiling class template member function 'void ejg::generic_timer<ticks>::calibrate_seconds(void)' 1> with 1> [ 1> ticks=ticks 1> ] 1> .\ejg_uint_parser.cpp(133) : see reference to class template instantiation 'ejg::generic_timer<ticks>' being compiled 1> with 1> [ 1> ticks=ticks 1> ]
Sorry for the noise, but the only error I could not get rid of with single-line edits to your files is: 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/timer.cpp(117) : error C2676: binary '-' : 'ticks' does not define this operator or a conversion to a type acceptable to the predefined operator
The while statement? chrono_start = chrono(); while (chrono_wall()-chrono_wall_start < chrono_wall_scale*4); chrono_end = chrono(); Hmm. Depending on what the type of 'ticks' from cycle.h is (that's what you're using right) that should just be a large integer type. Perhaps try with the util::high_resolution_timer, which is of type double(). Otherwise do you think the compiler is getting confused between the name of the template parameter 'ticks' and the type 'ticks'? -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Hi OverminDL1,
Sorry for the noise, but the only error I could not get rid of with single-line edits to your files is: 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/timer.cpp(117) : error C2676: binary '-' : 'ticks' does not define this operator or a conversion to a type acceptable to the predefined operator 1> R:\Programming_Projects\Spirit_Price \ejg_uint_parser_timing\other_includes\ejg/timer.cpp(109) : while compiling class template member function 'void ejg::generic_timer<ticks>::calibrate_seconds(void)'
A bit of a stab in the dark, perhaps change the region around timer.cpp(109) to chrono_start = chrono(); while ( double( chrono_wall() - chrono_wall_start ) < chrono_wall_scale*4.0); chrono_end = chrono(); I'm now doubly confused as it appears to be complaining about the return type of std::clock, (the default wall-clock timer). Maybe I can get my hands on a windows machine and compiler tomorrow.... -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Edward Grace wrote:
Hi OverminDL1,
Sorry for the noise, but the only error I could not get rid of with single-line edits to your files is: 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(117)
: error C2676: binary '-' : 'ticks' does not define this operator or a conversion to a type acceptable to the predefined operator 1> R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(109)
: while compiling class template member function 'void ejg::generic_timer<ticks>::calibrate_seconds(void)'
A bit of a stab in the dark, perhaps change the region around timer.cpp(109) to
chrono_start = chrono(); while ( double( chrono_wall() - chrono_wall_start ) < chrono_wall_scale*4.0); chrono_end = chrono();
I'm now doubly confused as it appears to be complaining about the return type of std::clock, (the default wall-clock timer). Maybe I can get my hands on a windows machine and compiler tomorrow....
Edward, just a compliment (for now): what you are doing is cool! I'm starting to be an eager supporter. Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
On Sun, Jul 19, 2009 at 7:12 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
And yea yea, I would like to use GCC to compile, but I currently have sold my soul to the Visual Assist plugin for Visual Studio. If any IDE
IDE? Whassat? What's wrong with........
....emacs? ;-)
Heh, believe me, it does no where near. Visual Assist parses out the files, it know what are macros, templates, everything, it guesses most of the code that I am writing for me, it literally puts in probably 80% of what I type, it is intelligent and very well made (once you know how it thinks). Emacs could never compare as-is. Believe me, once you use it for a month, you would be addicted. Most, if not all major programming companies use it. :p On Sun, Jul 19, 2009 at 7:12 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
(back on topic now)
Sorry for the noise, but the only error I could not get rid of with single-line edits to your files is:
1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(117) : error C2676: binary '-' : 'ticks' does not define this operator or a conversion to a type acceptable to the predefined operator
The while statement?
chrono_start = chrono(); while (chrono_wall()-chrono_wall_start < chrono_wall_scale*4); chrono_end = chrono();
Hmm. Depending on what the type of 'ticks' from cycle.h is (that's what you're using right) that should just be a large integer type. Perhaps try with the util::high_resolution_timer, which is of type double(). According to Visual Assist, ticks is of type LARGE_INTEGER, a union type with 4 parts and a max size of 64-bits, it has no operator- defined, hence you would need to reference an internal part, it looks
Er, yes, right... On Sun, Jul 19, 2009 at 7:10 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote: like QuadPart (like chrono_wall().QuadPart) would work, but that does not fit into your design. I added this to the proper place in the cycle.h file: LARGE_INTEGER operator-(LARGE_INTEGER l, LARGE_INTEGER r) { LARGE_INTEGER res; res.QuadPart = l.QuadPart - r.QuadPart; return res; } Now it says: 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(117) : error C2440: '<function-style-cast>' : cannot convert from 'LARGE_INTEGER' to 'double' 1> No user-defined-conversion operator available that can perform this conversion, or the operator cannot be called 1> R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(109) : while compiling class template member function 'void ejg::generic_timer<ticks>::calibrate_seconds(void)' 1> with 1> [ 1> ticks=ticks 1> ] 1> .\ejg_uint_parser.cpp(133) : see reference to class template instantiation 'ejg::generic_timer<ticks>' being compiled 1> with 1> [ 1> ticks=ticks 1> ] 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(239) : warning C4267: '=' : conversion from 'size_t' to 'unsigned int', possible loss of data 1> .\ejg_uint_parser.cpp(154) : see reference to function template instantiation 'void ejg::generic_timer<ticks>::measure_percentage_speedup<void(__cdecl *)(void),void(__cdecl *)(void)>(_OperationA,_OperationB,double &,double &,double &)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _OperationA=void (__cdecl *)(void), 1> _OperationB=void (__cdecl *)(void) 1> ] 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(246) : warning C4267: '=' : conversion from 'size_t' to 'unsigned int', possible loss of data So the union has no conversion to double, of course. Trying What do you want me to do with util::high_resolution_timer? On Sun, Jul 19, 2009 at 7:10 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Otherwise do you think the compiler is getting confused between the name of the template parameter 'ticks' and the type 'ticks'?
Hmm, do not know, I never duplicate names like that so have not run into that... On Sun, Jul 19, 2009 at 9:51 PM, Joel de Guzman<joel@boost-consulting.com> wrote:
Edward, just a compliment (for now): what you are doing is cool! I'm starting to be an eager supporter.
I have to say that I like the design of your timer library as well, looks to be very useful. :)
Hmm. Depending on what the type of 'ticks' from cycle.h is (that's what you're using right) that should just be a large integer type. Perhaps try with the util::high_resolution_timer, which is of type double(). According to Visual Assist, ticks is of type LARGE_INTEGER, a union type with 4 parts and a max size of 64-bits, it has no operator- defined, hence you would need to reference an internal part, it looks like QuadPart (like chrono_wall().QuadPart) would work, but that does not fit into your design. I added this to the proper place in the cycle.h file: LARGE_INTEGER operator-(LARGE_INTEGER l, LARGE_INTEGER r) { LARGE_INTEGER res; res.QuadPart = l.QuadPart - r.QuadPart; return res; }
Now it says: 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/timer.cpp(117) : error C2440: '<function-style-cast>' : cannot convert from 'LARGE_INTEGER' to 'double' 1> No user-defined-conversion operator available that can perform this conversion, or the operator cannot be called 1> R:\Programming_Projects\Spirit_Price \ejg_uint_parser_timing\other_includes\ejg/timer.cpp(109) : while compiling class template member function 'void ejg::generic_timer<ticks>::calibrate_seconds(void)' 1> with 1> [ 1> ticks=ticks 1> ] 1> .\ejg_uint_parser.cpp(133) : see reference to class template instantiation 'ejg::generic_timer<ticks>' being compiled 1> with 1> [ 1> ticks=ticks 1> ] 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/timer.cpp(239) : warning C4267: '=' : conversion from 'size_t' to 'unsigned int', possible loss of data 1> .\ejg_uint_parser.cpp(154) : see reference to function template instantiation 'void ejg::generic_timer<ticks>::measure_percentage_speedup<void(__cdecl *)(void),void(__cdecl *)(void)>(_OperationA,_OperationB,double &,double &,double &)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _OperationA=void (__cdecl *)(void), 1> _OperationB=void (__cdecl *)(void) 1> ] 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/timer.cpp(246) : warning C4267: '=' : conversion from 'size_t' to 'unsigned int', possible loss of data
So the union has no conversion to double, of course. Trying
Ahah. Perhaps that's why cycle.h has a macro called 'elapsed', designed to take the difference between two numbers with these types. Clearly this is going to be tougher than I thought. I originally avoided making the list of stored time differences a concrete type such as double, now it looks like I might have to. Otherwise it will require sticking lots of extra cruft in as template arguments (a function for taking differences of times for example).
What do you want me to do with util::high_resolution_timer?
1) You need to make a chronometer function in global scope such as: util::high_resolution_timer global_timer_object; double boost_chrono() { return global_timer_object.now(); } Internal to the timing library it makes two calls to the chronometer and uses the difference in the times, so it's important that util::high_resolution_timer never gets reset. Since it's only double precision this has subtle implications for long timings. 2) In the instantiation of ejg::generic_timer do replace the stuff that looks like ejg::generic_timer<ticks> timer(getticks); with ejg::generic_timer<double> timer(boost_chrono); Everything else should then work from there. Let me know how that goes.
Otherwise do you think the compiler is getting confused between the name of the template parameter 'ticks' and the type 'ticks'?
Hmm, do not know, I never duplicate names like that so have not run into that...
Let's assume it's ok for now...
On Sun, Jul 19, 2009 at 9:51 PM, Joel de Guzman<joel@boost-consulting.com> wrote:
Edward, just a compliment (for now): what you are doing is cool! I'm starting to be an eager supporter.
I have to say that I like the design of your timer library as well, looks to be very useful. :)
Thanks. There are (clearly) some wrinkles to iron out - but that's why we are here. -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997

hi there any design patterns implementation in boost? such as ,singleton,object factory,etc? thanks rui

On Mon, 20 Jul 2009 17:25:11 +0800, <jon_zhou@agilent.com> wrote:
any design patterns implementation in boost?
such as ,singleton,object factory,etc?
If you are refering to the gang of 4 book, you have the flyweight design pattern. http://www.boost.org/doc/libs/1_39_0/libs/flyweight/doc/index.html -- EA

On Mon, Jul 20, 2009 at 4:33 AM, Edouard A.<edouard@fausse.info> wrote:
On Mon, 20 Jul 2009 17:25:11 +0800, <jon_zhou@agilent.com> wrote:
any design patterns implementation in boost?
such as ,singleton,object factory,etc?
If you are refering to the gang of 4 book, you have the flyweight design pattern.
http://www.boost.org/doc/libs/1_39_0/libs/flyweight/doc/index.html
And visitor (see boost::variant). Obviously iterator is implemented by boost, and boost also has state machines implementing the State pattern.

chrono_start = chrono(); while ( double( chrono_wall() - chrono_wall_start ) < chrono_wall_scale*4.0); chrono_end = chrono();
I'm now doubly confused as it appears to be complaining about the return type of std::clock, (the default wall-clock timer). Maybe I can get my hands on a windows machine and compiler tomorrow....
Edward, just a compliment (for now): what you are doing is cool! I'm starting to be an eager supporter.
Always good to hear.... ;-) After a mammoth effort and much code rejigging I've got it to not only compile, but work on Windows with MSVC8! In fairness to the MS compiler it did spot some subtle run-time errors that I was getting away with just fine with g++. I've had to rip out parts that used my home brew striding_iterator since there's no way to avoid dereferencing one past the end of the end. Similarly I've had to give up on keeping all the time deltas as integer types in order to cope with the Windows .QuadPart approach. If you refer back to the discussion I was having with OverminD1 (thanks a lot for your efforts) you'll see it was causing some grief when trying to compile on Windows. As a consequence the timer appears to be less sensitive, so may not pick out differences < 0.5%, but frankly who cares? ;-) Anyhow, enough rambling: http://tinyurl.com/km9xlh The new timing code (with a better PDF containing docs) is: ejg-timer-0.0.3.tar.gz Those of you watching in black and white need to set up MSVC and compile example_timer.cpp. Everyone watching in colour need only do the usual: ./configure; make; make install voodo... The uint_parser example that utilises the above is: ejg_uint_parser_0_0_3.cpp I wait with baited breath. -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
On Mon, Jul 20, 2009 at 1:40 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
chrono_start = chrono(); while ( double( chrono_wall() - chrono_wall_start ) < chrono_wall_scale*4.0); chrono_end = chrono();
I'm now doubly confused as it appears to be complaining about the return type of std::clock, (the default wall-clock timer). Maybe I can get my hands on a windows machine and compiler tomorrow....
Edward, just a compliment (for now): what you are doing is cool! I'm starting to be an eager supporter.
Always good to hear.... ;-)
After a mammoth effort and much code rejigging I've got it to not only compile, but work on Windows with MSVC8! In fairness to the MS compiler it did spot some subtle run-time errors that I was getting away with just fine with g++. I've had to rip out parts that used my home brew striding_iterator since there's no way to avoid dereferencing one past the end of the end.
Similarly I've had to give up on keeping all the time deltas as integer types in order to cope with the Windows .QuadPart approach. If you refer back to the discussion I was having with OverminD1 (thanks a lot for your efforts) you'll see it was causing some grief when trying to compile on Windows. As a consequence the timer appears to be less sensitive, so may not pick out differences < 0.5%, but frankly who cares? ;-)
Anyhow, enough rambling:
The new timing code (with a better PDF containing docs) is:
ejg-timer-0.0.3.tar.gz
Those of you watching in black and white need to set up MSVC and compile example_timer.cpp. Everyone watching in colour need only do the usual:
./configure; make; make install
voodo...
The uint_parser example that utilises the above is:
ejg_uint_parser_0_0_3.cpp
I wait with baited breath.
Two warnings, but compile is successful. 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(468) : warning C4267: 'initializing' : conversion from 'size_t' to 'unsigned int', possible loss of data 1> R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(558) : see reference to function template instantiation 'ejg::timer_result_type &ejg::generic_timer<ticks>::measure_execution_result<void(__cdecl *)(void)>(_Operation,ejg::timer_result_type &)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _Operation=void (__cdecl *)(void) 1> ] 1> R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(242) : see reference to function template instantiation 'double ejg::generic_timer<ticks>::measure_execution_time<void(__cdecl *)(void)>(_Operation)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _Operation=void (__cdecl *)(void) 1> ] 1> .\ejg_uint_parser_0_0_3.cpp(154) : see reference to function template instantiation 'void ejg::generic_timer<ticks>::measure_percentage_speedup<void(__cdecl *)(void),void(__cdecl *)(void)>(_OperationA,_OperationB,double &,double &,double &)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _OperationA=void (__cdecl *)(void), 1> _OperationB=void (__cdecl *)(void) 1> ] 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(468) : warning C4267: 'initializing' : conversion from 'size_t' to 'unsigned int', possible loss of data 1> R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(558) : see reference to function template instantiation 'ejg::timer_result_type &ejg::generic_timer<ticks>::measure_execution_result<_LARGE_INTEGER(__cdecl *)(void)>(_Operation,ejg::timer_result_type &)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _Operation=_LARGE_INTEGER (__cdecl *)(void) 1> ] 1> R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(166) : see reference to function template instantiation 'double ejg::generic_timer<ticks>::measure_execution_time<_LARGE_INTEGER(__cdecl *)(void)>(_Operation)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _Operation=_LARGE_INTEGER (__cdecl *)(void) 1> ] 1> R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(92) : see reference to function template instantiation 'void ejg::generic_timer<ticks>::measure_infinity_time<_LARGE_INTEGER(__cdecl *)(void)>(_Operation,double &,double &,double &,size_t)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _Operation=_LARGE_INTEGER (__cdecl *)(void) 1> ] 1> R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(80) : while compiling class template member function 'void ejg::generic_timer<ticks>::calibrate_chrono_overhead(void)' 1> with 1> [ 1> ticks=ticks 1> ] 1> .\ejg_uint_parser_0_0_3.cpp(133) : see reference to class template instantiation 'ejg::generic_timer<ticks>' being compiled 1> with 1> [ 1> ticks=ticks 1> ] Running the file gives: initializing input strings... Calibrating overhead...<Unhandled Exception> So, debugging into it now reveals that the error happens on line 170 in timer.cpp, this function call: ejg::statistics::robust_linear_fit(xs.begin() , xs.begin() + n, ys.begin() , ys.begin() + n, tmp.begin(), tmp.begin() + n, intercept, slope, __); The problem is that n==4, xs.size()==4, ys.size()==4, and tmp.size()==0, thus it is trying to get an iterator 4 elements past the end. I do not see where you can set tmp either, at the start of the function you tmp.clear(), but then never touch it again, so of course it is going to be a size of 0, does this function really work in gcc, and if so how?
I wait with baited breath.
Two warnings, but compile is successful.
1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/timer.cpp(468) : warning C4267: 'initializing' : conversion from 'size_t' to 'unsigned int', possible loss of data 1>
[....] etc.
Running the file gives: initializing input strings... Calibrating overhead...<Unhandled Exception>
So, debugging into it now reveals that the error happens on line 170 in timer.cpp, this function call:
ejg::statistics::robust_linear_fit(xs.begin() , xs.begin() + n, ys.begin() , ys.begin() + n, tmp.begin(), tmp.begin() + n, intercept, slope, __);
Blast! That's one of the goofs I spotted via MSVC. It turns out I didn't pull the latest sources from CVS when building the tar file. Sorry.
the function you tmp.clear(), but then never touch it again, so of course it is going to be a size of 0, does this function really work in gcc, and if so how?
Yes it does work in g++, I think because it's less conforming to the true concept of a vector object than the MSVC compiler (there I wrote it). I presume that's what all the #if defined(BOOST_MSVC) #pragma inline_depth(255) #pragma inline_recursion(on) #define _SECURE_SCL 0 #endif // defined(BOOST_MSVC) means at the top of Joel's file - switching off the bounds checking. I think the gcc implementation of the stl is unchecked by default. Consider the following: #include <vector> #include <iostream> #include <iterator> int main() { using namespace std; vector<double> v(10); cout << v.capacity() << " " << v.size() << endl; v.clear(); cout << v.capacity() << " " << v.size() << endl; // Will the following fail? It jolly well should! v[5] = 2; cout << v.capacity() << " " << v.size() << endl; // Consequently if we squirt it out using copy(v.begin(),v.begin()+10,ostream_iterator<double>(cout," ")); // It *might* work as in practice it should access the same memory as if we // had not done .clear(). Strictly though it's evil! return 0; } $ ./clear_capacity 10 10 10 0 10 0 0 0 0 0 0 2 0 0 0 0 That's pure evil of course! I suppose that's a good reason for always using .begin() and .end() rather than .begin() + N. I'll double and triple check everything again to confirm it works, then post it up again. Sorry about this mucking around. It makes me appreciate how hard it is to get things not just working but 'correct' across so many platforms. -ed
------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
On Tue, Jul 21, 2009 at 4:17 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Sorry about this mucking around. It makes me appreciate how hard it is to get things not just working but 'correct' across so many platforms.
Heh, I know how that is. My development is on Windows, but I still distribute many of my libraries to people who use it with GCC, so I have learned to fix many things. :) In my own written code I am in a pretty good habit now, whatever I write seems to compile correctly everywhere, but that was after many many years...
On 21 Jul 2009, at 11:42, OvermindDL1 wrote:
On Tue, Jul 21, 2009 at 4:17 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Sorry about this mucking around. It makes me appreciate how hard it is to get things not just working but 'correct' across so many platforms.
Heh, I know how that is. My development is on Windows, but I still distribute many of my libraries to people who use it with GCC, so I have learned to fix many things. :)
Right, Hopefully this is (n+1) time lucky! I've placed them on the Boost Vault under Tools as before. Direct links below: http://tinyurl.com/ejg-timer-0-0-4-zip http://tinyurl.com/uint-parser-0-0-4-cpp I have verified these working under Release and Debug on MSVC8. The uint_parser gives a load of spirit related warnings, but seems to work - not sure what to make of them. Again, for 'Debug' Spirit is reported as being around -50% faster [negative speedup - like the expanding economy] than the native versions, for 'Release' with all optimisation switched on it is reported as being ~1000% faster than atol. As I mentioned before I find this speedup unnerving. Not knowing what Spirit does I've no idea if somewhere deep in its guts things might be optimised away. Please ignore the message on the Vault saying '(Please wait) - Currently I am testing this again from the download.' For some unknown reason I don't seem to be able to modify it. Attached is a screen shot for proof! -ed
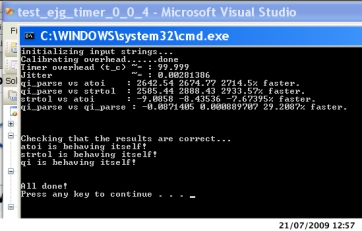{kind=link}

On Tue, Jul 21, 2009 at 6:17 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
// Will the following fail? It jolly well should! v[5] = 2; cout << v.capacity() << " " << v.size() << endl;
That's pure evil of course! I suppose that's a good reason for always using .begin() and .end() rather than .begin() + N.
Correct me if I'm wrong, but it seems you're complaining that v[5] doesn't do bounds checking? The standard does not require bounds checking on array subscript, though it seems there's nothing saying it shouldn't bounds check. But there's the alternate v.at(5) notation if you do need bounds checking. --SPCD "Celtic Minstrel"
Celtic Minstrel wrote:
On Tue, Jul 21, 2009 at 6:17 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
// Will the following fail? It jolly well should! v[5] = 2; cout << v.capacity() << " " << v.size() << endl;
That's pure evil of course! I suppose that's a good reason for always using .begin() and .end() rather than .begin() + N.
Correct me if I'm wrong, but it seems you're complaining that v[5] doesn't do bounds checking? The standard does not require bounds checking on array subscript, though it seems there's nothing saying it shouldn't bounds check. But there's the alternate v.at(5) notation if you do need bounds checking.
--SPCD "Celtic Minstrel" _______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost
The issue is that v.begin(), v.begin()+5 should not be bounds checked, but by default in vc9 (vs 2008) it is. In vc10, the default is that it is not on by default.

On 21 Jul 2009, at 21:35, Raindog wrote:
Celtic Minstrel wrote:
On Tue, Jul 21, 2009 at 6:17 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
// Will the following fail? It jolly well should! v[5] = 2; cout << v.capacity() << " " << v.size() << endl;
That's pure evil of course! I suppose that's a good reason for always using .begin() and .end() rather than .begin() + N.
Correct me if I'm wrong, but it seems you're complaining that v[5] doesn't do bounds checking? The standard does not require bounds checking on array subscript, though it seems there's nothing saying it shouldn't bounds check. But there's the alternate v.at(5) notation if you do need bounds checking.
--SPCD "Celtic Minstrel" _______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost
The issue is that v.begin(), v.begin()+5 should not be bounds checked, but by default in vc9 (vs 2008) it is. In vc10, the default is that it is not on by default.
No no, it's quite legal to bounds check it. As soon as you go past the end of the vector, you are into undefined behaviour, and any kind of nasty thing could happen. In practice you might find your code works fine, but it's not impossible some future case or optimisation will cause broken behaviour. Chris
On 21 Jul 2009, at 13:42, Celtic Minstrel wrote:
On Tue, Jul 21, 2009 at 6:17 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
// Will the following fail? It jolly well should! v[5] = 2; cout << v.capacity() << " " << v.size() << endl;
That's pure evil of course! I suppose that's a good reason for always using .begin() and .end() rather than .begin() + N.
Correct me if I'm wrong, but it seems you're complaining that v[5] doesn't do bounds checking?
Not really. Perhaps 'fail' in the above is not quite what I mean. My main gripe is the inconsistency.
The standard does not require bounds checking on array subscript, though it seems there's nothing saying it shouldn't bounds check. But there's the alternate v.at(5) notation if you do need bounds checking.
My problem is really that this is 'undefined' behaviour. Surely anything that's 'undefined' is open to error? My second gripe is that even the idea of undefined behaviour is inconsistent (in MSVC at least). I can quite happily iterate something to .end() (one past the last element) but not to .end()+n --- why? From what I understand dereferencing either is wrong, why is one more wrong than the other? From what I can see this prevents the simple creation of a striding iterator, for which the .end() can be at .end() + stride of the underlying vector. One can do it easily by default in g++ as it doesn't hold your hand (exposing you to dereferincing this as being undefined) and leaving that up to you. In MSVC8 it will barf since the debug bounds checking doesn't allow you to keep iterating past the end. Which is the correct treatment? -ed
Edward Grace wrote:
On 21 Jul 2009, at 13:42, Celtic Minstrel wrote:
On Tue, Jul 21, 2009 at 6:17 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
The standard does not require bounds checking on array subscript, though it seems there's nothing saying it shouldn't bounds check. But there's the alternate v.at(5) notation if you do need bounds checking.
My problem is really that this is 'undefined' behaviour. Surely anything that's 'undefined' is open to error?
My second gripe is that even the idea of undefined behaviour is inconsistent (in MSVC at least). I can quite happily iterate something to .end() (one past the last element) but not to .end()+n --- why?
Because dereferencing an end iterator has undefined behavior.
From what I understand dereferencing either is wrong, why is one more wrong than the other?
It isn't more wrong. The effects are simply more pronounced for one than the other due to some implementation detail on which you cannot count.
From what I can see this prevents the simple creation of a striding iterator, for which the .end() can be at .end() + stride of the underlying vector. One can do it easily by default in g++ as it doesn't hold your hand (exposing you to dereferincing this as being undefined) and leaving that up to you. In MSVC8 it will barf since the debug bounds checking doesn't allow you to keep iterating past the end.
The debug bounds checking is revealing that you are relying on undefined behavior.
Which is the correct treatment?
Perhaps you're unfamiliar with the phrase "undefined behavior." It means that absolutely anything is possible. Each implementation can behave differently, even in different cases. If you avoid doing what has undefined behavior, you'll never encounter such vagaries. If you persist in doing what has undefined behavior, you'll need to account for the differences among compilers -- across versions and operating systems -- and any use cases that lead to different results. Furthermore, you'd have to maintain the non-portable code as each new compiler or use cases presents. If it isn't clear by now, don't dereference an end iterator and don't try to dereference anything past it. Doing so is untenable in portable code. _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.
Dear Robert, [ We're probably in danger of irritating other people if we continue this discussion too long let's try and keep it brief].
My second gripe is that even the idea of undefined behaviour is inconsistent (in MSVC at least). I can quite happily iterate something to .end() (one past the last element) but not to .end()+n --- why?
Because dereferencing an end iterator has undefined behavior.
The above was a slip of the finger. I agree with you regarding the .end() + n. I should have based it on .begin() which was the original source of my iteration. A concrete example of what I'm talking about is here: http://tinyurl.com/ns8j83 I assert that the problem is that the bounds checking in MSVC is wrong - it should only be checking for the de-referencing of invalid iterators not their creation. What do you think?
From what I can see this prevents the simple creation of a striding iterator, for which the .end() can be at .end() + stride of the underlying vector. One can do it easily by default in g++ as it doesn't hold your hand (exposing you to dereferincing this as being undefined) and leaving that up to you. In MSVC8 it will barf since the debug bounds checking doesn't allow you to keep iterating past the end.
The debug bounds checking is revealing that you are relying on undefined behavior.
I may be in practice - but I don't think I am in principle.
Which is the correct treatment?
Perhaps you're unfamiliar with the phrase "undefined behavior."
It's occasionally been used to describe the conduct of some friends of mine.
If it isn't clear by now, don't dereference an end iterator and don't try to dereference anything past it.
I don't think I am -- that's my point. Ultimately are random access iterators *supposed* to be homeomorphic to the integers in the same (apparent) way C indices are? -ed
Edward Grace wrote:
Dear Robert,
My second gripe is that even the idea of undefined behaviour is inconsistent (in MSVC at least). I can quite happily iterate something to .end() (one past the last element) but not to .end()+n --- why?
Because dereferencing an end iterator has undefined behavior.
The above was a slip of the finger. I agree with you regarding the .end() + n. I should have based it on .begin() which was the original source of my iteration.
A concrete example of what I'm talking about is here:
typedef std::vector<int> vector; vector v(3);
I assert that the problem is that the bounds checking in MSVC is wrong - it should only be checking for the de-referencing of invalid iterators not their creation.
It is not valid according to the standard. The operational equivalent for v.begin() + n, in Table 76 (random access iterator requirements) is: vector::iterator tmp(v.begin()); tmp += n; The operational semantics for tmp += n, same table, is: iterator_traits<vector::iterator>::difference_type m(n); if (m >= 0) while (m--) ++tmp; else while (m++) --tmp; Finally, the precondition for ++tmp, from Table 74 (forward iterator requirements), and for --tmp, from Table 75 (bidirectional iterator requirements), requires that tmp be dereferenceable. Once n >= v.size(), the resulting iterator is no longer dereferenceable and the MSVC checking is valid.
From what I can see this prevents the simple creation of a striding iterator, for which the .end() can be at .end() + stride of the underlying vector. One can do it easily by default in g++ as it doesn't hold your hand (exposing you to dereferincing this as being undefined) and leaving that up to you. In MSVC8 it will barf since the debug bounds checking doesn't allow you to keep iterating past the end.
The debug bounds checking is revealing that you are relying on undefined behavior.
I may be in practice - but I don't think I am in principle.
You are.
Ultimately are random access iterators *supposed* to be homeomorphic to the integers in the same (apparent) way C indices are?
There are additional preconditions for the iterators. _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.
On 22 Jul 2009, at 16:23, Stewart, Robert wrote:
Ultimately are random access iterators *supposed* to be homeomorphic to the integers in the same (apparent) way C indices are?
I'm sure that: int a[3] int* b = a + 4; Is illegal C code, as you have gone outside the bounds of your array, even if you never dereference the pointer. Chris
On 22 Jul 2009, at 18:02, Christopher Jefferson wrote:
On 22 Jul 2009, at 16:23, Stewart, Robert wrote:
Ultimately are random access iterators *supposed* to be homeomorphic to the integers in the same (apparent) way C indices are?
I'm sure that:
int a[3] int* b = a + 4;
Is illegal C code, as you have gone outside the bounds of your array, even if you never dereference the pointer.
Following your minimalistic example, I'm thinking about: typdef int index; int a[3]; index i = 0; // Index idx is homeomorphic to the integers 'cause it is one. i -= 1000; i += 2002; int b=a[i]; That's clearly ok as idx is 2 and the last line is b=*(a + 2). Whereas. int *p = a; p = p - 1000; // Undefined? p = p + 1002; // Also undefined? int b=*p; Is presumably undefined. That implies to me that pointer arithmetic is *not* like integer arithmetic since the first example is not identical to the second. Baring in mind the old adage of Mark Twain, http://www.quotationspage.com/quote/369.html it seems to me absurd that they are not the same. I guess that's just the way it is. -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997

AMDG Edward Grace wrote:
Following your minimalistic example, I'm thinking about:
typdef int index; int a[3];
index i = 0; // Index idx is homeomorphic to the integers 'cause it is one.
i -= 1000; i += 2002;
int b=a[i];
That's clearly ok as idx is 2 and the last line is b=*(a + 2).
Whereas.
int *p = a;
p = p - 1000; // Undefined? p = p + 1002; // Also undefined?
int b=*p;
Is presumably undefined.
That implies to me that pointer arithmetic is *not* like integer arithmetic since the first example is not identical to the second.
Baring in mind the old adage of Mark Twain,
http://www.quotationspage.com/quote/369.html
it seems to me absurd that they are not the same. I guess that's just the way it is.
This is also undefined behavior: int i = 10; i += std::numeric_limits<int>::max(); i -= std::numeric_limits<int>::max(); So integer arithmetic and pointer arithmetic are really not very different. The behavior of integer arithmetic is defined as long as no calculations overflow (This only applies to signed integers. unsigned integers are guaranteed to wrap). The behavior of pointer arithmetic is defined as long as the pointers stay within the bounds of the array (allowing for a one past the end, pointer). In Christ, Steven Watanabe
I assert that the problem is that the bounds checking in MSVC is wrong - it should only be checking for the de-referencing of invalid iterators not their creation.
It is not valid according to the standard. The operational equivalent for v.begin() + n, in Table 76 (random access iterator requirements) is:
vector::iterator tmp(v.begin()); tmp += n;
The operational semantics for tmp += n, same table, is:
iterator_traits<vector::iterator>::difference_type m(n); if (m >= 0) while (m--) ++tmp; else while (m++) --tmp;
Finally, the precondition for ++tmp, from Table 74 (forward iterator requirements), and for --tmp, from Table 75 (bidirectional iterator requirements), requires that tmp be dereferenceable.
Presumably the above requirement for the random access iterator is a result of it being an extension of a forward iterator?
Once n >= v.size(), the resulting iterator is no longer dereferenceable and the MSVC checking is valid.
Fair enough. It is what it is. As long as I know what to believe I'm happy. -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997

on Tue Jul 21 2009, Edward Grace <ej.grace-AT-imperial.ac.uk> wrote:
I think the gcc implementation of the stl is unchecked by default.
Yes, you can #define _GLIBCXX_DEBUG to get checking for GCC -- Dave Abrahams BoostPro Computing http://www.boostpro.com
I think the gcc implementation of the stl is unchecked by default.
Yes, you can #define _GLIBCXX_DEBUG to get checking for GCC
Again, thanks. I spotted that in the source. That one's going to be used a lot from now on! -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Edward Grace wrote:
Anyhow, enough rambling:
The new timing code (with a better PDF containing docs) is:
ejg-timer-0.0.3.tar.gz
Those of you watching in black and white need to set up MSVC and compile example_timer.cpp. Everyone watching in colour need only do the usual:
./configure; make; make install
If you're really watching in color, and assuming you want that library in Boost, then you'd want to use Bjam instead ;-) Also, most docs in Boost use Quickbook/Boostbook. Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
on Mon Jul 20 2009, Edward Grace <ej.grace-AT-imperial.ac.uk> wrote:
I've had to rip out parts that used my home brew striding_iterator since there's no way to avoid dereferencing one past the end of the end.
A correct strided_iterator is enclosed. -- Dave Abrahams BoostPro Computing http://www.boostpro.com
Dear David,
I've had to rip out parts that used my home brew striding_iterator since there's no way to avoid dereferencing one past the end of the end.
A correct strided_iterator is enclosed.
I note the following from your documentation of Boost.Iterator "Writing standard-conforming iterators is tricky, but the need comes up often.". A clear penchant for understatement I see. ;-) It worries me slightly that subtleties of undefined behaviour in pointer arithmetic could easily go unnoticed. My unscientific poll of people around here turned up zero correct answers to the basic problem; this is the Physics department though. Thanks for that, I will read, cogitate, deliberate and digest! Regards, -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Okay, compiled the code, got this: 1>------ Build started: Project: ejg_uint_parser_timing, Configuration: Release Win32 ------ 1>Compiling... 1>ejg_uint_parser.cpp 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/statistics/statistics.hpp(417) : error C2220: warning treated as error - no 'object' file generated 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/statistics/statistics.hpp(417) : warning C4244: 'return' : conversion from 'double' to 'unsigned int', possible loss of data
return std::ceil(-std::log(a)/std::log(2.0)); Ok, fair play, perhaps it's static_cast time.
1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/statistics/statistics.cpp(28) : error C2039: 'ptr_fun' : is not a member of 'std' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/statistics/statistics.cpp(28) : error C2873: 'ptr_fun' : symbol cannot be used in a using-declaration
It jolly well is a member of std::, perhaps I should include <functional> then!
1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/timer.cpp(273) : warning C4003: not enough actual parameters for macro 'max'
WTF? What the hell's wrong with this? time_raw_atom( _Operation f) { ticks t0(0),t1(0),delta(std::numeric_limits<ticks>::max()); Ok. I bet MSVC (that's what you're using right) defines macros called "min" and "max". I guess that's what happens when one sips from the teat of the devil. A couple of undefs perhaps..
1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/timer.cpp(384) : warning C4003: not enough actual parameters for macro 'min' 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/timer.cpp(385) : warning C4003: not enough actual parameters for macro 'max' 1>using native typeof
ticks max_global_ticks(std::numeric_limits<ticks>::min()), min_global_ticks(std::numeric_limits<ticks>::max()); Ditto....
1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/timer.hpp(1018) : warning C4512: 'ejg::generic_timer<ticks>' : assignment operator could not be generated 1> with 1> [ 1> ticks=ticks 1> ] 1> .\ejg_uint_parser.cpp(133) : see reference to class template instantiation 'ejg::generic_timer<ticks>' being compiled 1> with 1> [ 1> ticks=ticks 1> ] 1>Build Time 0:09 1>Build log was saved at "file://r:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \Release\BuildLog.htm" 1>ejg_uint_parser_timing - 3 error(s), 5 warning(s)
Hmm, perhaps confusing the name of the template parameter with the type. I don't need an assignment operator for ejg::generic_timer<?>. Looks like it may be an oblique way of moaning about the const member attribute.
So yes, this is very much not usable for me,
Ouch.
but there is your buildlog anyway. :)
Thanks......... ......I think. ;-) Looking back at this email I think it's doable... Give me 10 mins (then I really must go to bed!). -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
On Sun, Jul 19, 2009 at 6:47 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote: 1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(273)
: warning C4003: not enough actual parameters for macro 'max'
WTF? What the hell's wrong with this?
time_raw_atom( _Operation f) { ticks t0(0),t1(0),delta(std::numeric_limits<ticks>::max());
Ok. I bet MSVC (that's what you're using right) defines macros called "min" and "max". I guess that's what happens when one sips from the teat of the devil. A couple of undefs perhaps..
Correct, some old VC headers define min/max for some godforsaken reason. Anytime I use the words min/max in any of my files anywhere, then at the top of the file, after the generic header includes I always add: #ifdef min # undef min #endif // min #ifdef max # undef max #endif // max And yea yea, I would like to use GCC to compile, but I currently have sold my soul to the Visual Assist plugin for Visual Studio. If any IDE out there with GCC support had anywhere near the capabilities of Visual Assist (without Visual Assist, Eclipse is even better then VC), I would switch in a heart-beat. Visual Assist just saves me on the order of a monstrous amount of time, completely addicted by this point.
AMDG Edward Grace wrote:
1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing\other_includes\ejg/timer.cpp(273)
: warning C4003: not enough actual parameters for macro 'max'
time_raw_atom( _Operation f) { ticks t0(0),t1(0),delta(std::numeric_limits<ticks>::max());
Ok. I bet MSVC (that's what you're using right) defines macros called "min" and "max". I guess that's what happens when one sips from the teat of the devil. A couple of undefs perhaps..
Strictly speaking it's windows.h not msvc that #define's min and max. See http://www.boost.org/development/requirements.html#Design_and_Programming for acceptable workarounds. In Christ, Steven Watanabe
On 20 Jul 2009, at 02:07, Steven Watanabe wrote:
AMDG
Edward Grace wrote:
1>R:\Programming_Projects\Spirit_Price\ejg_uint_parser_timing \other_includes\ejg/timer.cpp(273)
: warning C4003: not enough actual parameters for macro 'max'
time_raw_atom( _Operation f) { ticks t0(0),t1(0),delta(std::numeric_limits<ticks>::max());
Ok. I bet MSVC (that's what you're using right) defines macros called "min" and "max". I guess that's what happens when one sips from the teat of the devil. A couple of undefs perhaps..
Strictly speaking it's windows.h not msvc that #define's min and max. See http://www.boost.org/development/ requirements.html#Design_and_Programming for acceptable workarounds.
Thanks. Cap duly doffed. -ed ------------------------------------------- "No more boom and bust." -- Dr. J. G. Brown, 1997
Edward Grace wrote:
N.B. The final timing of qi_parse against itself is zero percent within the nominal precision. At first I thought the 1000% speedup of qi_parse was a fake due to some compiler shenanigans. Now I don't think so. I think it really is that much faster for small buffers! Note that this timing experiment took ~6mins.
[...]
Same results - actually better since the experiment is quicker and the 95th percentile range is therefore narrower. Obviously I'm suspicious that something funny's going on - would you expect it to be capable of being ~10x faster?
Interesting... It seems that spatial locality strongly favors optimized Spirit code very well -- best when the data structure can reside fully in the cache. Try bumping the size incrementally and I expect a big dip in performance at a certain point. Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
I just changed the file to use spirit for parsing where I had used lexical_cast got very different timings for xpressive now, so now, with xpressive using a bit of spirit I get: Loop count: 10000000 Parsing: 42.5 xpressive: 15.4841 spirit-quick(static): 3.01117 spirit-quick_new(threadsafe): 3.10548 spirit-grammar(threadsafe/reusable): 3.81694
Vast increase, 3x faster xpressive is now. Also, how do you fix that rather bloody massive warning about double->int64 truncation? I also changed all int64_t to boost::long_long_type since they are the same thing anyway (on 32-bit at least?), as well as it being multi-platform unlike int64_t. My changed file is attached. Do not know if this is considered cheating now that xpressive is using some spirit now. ;-)
This is somewhat cheating. We've tuned the numeric parsers of Spirit with TMP tricks, loop unrolling, etc. Those are very finely tuned numeric parsers you see there that beats the fastest C code such as strtol and atoi. The following benchmarks reveal 2X+ speed against low level strtol and atoi (attached). I am getting:
atoi: 0.82528 [s] strtol: 0.792227 [s] int_: 0.358016 [s]
The first and second are the low-level C routines. The third is Spirit's int_ parser. I need not mention that the C routines only accept C strings while the Spirit int_ parser can accept any forward iterator. So, in a sense, we're comparing apples and oranges. But this goes to show that you can write highly optimized code in generic C++.
Slightly off-topic, but in order to emphasize what Joel said, here are a couple of benchmark results I published a couple of days ago related to output formatting: http://tinyurl.com/n4368t. Just an excerpt (Intel Core Duo(tm) Processor, 2.8GHz, 4GByte RAM, Intel 11.1/64Bit): Performance comparison for formatting a single double (all times in [s], 1000000 iterations): sprintf: 0.694 iostreams: 1.354 Boost.Format: 2.011 Karma double_: 0.218 (where double_ is the Spirit.Karma output generator for a default floating point format) Regards Hartmut
OvermindDL1 wrote:
As stated, the numbers are basically hogwash until all three forms are all tested on the same hardware using the same compiler. I *might* have time tonight to work on the code that the others posted above to get it compilable, although it is rather irritating that they posted code that was incomplete, but meh.
I'm getting tired of reading your indirect insults of me. I already responded that I would post complete code if and when I could. I'm pleased to see you so excited to work on this now and to show that using Spirit may well be the ideal solution. I'm sorry for your irritation that more from me is not forthcoming, but I cannot do more just now. Please drop the negativity. I posted my code in the most complete form I could for Eric's benefit, not so it would be a complete example and test suite for you and others could compile and run. *When* I have the opportunity, I will extract the code that exists in different files and libraries, and craft a custom version of the scaffolding necessary to make my Xpressive and custom code compile and which will reflect what I was actually running when I gave comparative results. I tried posting a file with the test inputs to this list, but it made my message too large and was rejected. I didn't think it made sense to put such a file in the vault, so I have not put it there -- or anywhere -- as yet. Lacking any other concrete idea, I may post the file in the vault anyway. I will indicate as much when I do. _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.
On Mon, Jul 20, 2009 at 7:18 AM, Stewart, Robert <Robert.Stewart@sig.com> wrote:
I'm getting tired of reading your indirect insults of me. I already responded that I would post complete code if and when I could. I'm pleased to see you so excited to work on this now and to show that using Spirit may well be the ideal solution. I'm sorry for your irritation that more from me is not forthcoming, but I cannot do more just now. Please drop the negativity.
No insults intended. Just on the other lists I frequent, posting incomplete source-code is not allowed, and such 'hints' serve to remind people of that. Habit is hard to drop on other lists since that rule is so amazingly useful. :) On Mon, Jul 20, 2009 at 7:18 AM, Stewart, Robert <Robert.Stewart@sig.com> wrote:
I tried posting a file with the test inputs to this list, but it made my message too large and was rejected. I didn't think it made sense to put such a file in the vault, so I have not put it there -- or anywhere -- as yet. Lacking any other concrete idea, I may post the file in the vault anyway. I will indicate as much when I do.
Posting large files to the list are fine, I have done so a few times, it takes longer to get it accepted, but mine have always been accepted. How long ago did you post it?

OvermindDL1 skrev:
On Mon, Jul 20, 2009 at 7:18 AM, Stewart, Robert <Robert.Stewart@sig.com> wrote:
I'm getting tired of reading your indirect insults of me. I already responded that I would post complete code if and when I could. I'm pleased to see you so excited to work on this now and to show that using Spirit may well be the ideal solution. I'm sorry for your irritation that more from me is not forthcoming, but I cannot do more just now. Please drop the negativity.
No insults intended. Just on the other lists I frequent, posting incomplete source-code is not allowed, and such 'hints' serve to remind people of that. Habit is hard to drop on other lists since that rule is so amazingly useful. :)
Well, the code might not be yours to post, e.g. your employer might not allow you to do that without permission. Furthermore, one can ofte give very fast aswers if one does not need to test code etc. -Thorsten
Thorsten Ottosen wrote:
OvermindDL1 skrev:
On Mon, Jul 20, 2009 at 7:18 AM, Stewart, Robert <Robert.Stewart@sig.com> wrote:
I'm getting tired of reading your indirect insults of me. I already responded that I would post complete code if and when I could. I'm pleased to see you so excited to work on this now and to show that using Spirit may well be the ideal solution. I'm sorry for your irritation that more from me is not forthcoming, but I cannot do more just now. Please drop the negativity.
No insults intended. Just on the other lists I frequent, posting incomplete source-code is not allowed, and such 'hints' serve to remind people of that. Habit is hard to drop on other lists since that rule is so amazingly useful. :)
Well, the code might not be yours to post, e.g. your employer might not allow you to do that without permission.
Furthermore, one can ofte give very fast aswers if one does not need to test code etc.
Agreed, but Rob somehow presented a challenge when he said: "The purpose of this exercise is to compare the code and performance, so they must all perform the same task." This implies that there's a code to compare to and benchmark against. Also, it's rather frustrating to see posted benchmarks without being able to really test them and scrutinize the code for possible errors, etc. Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
Joel de Guzman wrote:
Thorsten Ottosen wrote:
Well, the code might not be yours to post, e.g. your employer might not allow you to do that without permission.
Furthermore, one can ofte give very fast aswers if one does not need to test code etc.
Agreed, but Rob somehow presented a challenge when he said:
"The purpose of this exercise is to compare the code and performance, so they must all perform the same task."
As I recall the context, that was in answer to some questions about what Overmind had begun.
This implies that there's a code to compare to and benchmark against. Also, it's rather frustrating to see posted benchmarks without being able to really test them and scrutinize the code for possible errors, etc.
Overmind was deviating from the original description and so I was showing that for *his work* to be comparable to what I had done and posted, it had to perform the same task. I'm sorry to have implied more. I agree that little more can be done until I post complete examples or someone else manages to do so from what I did post. _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.
OvermindDL1 wrote:
On Mon, Jul 20, 2009 at 7:18 AM, Stewart, Robert <Robert.Stewart@sig.com> wrote:
I tried posting a file with the test inputs to this list, but it made my message too large and was rejected. I didn't think it made sense to put such a file in the vault, so I have not put it there -- or anywhere -- as yet. Lacking any other concrete idea, I may post the file in the vault anyway. I will indicate as much when I do.
Posting large files to the list are fine, I have done so a few times, it takes longer to get it accepted, but mine have always been accepted. How long ago did you post it?
As I said, it was rejected. I didn't suggest that the message is languishing in a moderation queue. Compressed, the file is over 300KiB. _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.
Stewart, Robert wrote:
When* I have the opportunity, I will extract the code that exists in different files and libraries, and craft a custom version of the scaffolding necessary to make my Xpressive and custom code compile and which will reflect what I was actually running when I gave comparative results.
Thank you, Robert. Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
Joel de Guzman wrote:
Stewart, Robert wrote:
When* I have the opportunity, I will extract the code that exists in different files and libraries, and craft a custom version of the scaffolding necessary to make my Xpressive and custom code compile and which will reflect what I was actually running when I gave comparative results.
Thank you, Robert.
Alright folks. I've finally extracted all of the necessary pieces and assembled them into a single main.cpp plus test inputs file. You can find them here: http://tinyurl.com/price-parsing-7z I have not supplied any build files as our local build system is unique and I don't know bjam. The structure of main.cpp is as follows, with each section delimited by comments with lots of vertical pipes: 0. A hopefully portable definition of int64_t extracted from boost/cstdint.hpp (is there a better option for this that I missed?) 1. Forward declarations of the three parse functions (with functors to permit injecting the parse functions into the run_test function template) 2. Some core and testing namespace forward declarations for main() 3. main() 4. More core declarations needed for the custom string and Xpressive variants 5. core and testing namespace function definitions 6. Custom string parser implementation 7. Xpressive parser implementation 8. Spirit parser stub I put include directives needed for main(), the test harness, and the core namespace at the top. Others, peculiar to a particular parser appear in that parser's section of the file. The custom, string parser and my final Xpressive parser are included. Note that xpressive_parsing::match_s is commented out and that xpressive_parsing::parse()'s match_s is a function local static because I don't have Boost.Threads built locally. Remove the function local static and uncomment the match_s lines to use TLS for match_s, a necessary condition for a fair test. I have not supplied a Spirit v2 implementation. Someone else will need to provide that. Note that the code must be reentrant. When I was working this problem, I was constrained to use Boost 1.37. It would be useful to know if there is a performance difference between Boost 1.37 and 1.39 for Xpressive and Spirit v2. main() takes two arguments: the pathname of the test inputs and the number of times to run through the inputs. On my system, parsing all of the inputs once took less than a second. When I ran my code, with 100 iterations, the Xpressive version, with the function local static match_s, was 9X slower than the custom code. That is worse than I saw in my more trivial tests previously. The test inputs are arranged one test to a line, with the input to parse quoted and whitespace separated from the expected int64_t result. Let the optimizing begin! _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.
On Mon, Jul 27, 2009 at 1:34 PM, Stewart, Robert<Robert.Stewart@sig.com> wrote:
Joel de Guzman wrote:
Stewart, Robert wrote:
When* I have the opportunity, I will extract the code that exists in different files and libraries, and craft a custom version of the scaffolding necessary to make my Xpressive and custom code compile and which will reflect what I was actually running when I gave comparative results.
Thank you, Robert.
Alright folks. I've finally extracted all of the necessary pieces and assembled them into a single main.cpp plus test inputs file. You can find them here:
Awesome. I will integrate my Spirit2.1 version into it and run the test and all so forth as well. Once I confirm that my Spirit2.1 version tests correct then I will run the timings. On Mon, Jul 27, 2009 at 1:34 PM, Stewart, Robert<Robert.Stewart@sig.com> wrote:
I have not supplied any build files as our local build system is unique and I don't know bjam.
I will just dump it all into Visual Studio and let it munch on it. On Mon, Jul 27, 2009 at 1:34 PM, Stewart, Robert<Robert.Stewart@sig.com> wrote:
The structure of main.cpp is as follows, with each section delimited by comments with lots of vertical pipes:
0. A hopefully portable definition of int64_t extracted from boost/cstdint.hpp (is there a better option for this that I missed?)
That is what is supposed to be used for multi-platform integers with 64-bit width. :) On Mon, Jul 27, 2009 at 1:34 PM, Stewart, Robert<Robert.Stewart@sig.com> wrote:
1. Forward declarations of the three parse functions (with functors to permit injecting the parse functions into the run_test function template)
2. Some core and testing namespace forward declarations for main()
3. main()
4. More core declarations needed for the custom string and Xpressive variants
5. core and testing namespace function definitions
6. Custom string parser implementation
7. Xpressive parser implementation
8. Spirit parser stub
I will duplicate the spirit stub three times so I can put in all three version I made for proper comparison. On Mon, Jul 27, 2009 at 1:34 PM, Stewart, Robert<Robert.Stewart@sig.com> wrote:
I put include directives needed for main(), the test harness, and the core namespace at the top. Others, peculiar to a particular parser appear in that parser's section of the file.
The custom, string parser and my final Xpressive parser are included. Note that xpressive_parsing::match_s is commented out and that xpressive_parsing::parse()'s match_s is a function local static because I don't have Boost.Threads built locally. Remove the function local static and uncomment the match_s lines to use TLS for match_s, a necessary condition for a fair test.
I have not supplied a Spirit v2 implementation. Someone else will need to provide that. Note that the code must be reentrant. When I was working this problem, I was constrained to use Boost 1.37. It would be useful to know if there is a performance difference between Boost 1.37 and 1.39 for Xpressive and Spirit v2.
I will supply the Spirit2.1 implementation, due note that regardless of your version of boost, it will require that you pull Spirit out of the boost trunk, but Spirit2.1 pulled out of trunk should work fine with Boost 1.37 and up. If you wish I could bcp it out though, but that would add a ton of files to this simple test. :) On Mon, Jul 27, 2009 at 1:34 PM, Stewart, Robert<Robert.Stewart@sig.com> wrote:
main() takes two arguments: the pathname of the test inputs and the number of times to run through the inputs. On my system, parsing all of the inputs once took less than a second. When I ran my code, with 100 iterations, the Xpressive version, with the function local static match_s, was 9X slower than the custom code. That is worse than I saw in my more trivial tests previously.
I might also duplicate the xpressive test too, one for threadsafe, one not. I do not know xpressive well though so it will be a mostly simple copy. I am curious to see how well Spirit2.1 handles this. On Mon, Jul 27, 2009 at 1:34 PM, Stewart, Robert<Robert.Stewart@sig.com> wrote:
The test inputs are arranged one test to a line, with the input to parse quoted and whitespace separated from the expected int64_t result.
Let the optimizing begin!
Hear hear! I should be able to get to it tonight after work.
On Mon, Jul 27, 2009 at 6:17 PM, OvermindDL1<overminddl1@gmail.com> wrote:
/* snip */
I did a quick first test at work, just a quick compile, got some errors, and quite frankly I do not know how this compiled in gcc either. First error is: 1>r:\programming_projects\spirit_price\price_parsing\main.cpp(545) : error C2373: '_input' : redefinition; different type modifiers 1> r:\programming_projects\spirit_price\price_parsing\main.cpp(544) : see declaration of '_input' The relevant code is: template <class T> T extract(char const * & _input, char const * _description, std::string const & _input); Why do the first and last function params have the same name (_input)? And which one is the real input? Based upon line 566, I changed the last _input to _value and that error (and one other) is now gone. Hmm, actually the third error is gone too. Now I am getting lots of Warnings (as errors since I by default have warnings treated as errors) about double to int64_t cast, both in your normal code on line 730 Also, I added a: tests.reserve(450000); right before the load_tests call, that changed the load_tests time from like 10 seconds to about 2 seconds on my system. Also, why are you using time(0), that only has second accuracy?
On Mon, Jul 27, 2009 at 10:34 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Mon, Jul 27, 2009 at 6:17 PM, OvermindDL1<overminddl1@gmail.com> wrote:
/* snip */
I did a quick first test at work, just a quick compile, got some errors, and quite frankly I do not know how this compiled in gcc either. First error is: 1>r:\programming_projects\spirit_price\price_parsing\main.cpp(545) : error C2373: '_input' : redefinition; different type modifiers 1> r:\programming_projects\spirit_price\price_parsing\main.cpp(544) : see declaration of '_input'
The relevant code is: template <class T> T extract(char const * & _input, char const * _description, std::string const & _input);
Why do the first and last function params have the same name (_input)? And which one is the real input? Based upon line 566, I changed the last _input to _value and that error (and one other) is now gone. Hmm, actually the third error is gone too. Now I am getting lots of Warnings (as errors since I by default have warnings treated as errors) about double to int64_t cast, both in your normal code on line 730
Also, I added a: tests.reserve(450000); right before the load_tests call, that changed the load_tests time from like 10 seconds to about 2 seconds on my system.
Also, why are you using time(0), that only has second accuracy?
Okay, I basically just copy/pasted my thread-safe version of my spirit parser over and ran it, it returned bad parse with like 13/9 or something like that. According to the documentation in the original cpp file, only "1", "1 2/3", or "1.2" are valid, not "2/3", so I changed it to support that and ran it again, it parsed successfully with all numbers in your tests matching successfully. Here is what it printed, using the horribly inaccurate time function: Testing string-based parsing Testing Xpressive-based parsing Testing Spirit-based parsing string parsing: 8s xpressive parsing: 33s spirit parsing: 6s If you do not mind, I am going to add a millisecond accuracy testing framework (test.hpp from the boost examples) to the file and change all the nasty time calls to it for a more reliable reading. I backed up the main.cpp with my spirit addition before I will edit it anyway. I am not home yet, will add the timing functionality when I get home. I will post my new results with the enhanced testing when I get home and finish it (maybe an hour) as well as posting both the main.cpp and the testing header. For now, I have attached my modified main.cpp that includes the thread-safe spirit parser (I have not yet added the other two, do you want me to even bother?), and it includes the single line add in the main function "tests.reserve(150000);", which reserves just enough memory for your test file, now the loading function takes about half a second on my computer, instead of 9 seconds. Anyone else want to try the attached file and report the results as well as what platform and OS? I am on Windows XP using MSVC8 SP1. P.S. I would be quite happy if anyone could get rid of that freakishly long double->int64_t cast warning in the xpressive code, I like clean builds. :)
On Mon, Jul 27, 2009 at 10:34 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Mon, Jul 27, 2009 at 6:17 PM, OvermindDL1<overminddl1@gmail.com> wrote:
/* snip */
I did a quick first test at work, just a quick compile, got some errors, and quite frankly I do not know how this compiled in gcc either. First error is: 1>r:\programming_projects\spirit_price\price_parsing\main.cpp(545) : error C2373: '_input' : redefinition; different type modifiers 1> r:\programming_projects\spirit_price\price_parsing\main.cpp(544) : see declaration of '_input'
The relevant code is: template <class T> T extract(char const * & _input, char const * _description, std::string const & _input);
Why do the first and last function params have the same name (_input)? And which one is the real input? Based upon line 566, I changed the last _input to _value and that error (and one other) is now gone. Hmm, actually the third error is gone too. Now I am getting lots of Warnings (as errors since I by default have warnings treated as errors) about double to int64_t cast, both in your normal code on line 730
Also, I added a: tests.reserve(450000); right before the load_tests call, that changed the load_tests time from like 10 seconds to about 2 seconds on my system.
Also, why are you using time(0), that only has second accuracy?
The mailing list seems to be taking a very long while to send the message, so here it is again, but the attachment in the main.cpp file only, not the test_inputs.dat file (which, when zipped, is over 350kb). So get the test_inputs.dat from the link in the post prior to mine, and use the main.cpp that is attached to this post. Here is the message I sent as well, perhaps it will come through eventually: Okay, I basically just copy/pasted my thread-safe version of my spirit parser over and ran it, it returned bad parse with like 13/9 or something like that. According to the documentation in the original cpp file, only "1", "1 2/3", or "1.2" are valid, not "2/3", so I changed it to support that and ran it again, it parsed successfully with all numbers in your tests matching successfully. Here is what it printed, using the horribly inaccurate time function: Testing string-based parsing Testing Xpressive-based parsing Testing Spirit-based parsing string parsing: 8s xpressive parsing: 33s spirit parsing: 6s If you do not mind, I am going to add a millisecond accuracy testing framework (test.hpp from the boost examples) to the file and change all the nasty time calls to it for a more reliable reading. I backed up the main.cpp with my spirit addition before I will edit it anyway. I am not home yet, will add the timing functionality when I get home. I will post my new results with the enhanced testing when I get home and finish it (maybe an hour) as well as posting both the main.cpp and the testing header. For now, I have attached my modified main.cpp that includes the thread-safe spirit parser (I have not yet added the other two, do you want me to even bother?), and it includes the single line add in the main function "tests.reserve(150000);", which reserves just enough memory for your test file, now the loading function takes about half a second on my computer, instead of 9 seconds. Anyone else want to try the attached file and report the results as well as what platform and OS? I am on Windows XP using MSVC8 SP1. P.S. I would be quite happy if anyone could get rid of that freakishly long double->int64_t cast warning in the xpressive code, I like clean builds. :)
On 28 Jul 2009, at 08:16, OvermindDL1 wrote:
On Mon, Jul 27, 2009 at 10:34 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Mon, Jul 27, 2009 at 6:17 PM, OvermindDL1<overminddl1@gmail.com> wrote:
/* snip */
I did a quick first test at work, just a quick compile, got some errors, and quite frankly I do not know how this compiled in gcc either. First error is: 1>r:\programming_projects\spirit_price\price_parsing\main.cpp(545) : error C2373: '_input' : redefinition; different type modifiers 1> r:\programming_projects\spirit_price\price_parsing \main.cpp(544) : see declaration of '_input'
The relevant code is: template <class T> T extract(char const * & _input, char const * _description, std::string const & _input);
Why do the first and last function params have the same name (_input)? And which one is the real input? Based upon line 566, I changed the last _input to _value and that error (and one other) is now gone. Hmm, actually the third error is gone too. Now I am getting lots of Warnings (as errors since I by default have warnings treated as errors) about double to int64_t cast, both in your normal code on line 730
Also, I added a: tests.reserve(450000); right before the load_tests call, that changed the load_tests time from like 10 seconds to about 2 seconds on my system.
Also, why are you using time(0), that only has second accuracy?
The mailing list seems to be taking a very long while to send the message, so here it is again, but the attachment in the main.cpp file only, not the test_inputs.dat file (which, when zipped, is over 350kb). So get the test_inputs.dat from the link in the post prior to mine, and use the main.cpp that is attached to this post. Here is the message I sent as well, perhaps it will come through eventually:
Okay, I basically just copy/pasted my thread-safe version of my spirit parser over and ran it, it returned bad parse with like 13/9 or something like that. According to the documentation in the original cpp file, only "1", "1 2/3", or "1.2" are valid, not "2/3", so I changed it to support that and ran it again, it parsed successfully with all numbers in your tests matching successfully. Here is what it printed, using the horribly inaccurate time function: Testing string-based parsing Testing Xpressive-based parsing Testing Spirit-based parsing string parsing: 8s xpressive parsing: 33s spirit parsing: 6s
If you do not mind, I am going to add a millisecond accuracy testing framework (test.hpp from the boost examples) to the file and change all the nasty time calls to it for a more reliable reading.
OvermindDL1 - does my timer functionality not work? Can you try using that instead? If it's no good please let me know - and I can improve it. The whole point of the timer code is to obtain reliable confidence bounds for precisely this kind of optimisation application in an efficient manner. It hurts seeing absolute times used to compare things without any idea of their precision or accuracy! Cheers, -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
On Tue, Jul 28, 2009 at 3:11 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
On 28 Jul 2009, at 08:16, OvermindDL1 wrote:
On Mon, Jul 27, 2009 at 10:34 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Mon, Jul 27, 2009 at 6:17 PM, OvermindDL1<overminddl1@gmail.com> wrote:
/* snip */
I did a quick first test at work, just a quick compile, got some errors, and quite frankly I do not know how this compiled in gcc either. First error is: 1>r:\programming_projects\spirit_price\price_parsing\main.cpp(545) : error C2373: '_input' : redefinition; different type modifiers 1> r:\programming_projects\spirit_price\price_parsing\main.cpp(544) : see declaration of '_input'
The relevant code is: template <class T> T extract(char const * & _input, char const * _description, std::string const & _input);
Why do the first and last function params have the same name (_input)? And which one is the real input? Based upon line 566, I changed the last _input to _value and that error (and one other) is now gone. Hmm, actually the third error is gone too. Now I am getting lots of Warnings (as errors since I by default have warnings treated as errors) about double to int64_t cast, both in your normal code on line 730
Also, I added a: tests.reserve(450000); right before the load_tests call, that changed the load_tests time from like 10 seconds to about 2 seconds on my system.
Also, why are you using time(0), that only has second accuracy?
The mailing list seems to be taking a very long while to send the message, so here it is again, but the attachment in the main.cpp file only, not the test_inputs.dat file (which, when zipped, is over 350kb). So get the test_inputs.dat from the link in the post prior to mine, and use the main.cpp that is attached to this post. Here is the message I sent as well, perhaps it will come through eventually:
Okay, I basically just copy/pasted my thread-safe version of my spirit parser over and ran it, it returned bad parse with like 13/9 or something like that. According to the documentation in the original cpp file, only "1", "1 2/3", or "1.2" are valid, not "2/3", so I changed it to support that and ran it again, it parsed successfully with all numbers in your tests matching successfully. Here is what it printed, using the horribly inaccurate time function: Testing string-based parsing Testing Xpressive-based parsing Testing Spirit-based parsing string parsing: 8s xpressive parsing: 33s spirit parsing: 6s
If you do not mind, I am going to add a millisecond accuracy testing framework (test.hpp from the boost examples) to the file and change all the nasty time calls to it for a more reliable reading.
OvermindDL1 - does my timer functionality not work? Can you try using that instead? If it's no good please let me know - and I can improve it.
The whole point of the timer code is to obtain reliable confidence bounds for precisely this kind of optimisation application in an efficient manner.
It hurts seeing absolute times used to compare things without any idea of their precision or accuracy!
I have not seen how to use yours yet though, not actually looked at the code. To be honest, I am just lazy and using what I know involves one search-and-replace, and two lines of code changed. >.> I will make another set with your ejg timer now since I have time for once to play a bit. :) For now, I made one using the high_resolution_timer.hpp that comes with boost for examples and benchmarks and such. Attached is a zip of main.cpp and the high_resolution_timer.hpp (not the test data, it is too big to attach quickly). Here are the results on my computer: Testing string-based parsing Testing Xpressive-based parsing Testing Spirit-based parsing string parsing: 7.2406s xpressive parsing: 29.2227s spirit parsing: 5.07125s Yea, a lot more accurate, but still not good for direct comparison with other people like the ejg timer is, I shall make a modification with that next. :)
On Tue, Jul 28, 2009 at 4:15 AM, OvermindDL1<overminddl1@gmail.com> wrote:
On Tue, Jul 28, 2009 at 3:11 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
On 28 Jul 2009, at 08:16, OvermindDL1 wrote:
On Mon, Jul 27, 2009 at 10:34 PM, OvermindDL1<overminddl1@gmail.com> wrote:
On Mon, Jul 27, 2009 at 6:17 PM, OvermindDL1<overminddl1@gmail.com> wrote:
/* snip */
I did a quick first test at work, just a quick compile, got some errors, and quite frankly I do not know how this compiled in gcc either. First error is: 1>r:\programming_projects\spirit_price\price_parsing\main.cpp(545) : error C2373: '_input' : redefinition; different type modifiers 1> r:\programming_projects\spirit_price\price_parsing\main.cpp(544) : see declaration of '_input'
The relevant code is: template <class T> T extract(char const * & _input, char const * _description, std::string const & _input);
Why do the first and last function params have the same name (_input)? And which one is the real input? Based upon line 566, I changed the last _input to _value and that error (and one other) is now gone. Hmm, actually the third error is gone too. Now I am getting lots of Warnings (as errors since I by default have warnings treated as errors) about double to int64_t cast, both in your normal code on line 730
Also, I added a: tests.reserve(450000); right before the load_tests call, that changed the load_tests time from like 10 seconds to about 2 seconds on my system.
Also, why are you using time(0), that only has second accuracy?
The mailing list seems to be taking a very long while to send the message, so here it is again, but the attachment in the main.cpp file only, not the test_inputs.dat file (which, when zipped, is over 350kb). So get the test_inputs.dat from the link in the post prior to mine, and use the main.cpp that is attached to this post. Here is the message I sent as well, perhaps it will come through eventually:
Okay, I basically just copy/pasted my thread-safe version of my spirit parser over and ran it, it returned bad parse with like 13/9 or something like that. According to the documentation in the original cpp file, only "1", "1 2/3", or "1.2" are valid, not "2/3", so I changed it to support that and ran it again, it parsed successfully with all numbers in your tests matching successfully. Here is what it printed, using the horribly inaccurate time function: Testing string-based parsing Testing Xpressive-based parsing Testing Spirit-based parsing string parsing: 8s xpressive parsing: 33s spirit parsing: 6s
If you do not mind, I am going to add a millisecond accuracy testing framework (test.hpp from the boost examples) to the file and change all the nasty time calls to it for a more reliable reading.
OvermindDL1 - does my timer functionality not work? Can you try using that instead? If it's no good please let me know - and I can improve it.
The whole point of the timer code is to obtain reliable confidence bounds for precisely this kind of optimisation application in an efficient manner.
It hurts seeing absolute times used to compare things without any idea of their precision or accuracy!
I have not seen how to use yours yet though, not actually looked at the code. To be honest, I am just lazy and using what I know involves one search-and-replace, and two lines of code changed. >.>
I will make another set with your ejg timer now since I have time for once to play a bit. :)
For now, I made one using the high_resolution_timer.hpp that comes with boost for examples and benchmarks and such. Attached is a zip of main.cpp and the high_resolution_timer.hpp (not the test data, it is too big to attach quickly). Here are the results on my computer: Testing string-based parsing Testing Xpressive-based parsing Testing Spirit-based parsing string parsing: 7.2406s xpressive parsing: 29.2227s spirit parsing: 5.07125s
Yea, a lot more accurate, but still not good for direct comparison with other people like the ejg timer is, I shall make a modification with that next. :)
Ew! Warnings from the ejg files. My build log is even more polluted! ;-) Made a version of it using the ejg timer now, hope I did it well enough, mostly just a hack-in since the pre-existing system did not fit it well, but it compiles and runs and its result is (due note, I bumped down the default iterations from 100 to 1 so it actually executes today): Calibrating overhead......done Timer overhead (t_c) ~= : 14.6667 Jitter ~= : 0.633371 string vs Xpressive : 296.093 320.578 334.169% faster. Spirit vs Xpressive : 451.527 456.264 464.239% faster. Spirit vs string : 25.1096 28.8328 30.6562% faster. As you can see, string is vastly faster then Xpressive, Spirit is even more fast then Xpressive as compared to string, and Spirit is slightly faster (if you consider 28% to be marginally ;-) ) then string. For those of you unfamiliar with the ejg timer, it calculates certain factors as you can see first, it then performs multiple tests and iterations internally that will insure a *very* high degree of accuracy with testing. The three numbers are, in order, "min med max". Even looking at the min, Spirit is still over 25% faster then string (and that number is with an extremely high amount of statistical confidence). I use Boost.Bind to call the test function so that adds a bit of overhead, which could be noticeable on the faster thing like Spirit, so Spirit could potentially be even faster then the above test indicates. I would need to rewrite the whole tests to get rid of that restriction, and it may not even be a restriction, the compiler could have optimized it out, hmm, let me check the disassembly, nope it is not optimized out, so the tests could be rewritten better, perhaps I will do that later. Attached are all the files necessary in a zip, minus the test_inputs.dat file of course.
Yea, a lot more accurate, but still not good for direct comparison with other people like the ejg timer is, I shall make a modification with that next. :)
Ew! Warnings from the ejg files. My build log is even more polluted! ;-)
Hey - it compiles - one step at a time! ;-) Can you post the warnings? Today's warnings are tomorrows errors! I will attack them and hopefully iron them out - I too like clean build logs.
Made a version of it using the ejg timer now, hope I did it well enough, mostly just a hack-in since the pre-existing system did not fit it well, but it compiles and runs and its result is (due note, I bumped down the default iterations from 100 to 1 so it actually executes today):
You should only need 1 call. The timer code should work out how many iterations it needs in order to obtain a satisfactory answer. In fact, going crazy, you should be able to reliably measure the speedup of parsing a single character! ;-)
Calibrating overhead......done Timer overhead (t_c) ~= : 14.6667 Jitter ~= : 0.633371
If you're employing getticks from FFTW's cycle.h perhaps it's not returning actual clock ticks, (e.g. from a Pentium cycle counter). On my machine (Intel Core 2 - OS X) the timer overhead is ~109 ticks == 109 clock cycles.
string vs Xpressive : 296.093 320.578 334.169% faster. Spirit vs Xpressive : 451.527 456.264 464.239% faster. Spirit vs string : 25.1096 28.8328 30.6562% faster
[...]
accuracy with testing. The three numbers are, in order, "min med max".
You can read, for example the bottom line as: With a confidence of 95%, Spirit is at least 25% faster than string and at most 31% faster.
Even looking at the min, Spirit is still over 25% faster then string (and that number is with an extremely high amount of statistical confidence). I use Boost.Bind to call the test function so that adds a bit of overhead, which could be noticeable on the faster thing like Spirit, so Spirit could potentially be even faster then the above test indicates.
Do you think the overhead of calling through boost::bind could be comparable to the length of time it takes to run the function?
I would need to rewrite the whole tests to get rid of that restriction,
Looking at the following, testing::run_tests(std::string const & _description, tests_type const & _tests, Parser _parse, unsigned const _iterations) { //std::cout << "Testing " << _description << "-based parsing" << std::endl; _parse("0"); // prime the cache //util::high_resolution_timer t; for (unsigned i(0); _iterations > i; ++i) { for (tests_type::const_iterator it(_tests.begin()), end (_tests.end()); it != end; ++it) { std::string const & input(it->first); int64_t const expected(it->second); int64_t const actual(_parse(input)); if (actual != expected) { raise_parse_failed(expected, actual, input); } } } //return t.elapsed(); } I suggest something that simply iterates over the test data but does not check for correctness of parsing. Although it won't make a fat lot of difference in this case at least it's then consistent - you're timing the parsers not the tests for equality. The correctness test could then be done later once the timings are complete. Does the size of the test data set matter? In other words do you notice similar speedups if the test data will all fit in cache?
and it may not even be a restriction, the compiler could have optimized it out, hmm, let me check the disassembly, nope it is not optimized out, so the tests could be rewritten better, perhaps I will do that later.
I'd be interested to see if it is a problem. If it proves to be a significant I can add something that can account for overhead in 'shim' functions that are used as a call-through to bind arguments. I sincerely doubt the overhead is great - but you never know! Regards, -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
On Tue, Jul 28, 2009 at 6:32 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Yea, a lot more accurate, but still not good for direct comparison with other people like the ejg timer is, I shall make a modification with that next. :)
Ew! Warnings from the ejg files. My build log is even more polluted! ;-)
Hey - it compiles - one step at a time! ;-)
Can you post the warnings? Today's warnings are tomorrows errors! I will attack them and hopefully iron them out - I too like clean build logs.
Sure, let me separate yours out from that rather bloody massive warning that the xpressive code generates: 1>r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(468) : warning C4267: 'initializing' : conversion from 'size_t' to 'unsigned int', possible loss of data 1> r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(558) : see reference to function template instantiation 'ejg::timer_result_type &ejg::generic_timer<ticks>::measure_execution_result<_Operation>(_Operation,ejg::timer_result_type &)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _Operation=boost::_bi::bind_t<double,double (__cdecl *)(const std::string &,const testing::tests_type &,xpressive_parsing::parser,unsigned int),boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<xpressive_parsing::parser>,boost::_bi::value<unsigned int>>> 1> ] 1> r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(242) : see reference to function template instantiation 'double ejg::generic_timer<ticks>::measure_execution_time<_OperationB>(_Operation)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _OperationB=boost::_bi::bind_t<double,double (__cdecl *)(const std::string &,const testing::tests_type &,xpressive_parsing::parser,unsigned int),boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<xpressive_parsing::parser>,boost::_bi::value<unsigned int>>>, 1> _Operation=boost::_bi::bind_t<double,double (__cdecl *)(const std::string &,const testing::tests_type &,xpressive_parsing::parser,unsigned int),boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<xpressive_parsing::parser>,boost::_bi::value<unsigned int>>> 1> ] 1> r:\programming_projects\spirit_price\price_parsing\main.cpp(302) : see reference to function template instantiation 'void ejg::generic_timer<ticks>::measure_percentage_speedup<boost::_bi::bind_t<R,F,L>,boost::_bi::bind_t<R,double (__cdecl *)(const std::string &,const testing::tests_type &,Parser,unsigned int),boost::_bi::list4<A1,A2,A3,A4>>>(_OperationA,_OperationB,double &,double &,double &)' being compiled 1> with 1> [ 1> ticks=ticks, 1> R=double, 1> F=double (__cdecl *)(const std::string &,const testing::tests_type &,string_parsing::parser,unsigned int), 1> L=boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<string_parsing::parser>,boost::_bi::value<unsigned int>>, 1> Parser=xpressive_parsing::parser, 1> A1=boost::_bi::value<const char *>, 1> A2=boost::_bi::value<testing::tests_type>, 1> A3=boost::_bi::value<xpressive_parsing::parser>, 1> A4=boost::_bi::value<unsigned int>, 1> _OperationA=boost::_bi::bind_t<double,double (__cdecl *)(const std::string &,const testing::tests_type &,string_parsing::parser,unsigned int),boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<string_parsing::parser>,boost::_bi::value<unsigned int>>>, 1> _OperationB=boost::_bi::bind_t<double,double (__cdecl *)(const std::string &,const testing::tests_type &,xpressive_parsing::parser,unsigned int),boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<xpressive_parsing::parser>,boost::_bi::value<unsigned int>>> 1> ] 1>r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(468) : warning C4267: 'initializing' : conversion from 'size_t' to 'unsigned int', possible loss of data 1> r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(558) : see reference to function template instantiation 'ejg::timer_result_type &ejg::generic_timer<ticks>::measure_execution_result<_Operation>(_Operation,ejg::timer_result_type &)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _Operation=boost::_bi::bind_t<double,double (__cdecl *)(const std::string &,const testing::tests_type &,string_parsing::parser,unsigned int),boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<string_parsing::parser>,boost::_bi::value<unsigned int>>> 1> ] 1> r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(249) : see reference to function template instantiation 'double ejg::generic_timer<ticks>::measure_execution_time<_OperationA>(_Operation)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _OperationA=boost::_bi::bind_t<double,double (__cdecl *)(const std::string &,const testing::tests_type &,string_parsing::parser,unsigned int),boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<string_parsing::parser>,boost::_bi::value<unsigned int>>>, 1> _Operation=boost::_bi::bind_t<double,double (__cdecl *)(const std::string &,const testing::tests_type &,string_parsing::parser,unsigned int),boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<string_parsing::parser>,boost::_bi::value<unsigned int>>> 1> ] 1>r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(468) : warning C4267: 'initializing' : conversion from 'size_t' to 'unsigned int', possible loss of data 1> r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(558) : see reference to function template instantiation 'ejg::timer_result_type &ejg::generic_timer<ticks>::measure_execution_result<_Operation>(_Operation,ejg::timer_result_type &)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _Operation=boost::_bi::bind_t<double,double (__cdecl *)(const std::string &,const testing::tests_type &,spirit_parsing::parser,unsigned int),boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<spirit_parsing::parser>,boost::_bi::value<unsigned int>>> 1> ] 1> r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(249) : see reference to function template instantiation 'double ejg::generic_timer<ticks>::measure_execution_time<_OperationA>(_Operation)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _OperationA=boost::_bi::bind_t<double,double (__cdecl *)(const std::string &,const testing::tests_type &,spirit_parsing::parser,unsigned int),boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<spirit_parsing::parser>,boost::_bi::value<unsigned int>>>, 1> _Operation=boost::_bi::bind_t<double,double (__cdecl *)(const std::string &,const testing::tests_type &,spirit_parsing::parser,unsigned int),boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<spirit_parsing::parser>,boost::_bi::value<unsigned int>>> 1> ] 1> r:\programming_projects\spirit_price\price_parsing\main.cpp(309) : see reference to function template instantiation 'void ejg::generic_timer<ticks>::measure_percentage_speedup<boost::_bi::bind_t<R,F,L>,boost::_bi::bind_t<R,double (__cdecl *)(const std::string &,const testing::tests_type &,Parser,unsigned int),boost::_bi::list4<A1,A2,A3,A4>>>(_OperationA,_OperationB,double &,double &,double &)' being compiled 1> with 1> [ 1> ticks=ticks, 1> R=double, 1> F=double (__cdecl *)(const std::string &,const testing::tests_type &,spirit_parsing::parser,unsigned int), 1> L=boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<spirit_parsing::parser>,boost::_bi::value<unsigned int>>, 1> Parser=xpressive_parsing::parser, 1> A1=boost::_bi::value<const char *>, 1> A2=boost::_bi::value<testing::tests_type>, 1> A3=boost::_bi::value<xpressive_parsing::parser>, 1> A4=boost::_bi::value<unsigned int>, 1> _OperationA=boost::_bi::bind_t<double,double (__cdecl *)(const std::string &,const testing::tests_type &,spirit_parsing::parser,unsigned int),boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<spirit_parsing::parser>,boost::_bi::value<unsigned int>>>, 1> _OperationB=boost::_bi::bind_t<double,double (__cdecl *)(const std::string &,const testing::tests_type &,xpressive_parsing::parser,unsigned int),boost::_bi::list4<boost::_bi::value<const char *>,boost::_bi::value<testing::tests_type>,boost::_bi::value<xpressive_parsing::parser>,boost::_bi::value<unsigned int>>> 1> ] 1>r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(468) : warning C4267: 'initializing' : conversion from 'size_t' to 'unsigned int', possible loss of data 1> r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(558) : see reference to function template instantiation 'ejg::timer_result_type &ejg::generic_timer<ticks>::measure_execution_result<_LARGE_INTEGER(__cdecl *)(void)>(_Operation,ejg::timer_result_type &)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _Operation=_LARGE_INTEGER (__cdecl *)(void) 1> ] 1> r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(166) : see reference to function template instantiation 'double ejg::generic_timer<ticks>::measure_execution_time<_LARGE_INTEGER(__cdecl *)(void)>(_Operation)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _Operation=_LARGE_INTEGER (__cdecl *)(void) 1> ] 1> r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(92) : see reference to function template instantiation 'void ejg::generic_timer<ticks>::measure_infinity_time<_LARGE_INTEGER(__cdecl *)(void)>(_Operation,double &,double &,double &,size_t)' being compiled 1> with 1> [ 1> ticks=ticks, 1> _Operation=_LARGE_INTEGER (__cdecl *)(void) 1> ] 1> r:\programming_projects\spirit_price\price_parsing\other_includes\ejg\timer.cpp(80) : while compiling class template member function 'void ejg::generic_timer<ticks>::calibrate_chrono_overhead(void)' 1> with 1> [ 1> ticks=ticks 1> ] 1> r:\programming_projects\spirit_price\price_parsing\main.cpp(279) : see reference to class template instantiation 'ejg::generic_timer<ticks>' being compiled 1> with 1> [ 1> ticks=ticks 1> ] On Tue, Jul 28, 2009 at 6:32 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Made a version of it using the ejg timer now, hope I did it well enough, mostly just a hack-in since the pre-existing system did not fit it well, but it compiles and runs and its result is (due note, I bumped down the default iterations from 100 to 1 so it actually executes today):
You should only need 1 call. The timer code should work out how many iterations it needs in order to obtain a satisfactory answer. In fact, going crazy, you should be able to reliably measure the speedup of parsing a single character! ;-)
Which is how I understood it, which is why I turned it down to 1 iteration. :) On Tue, Jul 28, 2009 at 6:32 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Calibrating overhead......done Timer overhead (t_c) ~= : 14.6667 Jitter ~= : 0.633371
If you're employing getticks from FFTW's cycle.h perhaps it's not returning actual clock ticks, (e.g. from a Pentium cycle counter).
On my machine (Intel Core 2 - OS X) the timer overhead is ~109 ticks == 109 clock cycles.
I am using the cycle.h file, and I am pretty sure it was... On Tue, Jul 28, 2009 at 6:32 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Do you think the overhead of calling through boost::bind could be comparable to the length of time it takes to run the function?
No, I just tested, it is negligeable On Tue, Jul 28, 2009 at 6:32 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
I suggest something that simply iterates over the test data but does not check for correctness of parsing. Although it won't make a fat lot of difference in this case at least it's then consistent - you're timing the parsers not the tests for equality. The correctness test could then be done later once the timings are complete.
I actually already did that, however I kept getting warnings about the measure_percentage_speedup function not being able to do something with the template arguments for the function calls, which were just standard void(void) functions, confuzzling. May look at that later, almost bed time. On Tue, Jul 28, 2009 at 6:32 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Does the size of the test data set matter? In other words do you notice similar speedups if the test data will all fit in cache?
His input data is a very detailed test that tests just about every possible input, which can have different speeds for different ones, so I think it would be a good overall test to keep and parse all 147k values, perhaps if there was some way to test them all individually using ejg and get a nice report? ;-)
On Tue, Jul 28, 2009 at 6:44 AM, Stewart, Robert<Robert.Stewart@sig.com> wrote:
P.S. I would be quite happy if anyone could get rid of that freakishly long double->int64_t cast warning in the xpressive code, I like clean builds. :)
I don't get the warning, so you'll have to be more specific.
Here are the warnings I get, there are two, the first is plain and basic: 1>r:\programming_projects\spirit_price\price_parsing\main.cpp(789) : warning C4244: '=' : conversion from 'const boost::int64_t' to 'double', possible loss of data Although this is with the above ejg file set I posted so the line number might be wrong, the line of code is: value = _result / denominator; The other warning is apparently a single xpressive warning about a conversion from int64_t to double. The line of code in main.hpp it references is: const sregex price = *blank >> !sign >> (real | mixed_number | fraction | integer) >> *space; And the long error is (this outdoes even the sizable spirit error message ;-) How I wish we were getting concepts in C++1x, I still do not understand why they took it out): Hmm, apparently too big to post on this list (over 800kb, yes, for one error message from xpressive). I put it in a text file, zipped it up, and attached it, now 6kb.
OvermindDL1 wrote:
On Tue, Jul 28, 2009 at 6:44 AM, Stewart, Robert<Robert.Stewart@sig.com> wrote:
P.S. I would be quite happy if anyone could get rid of that freakishly long double->int64_t cast warning in the xpressive code, I like clean builds. :)
I don't get the warning, so you'll have to be more specific.
Here are the warnings I get, there are two, the first is plain and basic: 1>r:\programming_projects\spirit_price\price_parsing\main.cpp(789) : warning C4244: '=' : conversion from 'const boost::int64_t' to 'double', possible loss of data
Although this is with the above ejg file set I posted so the line number might be wrong, the line of code is: value = _result / denominator;
Hmmm, the only warnings I ever got were from double to int64_t. There is, of course, a precision issue between the two types, but they don't apply to this context, so simply change the line to: value = static_cast<double>(_result / denominator);
The other warning is apparently a single xpressive warning about a conversion from int64_t to double. The line of code in main.hpp it references is: const sregex price = *blank >> !sign >> (real | mixed_number | fraction | integer) >> *space;
And the long error is (this outdoes even the sizable spirit error message ;-) How I wish we were getting concepts in C++1x, I still do not understand why they took it out):
There was still a lot of experimentation, discussion, and twiddling going on. Read http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2009/n2906.pdf. Better to get everything else out the door sooner than later.
Hmm, apparently too big to post on this list (over 800kb, yes, for one error message from xpressive). I put it in a text file, zipped it up, and attached it, now 6kb.
I'm not certain what is causing that warning. I have three suggestions: 1. In xpressive_parsing::to_price_impl::operator ()(Value const &, Value const &), change "lcm.as<double>() * numerator / denominator" to "lcm.as<double>() * static_cast<double>(numerator) / static_cast<double>(denominator)" (Perhaps only one cast is actually needed) 2. In xpressive_parsing::to_price_impl::operator ()(Value const &, double), change "lcm.as<double>() * whole + _fraction" to "lcm.as<double>() * static_cast<double>(whole) + static_cast<double>(_fraction)" (Perhaps only one cast is actually needed) 3. Simplify the regex to isolate the source. Remove ">> (real | mixed_number | fraction | integer)" first. If that eliminates the warning, then put ">> real" back in. If still no warning, change it to ">> (real | mixed_number)," etc. _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.
Can you post the warnings? Today's warnings are tomorrows errors! I will attack them and hopefully iron them out - I too like clean build logs.
Sure, let me separate yours out from that rather bloody massive warning that the xpressive code generates: 1>r:\programming_projects\spirit_price\price_parsing\other_includes \ejg\timer.cpp(468) : warning C4267: 'initializing' : conversion from 'size_t' to 'unsigned int', possible loss of data 1> r:\programming_projects\spirit_price\price_parsing \other_includes\ejg\timer.cpp(558) : see reference to function template instantiation 'ejg::timer_result_type &ejg::generic_timer<ticks>::measure_execution_result<_Operation> (_Operation,ejg::timer_result_type
[... more reams of stuff... ] Someone on this list mentioned something about intractable template warnings.... ...I can't imagine what the fuss is about. It looks like a subtle interaction with boost::bind and the expected form of the functor f() which is marvellously non-specific about any return types. I will take a look later...
You should only need 1 call. The timer code should work out how many iterations it needs in order to obtain a satisfactory answer. In fact, going crazy, you should be able to reliably measure the speedup of parsing a single character! ;-)
Which is how I understood it, which is why I turned it down to 1 iteration. :)
Good show.
Calibrating overhead......done Timer overhead (t_c) ~= : 14.6667 Jitter ~= : 0.633371
If you're employing getticks from FFTW's cycle.h perhaps it's not returning actual clock ticks, (e.g. from a Pentium cycle counter).
On my machine (Intel Core 2 - OS X) the timer overhead is ~109 ticks == 109 clock cycles.
I am using the cycle.h file, and I am pretty sure it was...
Ok.
Do you think the overhead of calling through boost::bind could be comparable to the length of time it takes to run the function?
No, I just tested, it is negligeable
Good! One less thing to worry about.
On Tue, Jul 28, 2009 at 6:32 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
I suggest something that simply iterates over the test data but does not check for correctness of parsing. Although it won't make a fat lot of difference in this case at least it's then consistent - you're timing the parsers not the tests for equality. The correctness test could then be done later once the timings are complete.
I actually already did that, however I kept getting warnings about the measure_percentage_speedup function not being able to do something with the template arguments for the function calls, which were just standard void(void) functions, confuzzling. May look at that later, almost bed time.
"Confuzzling" - I like that. Perhaps boost::bind gets up to some mischief. Let me know how you get on. I'm still trying to figure out why the tests I ran yielded a ~10x speedup for Spirit. Perhaps you could try a more canonical test - running "ejg_uint_parser_0_0_4.cpp" http://tinyurl.com/lro5ok That does not make use of boost::bind - but tries to avoid the optimizer getting rid of void(void) functions by using globals.
Does the size of the test data set matter? In other words do you notice similar speedups if the test data will all fit in cache?
His input data is a very detailed test that tests just about every possible input, which can have different speeds for different ones, so I think it would be a good overall test to keep and parse all 147k values, perhaps if there was some way to test them all individually using ejg and get a nice report? ;-)
Perhaps (one day) it could be informative to test subsets of the data. For example you may find Spirit is unusually slow at parsing certain patterns e.g. "2222" is 20% slower than "1111" - this could (speculatively) point towards some deep and subtle changes that could be made. From what I've seen so far however there's plenty of work to be done on Xpressive in closing the existing performance gap. ;-) Cheers, -ed
On Tue, Jul 28, 2009 at 7:35 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Perhaps you could try a more canonical test - running "ejg_uint_parser_0_0_4.cpp"
That does not make use of boost::bind - but tries to avoid the optimizer getting rid of void(void) functions by using globals.
I have no clue why I am still awake, brain is already shut down, code is a blurry blob to me right now, but I still compiled and ran your latest file. :) The results: initializing input strings... Calibrating overhead......done Timer overhead (t_c) ~= : 12 Jitter ~= : 8.43769e-015 qi_parse vs atoi : 1381.05 1385.57 1389.6% faster. qi_parse vs strtol : 1365.82 1389.6 1597.94% faster. strtol vs atoi : 1.03202 1.04052 10.6428% faster. qi_parse vs qi_parse : 0 0 0% faster. Checking that the results are correct... atoi is behaving itself! strtol is behaving itself! qi is behaving itself! All done!
That does not make use of boost::bind - but tries to avoid the optimizer getting rid of void(void) functions by using globals.
I have no clue why I am still awake, brain is already shut down, code is a blurry blob to me right now, but I still compiled and ran your latest file. :)
Thanks.
The results:
initializing input strings... Calibrating overhead......done Timer overhead (t_c) ~= : 12 Jitter ~= : 8.43769e-015 qi_parse vs atoi : 1381.05 1385.57 1389.6% faster. qi_parse vs strtol : 1365.82 1389.6 1597.94% faster. strtol vs atoi : 1.03202 1.04052 10.6428% faster. qi_parse vs qi_parse : 0 0 0% faster.
Hmmm.... So you observe the same as me. Spirit2 ~1000% faster than the basic libraries as opposed to 25% faster from the previous tests. "Curiouser and curiouser" said Alice. -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
On Tue, Jul 28, 2009 at 8:49 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
That does not make use of boost::bind - but tries to avoid the optimizer getting rid of void(void) functions by using globals.
I have no clue why I am still awake, brain is already shut down, code is a blurry blob to me right now, but I still compiled and ran your latest file. :)
Thanks.
The results:
initializing input strings... Calibrating overhead......done Timer overhead (t_c) ~= : 12 Jitter ~= : 8.43769e-015 qi_parse vs atoi : 1381.05 1385.57 1389.6% faster. qi_parse vs strtol : 1365.82 1389.6 1597.94% faster. strtol vs atoi : 1.03202 1.04052 10.6428% faster. qi_parse vs qi_parse : 0 0 0% faster.
Hmmm.... So you observe the same as me. Spirit2 ~1000% faster than the basic libraries as opposed to 25% faster from the previous tests.
"Curiouser and curiouser" said Alice.
Heh, when my brain is functional again, if I remember (or if I am reminded by this email) I will run it through a profiler and see what is going on as well as looking at the disassembly to see what kind of code it all creates. It is definitely odd though, if Spirit2.1 really is faster, then you would think the compiler library programmers would do a better job then what they are currently doing. I am really curious to find out what is going on, hopefully delving into assembly later will shed some light.
Heh, when my brain is functional again, if I remember (or if I am reminded by this email) I will run it through a profiler and see what is going on as well as looking at the disassembly to see what kind of code it all creates.
That would be very instructive - not something I'm really much good at anymore....
Cheers, -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
On Tue, Jul 28, 2009 at 9:00 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Heh, when my brain is functional again, if I remember (or if I am reminded by this email) I will run it through a profiler and see what is going on as well as looking at the disassembly to see what kind of code it all creates.
That would be very instructive - not something I'm really much good at anymore....
I used to do it all the time, editing disassembly to make programs do other things was always fun. :) Been a while though. I do not think I have the cognitive capabilities to be able to read assembler at the moment, but I went ahead and profiled the application, results are attached to preserve formatting.
On Tue, Jul 28, 2009 at 9:05 AM, OvermindDL1<overminddl1@gmail.com> wrote:
On Tue, Jul 28, 2009 at 9:00 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Heh, when my brain is functional again, if I remember (or if I am reminded by this email) I will run it through a profiler and see what is going on as well as looking at the disassembly to see what kind of code it all creates.
That would be very instructive - not something I'm really much good at anymore....
I used to do it all the time, editing disassembly to make programs do other things was always fun. :) Been a while though.
I do not think I have the cognitive capabilities to be able to read assembler at the moment, but I went ahead and profiled the application, results are attached to preserve formatting.
Well, atoi's assembly is a function call, no inlining there... And strtol in assembly is a function call too, no inlining or anything fancy. And heh, Spirit is completely inlined except for the call to boost::spirit::qi::detail::extract_int<int,10,1,-1,etc... However that function is only called the very first time that function is called. Remember that Spirit increments the passed in iterator, so all the start iterators in that vector ended up being incremented to be equal to the last iterator. :p I change the wrap_qi_parse function to this (introduced a temporary so the temporary is incremented instead of the thing you have stored in the vector): void wrap_qi_parse() { for (int i = 0; i < BUFFER_SIZE; ++i) { char const *iter = f[i]; qi::parse(iter, l[i], int_, v[i]); } } When I compile and run the tests now, I get this: initializing input strings... Calibrating overhead......done Timer overhead (t_c) ~= : 12 Jitter ~= : 8.43769e-015 qi_parse vs atoi : 170.429 170.438 170.482% faster. qi_parse vs strtol : 167.589 167.601 167.668% faster. strtol vs atoi : 1.04669 1.05746 1.06165% faster. qi_parse vs qi_parse : 0 0 0% faster. Checking that the results are correct... atoi is behaving itself! strtol is behaving itself! qi is behaving itself! All done! That is a *lot* more reasonable, although Spirit is still most definitely faster then the built-in functions. :) Heh, what do you know, my shut down brain still had some living brain cells. I have actually found that I, oddly, do my best debugging when really tired, at least when I was younger, guess I still do. :)
And heh, Spirit is completely inlined except for the call to boost::spirit::qi::detail::extract_int<int,10,1,-1,etc... However that function is only called the very first time that function is called. Remember that Spirit increments the passed in iterator, so all the start iterators in that vector ended up being incremented to be equal to the last iterator. :p
When you write the above, do you mean ** -> my change
However that function is only called the very first time *qi::parse* is called. Remember that Spirit increments the passed in iterator, so
In other words only the first call does anything - repeated calls to qi::parse do nothing because the iterator is already at the end? Good catch.
I change the wrap_qi_parse function to this (introduced a temporary so the temporary is incremented instead of the thing you have stored in the vector): void wrap_qi_parse() { for (int i = 0; i < BUFFER_SIZE; ++i) { char const *iter = f[i]; qi::parse(iter, l[i], int_, v[i]); }
}
When I compile and run the tests now, I get this: initializing input strings... Calibrating overhead......done Timer overhead (t_c) ~= : 12 Jitter ~= : 8.43769e-015 qi_parse vs atoi : 170.429 170.438 170.482% faster. qi_parse vs strtol : 167.589 167.601 167.668% faster. strtol vs atoi : 1.04669 1.05746 1.06165% faster. qi_parse vs qi_parse : 0 0 0% faster.
Checking that the results are correct... atoi is behaving itself! strtol is behaving itself! qi is behaving itself!
Good stuff. Thanks. I might just re-jig that to try and make use of boost::bind instead of that bad roll-your-own wrapper function. What's needed is a 'fire and forget' wrapping technique that can be applied to arbitrary functions and still give sensible answers.
That is a *lot* more reasonable, although Spirit is still most definitely faster then the built-in functions. :)
That's good though - one up for Boost!
Heh, what do you know, my shut down brain still had some living brain cells. I have actually found that I, oddly, do my best debugging when really tired, at least when I was younger, guess I still do. :)
It's amazing what the promise of imminent sleep can do to motivate a battered cerebral cortex. It's only playing along because it knows it's the only way it'll get to rest! -ed
Edward Grace wrote:
That is a *lot* more reasonable, although Spirit is still most definitely faster then the built-in functions. :)
That's good though - one up for Boost!
My latest benchmarks for integers and floating points reveal a 3x speed over atoi/strtol and friend C functions. You mentioned a need to parse small numbers very quickly? Spirit does. The tests I have take that into consideration too. If you guys want to take a peek, it's in the Boost trunk in libs/benchmarks. Some numbers: /////////////////////////////////////////////////////////////////////////// atoi_test: 0.9265067422 [s] {checksum: d5b76d60} strtol_test: 1.0766213977 [s] {checksum: d5b76d60} spirit_int_test: 0.3097019879 [s] {checksum: d5b76d60} /////////////////////////////////////////////////////////////////////////// atof_test: 7.3012049917 [s] {checksum: 3b7d82b0} strtod_test: 8.0042894122 [s] {checksum: 3b7d82b0} spirit_double_test: 2.6729373333 [s] {checksum: 3b7d82b0} This time, I am using the benchmarking harness by David Abrahams, Matthias Troyer, Michael Gauckler. It's the one used in timing the overhead of Boost.Parameter. You are welcome to try it out with your timer, Edward. Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
On 28 Jul 2009, at 18:17, Joel de Guzman wrote:
Edward Grace wrote:
That is a *lot* more reasonable, although Spirit is still most definitely faster then the built-in functions. :)
That's good though - one up for Boost!
My latest benchmarks for integers and floating points reveal a 3x speed over atoi/strtol and friend C functions. You mentioned a need to parse small numbers very quickly? Spirit does. The tests I have take that into consideration too. If you guys want to take a peek, it's in the Boost trunk in libs/benchmarks.
Sure. Can you give me an exact url? The last time I went on a code hunt in SVN I found the wrong thing.
Some numbers:
////////////////////////////////////////////////////////////////////// ///// atoi_test: 0.9265067422 [s] {checksum: d5b76d60} strtol_test: 1.0766213977 [s] {checksum: d5b76d60} spirit_int_test: 0.3097019879 [s] {checksum: d5b76d60}
////////////////////////////////////////////////////////////////////// ///// atof_test: 7.3012049917 [s] {checksum: 3b7d82b0} strtod_test: 8.0042894122 [s] {checksum: 3b7d82b0} spirit_double_test: 2.6729373333 [s] {checksum: 3b7d82b0}
This time, I am using the benchmarking harness by David Abrahams, Matthias Troyer, Michael Gauckler.
This? http://tinyurl.com/kk858o There's some interesting trickery in there by the looks of things for eliminating the optimiser nastiness - that's not something I've thought about much I'll take a look. In the comments, 42 // operation to at least update the L1 cache. *** Note: This 43 // concern is specific to the particular application at which 44 // we're targeting the test. *** that seems quite important but a little opaque out of context. One thing I take exception to is the (effective) use of the mean as a measurement of central tendency - perhaps their trickery has eliminated the heavy tail. I'll have to take a look and see how it compares to my approach. How do your relative timings compare if you repeat them while (say) watching a DVD? [*]
It's the one used in timing the overhead of Boost.Parameter. You are welcome to try it out with your timer, Edward.
Likewise, can you be specific about where to look? Thanks for flagging this up by the way - who knows maybe I've been reinventing the wheel! Cheers, -ed [*] This may seem a perverse question. I'm interested in robust performance measurement, in other words accurately working out which function is fastest while the machine is under choppy loading -- not a sanitised testing environment - so the fastest function can be selected by the code itself. ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
on Tue Jul 28 2009, Edward Grace <ej.grace-AT-imperial.ac.uk> wrote:
This?
There's some interesting trickery in there by the looks of things for eliminating the optimiser nastiness - that's not something I've thought about much I'll take a look.
In the comments,
42 // operation to at least update the L1 cache. *** Note: This 43 // concern is specific to the particular application at which 44 // we're targeting the test. ***
that seems quite important but a little opaque out of context.
It means the application we were going to use this technique on was going to update a long series of accumulators, which will certainly not fit in a few registers. We wanted to force the test to reflect that reality.
One thing I take exception to is the (effective) use of the mean as a measurement of central tendency
Why?
- perhaps their trickery has eliminated the heavy tail.
Why would one assume there is a heavy tail in the first place? -- Dave Abrahams BoostPro Computing http://www.boostpro.com
42 // operation to at least update the L1 cache. *** Note: This 43 // concern is specific to the particular application at which 44 // we're targeting the test. ***
that seems quite important but a little opaque out of context.
It means the application we were going to use this technique on was going to update a long series of accumulators, which will certainly not fit in a few registers. We wanted to force the test to reflect that reality.
Ah, I did some hunting and found things for the iterative calculation of the mean - presumably this is an embodiment of the original application. How various caches interact is not something I've given a great deal of thought to. In practice it can presumably make or break the real 'speed' of something. I can see that there's a great difference in timing a large bunch of iterations of the same thing one after another and the actual typical execution characteristics of the same function in a different context. This kind of thing is something I have to shrug my shoulders at - I can see it's a potential issue but don't know enough to comment.
One thing I take exception to is the (effective) use of the mean as a measurement of central tendency
Why?
The mean is not a robust measure of central tendency. Robust, in this context, means that a single arbitrarily large observation can shift the estimator (the mean in this case) arbitrarily far. The median on the other hand is robust, a single arbitrarily large observation may not move the median at all. Technically the 'breakdown point' of the mean is zero. For the obligatory Wikipedia overview see: http://tinyurl.com/l4vldr
- perhaps their trickery has eliminated the heavy tail.
Why would one assume there is a heavy tail in the first place?
Informally speaking one may expect the OS to very-very occasionally interrupt a running function that nominally takes (say) 100 cycles and run of to do some disk IO. That delay may will run into hundreds of millions of clock cycles. Consequently that observation may differ from all the others by (say) six orders of magnitude. Most probably of course that will not occur; that's a long tail - very rare events of extreme magnitude. A bit like returns in stock market crashes only less frequent. ;-) Less informally I've measured it! On a log-log histogram plot of ~10^7 measurements even trivial functions display a definite hint of Pareto-like [ http://tinyurl.com/ngnyk2 ] behaviour in the wings. -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Edward Grace wrote:
On 28 Jul 2009, at 18:17, Joel de Guzman wrote:
This time, I am using the benchmarking harness by David Abrahams, Matthias Troyer, Michael Gauckler.
This?
There's some interesting trickery in there by the looks of things for eliminating the optimiser nastiness - that's not something I've thought about much I'll take a look.
The technique of using an accumulator to keep the whole system "plugged" is one of the ideas you can use versus the need for global variables, volatile, etc. This comment and code returning from main says a lot: // This is ultimately responsible for preventing all the test code // from being optimized away. Change this to return 0 and you // unplug the whole test's life support system. return test::live_code != 0; Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
This?
There's some interesting trickery in there by the looks of things for eliminating the optimiser nastiness - that's not something I've thought about much I'll take a look.
The technique of using an accumulator to keep the whole system "plugged" is one of the ideas you can use versus the need for global variables, volatile, etc.
I'm clearly going to have to ponder this in some depth. While I've thought about trying to get the maths (statistics) right, I've not really given the nitty gritty of the machine's operation a great deal of thought. Then again, that's the whole point of engaging in discussion on this mailing list!
This comment and code returning from main says a lot:
// This is ultimately responsible for preventing all the test code // from being optimized away. Change this to return 0 and you // unplug the whole test's life support system. return test::live_code != 0;
Indeed, I'd spotted that. It's a nice comment! ;-) -ed
Edward Grace wrote:
This?
There's some interesting trickery in there by the looks of things for eliminating the optimiser nastiness - that's not something I've thought about much I'll take a look.
The technique of using an accumulator to keep the whole system "plugged" is one of the ideas you can use versus the need for global variables, volatile, etc.
I'm clearly going to have to ponder this in some depth. While I've thought about trying to get the maths (statistics) right, I've not really given the nitty gritty of the machine's operation a great deal of thought.
Well, there you have it. I'd love to have your expertise on statistics plus Matthias Troyer, et al. test harness be combined in an easy to use benchmarking library. Benchmarking is such a black art :-) ! Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
I'm clearly going to have to ponder this in some depth. While I've thought about trying to get the maths (statistics) right, I've not really given the nitty gritty of the machine's operation a great deal of thought.
Well, there you have it. I'd love to have your expertise on statistics
I claim none! I've been trying to learn as I go - perhaps a little knowledge is a dangerous thing!
plus Matthias Troyer, et al. test harness be combined in an easy to use benchmarking library.
Be careful what you wish for, it might come true... ;-)
Benchmarking is such a black art :-) !
I totally agree! Like presumably many others, this appeared to me to be a trivial problem - at first sight. In fact it's anything but straightforward. I bet there are half a dozen or so PhDs sitting in this particular dark recess of computing. -ed
On Wed, Jul 29, 2009 at 9:17 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
it seems (you said you were using GCC yes?).
Yes.... I wonder why am I starting to feel sheepish about that...
Heh, I do have cygwin completely installed and fully updated on my computer here (the recommended beta version that uses gcc 4.3 as I recall) and I do have boost trunk (from a couple weeks ago anyway) in there and compiled for it. If you can tell me what command I need to type to compile the file with all necessary optimizations, I will do that here too.
Hi, assuming:
* Your homed directory is $HOME * Spirit2 is in $HOME/spirit21_root, which should contain boost/spirit/actor.hpp * The latest Boost is in $HOME/boost_root, which should contain boost/any.hpp * cycle.h is in the same directory as the file ejg_uint_parser_0_0_4_bind_1.cpp * The ejg timer stuff is in $HOME/ejg_root, this should contain ejg/timer.hpp
the following stanza will work in bash (note the backslashes to break the line), first we define some environment variables for legibility, then fire up g++,
# ------ cut -----
SPIRIT2=$HOME/spirit21_root BOOST=$HOME/boost_root EJG=$HOME/ejg_root
g++ -DNDEBUG -O3 -ansi -pedantic -Wall -Wno-long-long -Werror \ -I$SPIRIT2 -I$BOOST -I$EJG -o ejg_uint_parser \ ejg_uint_parser_0_0_4_bind_1.cpp
# ----- cut -------
The following is a synopsis of what the bits mean, in case it's not obvious.
-DNDEBUG -> equivalent to #define NDEBUG, should switch off any debug parts of Boost -O3 -> Optimisation level 3 - pretty much all in! -ansi -> Require ANSI compliance of the language! -pedantic -> Really really mean it! -Wall -> Warn about everything (alegedly) -Wno-long-long -> Do not warn about long long not being a mandated C++ standard type. -Werror -> Convert warnings to errors -I<blah> -> Include <blah> as a directory to search for include files along with the standard locations. -o <blah> -> Generate the binary file <blah>
I often forget about -DNDEBUG - this can have a significant impact ~10% for Spirit2 over atoi. Presumably you define NDEBUG when compiling on Windows (or is that automatically assumed for 'Release' builds?).
Since I will be running it on the exact same computer with the same OS, but different compilers, that will prove if it really is GCC being much slower then VC, or if they are near the same on my computer, then it is something else.
I await with trepidation....
Very useful info, thanks. I altered slightly to support my setup, since boost trunk is in the /etc/usr/lib or something like that, it is picked up globally. I tried compiling it multiple times, got the same warning each time, never could find the output file. Here is my latest attempt, I tried fully qualified names, did not help: OvermindDL1@overmind /cygdrive/s/cygwin/home/OvermindDL1/ejg_test $ g++ -DNDEBUG -O3 -ansi -pedantic -Wall -Wno-long-long -Werror -I/cygdrive/s/cygwin/home/OvermindDL1/ejg_test/other_includes -o /cygdrive/s/cygwin/home/OvermindDL1/ejg_test/ejg_uint_parser ejg_uint_parser_0_0_4_bind_1.cpp /usr/lib/gcc/i686-pc-cygwin/3.4.4/include/c++/bits/stl_uninitialized.h: In copyconstructor `std::vector<_Tp, _Alloc>::vector(const std::vector<_Tp, _Alloc>&) [with _Tp = std::string, _Alloc = std::allocator<std::string>]': /usr/lib/gcc/i686-pc-cygwin/3.4.4/include/c++/bits/stl_uninitialized.h:82: warning: '__cur' might be used uninitialized in this function So I 'guess' it worked? But I cannot find any file it created at all... Hmm, I am going to try removing -Wall. Yep! It worked! Executing it now, results: Enter buffer size: 10000 initializing input strings... Checking that the parsers are functioning correctly... atoi is behaving itself! strtol is behaving itself! qi is behaving itself! Proceeding to timing tests.Calibrating overhead......done Timer overhead (t_c) ~= : 9.67512 Jitter ~= : 7.47951 qi_parse vs atoi : 78.1417 81.6005 86.3038% faster. qi_parse vs strtol : 76.5284 85.2148 86.8329% faster. strtol vs atoi : -4.67955 -2.60676 -0.488886% faster. qi_parse vs qi_parse : -0.900454 0.465715 1.85072% faster. All done! I ran the Visual Studio build again, still got about the same as I got in my last email, so yea, Visual Studio is a lot better on templates then GCC is. I wonder why GCC performs so much worse...

On Wed, 29 Jul 2009 18:48:49 -0600, OvermindDL1 <overminddl1@gmail.com> wrote:
Proceeding to timing tests.Calibrating overhead......done Timer overhead (t_c) ~= : 9.67512 Jitter ~= : 7.47951 qi_parse vs atoi : 78.1417 81.6005 86.3038% faster. qi_parse vs strtol : 76.5284 85.2148 86.8329% faster. strtol vs atoi : -4.67955 -2.60676 -0.488886% faster. qi_parse vs qi_parse : -0.900454 0.465715 1.85072% faster.
Folks, how do you get these 86% ? What is the formula? 'cause I know I am missing something, since F(78.14,81.6) somehow gives 0.86, but what is the F then... Thank you very much, Andrey
D'oh... after looking into the code I realized that this is actually min%-median%-max% speedup. Somehow I thought that only the last number is meanful. Would be nice to have something like "min=78% med=81% max=86% speedup over 100000 iterations" Oh well, I guess I was the only one puzzled :) Sorry for the noise. A. On Wed, 29 Jul 2009 20:10:46 -0600, Andrey Tcherepanov <moyt63c02@sneakemail.com> wrote:
On Wed, 29 Jul 2009 18:48:49 -0600, OvermindDL1 <overminddl1@gmail.com> wrote:
Proceeding to timing tests.Calibrating overhead......done Timer overhead (t_c) ~= : 9.67512 Jitter ~= : 7.47951 qi_parse vs atoi : 78.1417 81.6005 86.3038% faster. qi_parse vs strtol : 76.5284 85.2148 86.8329% faster. strtol vs atoi : -4.67955 -2.60676 -0.488886% faster. qi_parse vs qi_parse : -0.900454 0.465715 1.85072% faster.
Folks, how do you get these 86% ? What is the formula? 'cause I know I am missing something, since F(78.14,81.6) somehow gives 0.86, but what is the F then...
Thank you very much,
Andrey
_______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost
I often forget about -DNDEBUG - this can have a significant impact ~10% for Spirit2 over atoi. Presumably you define NDEBUG when compiling on Windows (or is that automatically assumed for 'Release' builds?).
Since I will be running it on the exact same computer with the same OS, but different compilers, that will prove if it really is GCC being much slower then VC, or if they are near the same on my computer, then it is something else.
I await with trepidation....
Very useful info, thanks. I altered slightly to support my setup, since boost trunk is in the /etc/usr/lib or something like that, it is picked up globally. I tried compiling it multiple times, got the same warning each time, never could find the output file.
With -Werror any warnings will be interpreted as errors. If there are compilation errors it won't build the object / executable.
Here is my latest attempt, I tried fully qualified names, did not help: OvermindDL1@overmind /cygdrive/s/cygwin/home/OvermindDL1/ejg_test $ g++ -DNDEBUG -O3 -ansi -pedantic -Wall -Wno-long-long -Werror -I/cygdrive/s/cygwin/home/OvermindDL1/ejg_test/other_includes -o /cygdrive/s/cygwin/home/OvermindDL1/ejg_test/ejg_uint_parser ejg_uint_parser_0_0_4_bind_1.cpp /usr/lib/gcc/i686-pc-cygwin/3.4.4/include/c++/bits/ stl_uninitialized.h: In copyconstructor `std::vector<_Tp, _Alloc>::vector(const std::vector<_Tp, _Alloc>&) [with _Tp = std::string, _Alloc = std::allocator<std::string>]': /usr/lib/gcc/i686-pc-cygwin/3.4.4/include/c++/bits/ stl_uninitialized.h:82: warning: '__cur' might be used uninitialized in this function
Hmm.. I've never come across that before. It looks like it's flagging an error relating to something in the setup of the iterators for parse_qi.
So I 'guess' it worked? But I cannot find any file it created at all...
Hmm, I am going to try removing -Wall. Yep! It worked!
As a future tip it's better to remove -Werror if needed - that way you will still get any warnings - but they won't be mapped to errors.
Proceeding to timing tests.Calibrating overhead......done Timer overhead (t_c) ~= : 9.67512 Jitter ~= : 7.47951 qi_parse vs atoi : 78.1417 81.6005 86.3038% faster. qi_parse vs strtol : 76.5284 85.2148 86.8329% faster. strtol vs atoi : -4.67955 -2.60676 -0.488886% faster. qi_parse vs qi_parse : -0.900454 0.465715 1.85072% faster.
All done!
Hmm. Very similar to my results - except for you strtol is slower than atoi.
I ran the Visual Studio build again, still got about the same as I got in my last email, so yea, Visual Studio is a lot better on templates then GCC is. I wonder why GCC performs so much worse...
Indeed - an open issue. Perhaps I will play with some other options (march etc.) to see if there's something I've overlooked. Well, I have to say I'm gaining more respect for the MS compiler - I last used it a very long time ago, back then it was awful! -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997

On Thu, Jul 30, 2009 at 3:24 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
I often forget about -DNDEBUG - this can have a significant impact ~10% for Spirit2 over atoi. Presumably you define NDEBUG when compiling on Windows (or is that automatically assumed for 'Release' builds?).
Since I will be running it on the exact same computer with the same OS, but different compilers, that will prove if it really is GCC being much slower then VC, or if they are near the same on my computer, then it is something else.
I await with trepidation....
Very useful info, thanks. I altered slightly to support my setup, since boost trunk is in the /etc/usr/lib or something like that, it is picked up globally. I tried compiling it multiple times, got the same warning each time, never could find the output file.
With -Werror any warnings will be interpreted as errors. If there are compilation errors it won't build the object / executable.
Here is my latest attempt, I tried fully qualified names, did not help: OvermindDL1@overmind /cygdrive/s/cygwin/home/OvermindDL1/ejg_test $ g++ -DNDEBUG -O3 -ansi -pedantic -Wall -Wno-long-long -Werror -I/cygdrive/s/cygwin/home/OvermindDL1/ejg_test/other_includes -o /cygdrive/s/cygwin/home/OvermindDL1/ejg_test/ejg_uint_parser ejg_uint_parser_0_0_4_bind_1.cpp /usr/lib/gcc/i686-pc-cygwin/3.4.4/include/c++/bits/stl_uninitialized.h: In copyconstructor `std::vector<_Tp, _Alloc>::vector(const std::vector<_Tp, _Alloc>&) [with _Tp = std::string, _Alloc = std::allocator<std::string>]': /usr/lib/gcc/i686-pc-cygwin/3.4.4/include/c++/bits/stl_uninitialized.h:82: warning: '__cur' might be used uninitialized in this function
Hmm.. I've never come across that before. It looks like it's flagging an error relating to something in the setup of the iterators for parse_qi.
So I 'guess' it worked? But I cannot find any file it created at all...
Hmm, I am going to try removing -Wall. Yep! It worked!
As a future tip it's better to remove -Werror if needed - that way you will still get any warnings - but they won't be mapped to errors.
Proceeding to timing tests.Calibrating overhead......done Timer overhead (t_c) ~= : 9.67512 Jitter ~= : 7.47951 qi_parse vs atoi : 78.1417 81.6005 86.3038% faster. qi_parse vs strtol : 76.5284 85.2148 86.8329% faster. strtol vs atoi : -4.67955 -2.60676 -0.488886% faster. qi_parse vs qi_parse : -0.900454 0.465715 1.85072% faster.
All done!
Hmm. Very similar to my results - except for you strtol is slower than atoi.
I ran the Visual Studio build again, still got about the same as I got in my last email, so yea, Visual Studio is a lot better on templates then GCC is. I wonder why GCC performs so much worse...
Indeed - an open issue. Perhaps I will play with some other options (march etc.) to see if there's something I've overlooked. Well, I have to say I'm gaining more respect for the MS compiler - I last used it a very long time ago, back then it was awful!
*scratches head* I must be missing something very obvious, but I do not see how your and OvermindDL benchmarks can support this conclusion: as far as I can tell, you two never compared the two compilers directly, what you are seeing is that on GCC the speed up of qi_parse over atoi/strtol is less than that of MSVC, but this tells nothing about the absolute performance of the two compilers on this test (i.e. you never showed any absolute times). For what we know the gcc atoi might just be faster than msvc one. And in fact a quick google search brings these two pages: http://tinyurl.com/mqa5yl [msvc8 atoi performance is 58% of that of msvc6] http://tinyurl.com/mzyw66 [thread containing a comparison of atoi functions of different languages and compilers, in particular it seems that MSVC atoi is really 2 times slower than gcc atoi] A slow atoi on MSVC would explain such a difference in the tests, assuming that the ability of both compilers to optimize qi_parse is about the same. Finally, I see from the error messages that OvermindDL is using gcc.3.4, which is now fairly old, maybe he should try with a more recent one. Also -march=native or whatever architecture he is using might help. HTH, -- gpd
Giovanni Piero Deretta wrote:
*scratches head*
I must be missing something very obvious, but I do not see how your and OvermindDL benchmarks can support this conclusion: as far as I can tell, you two never compared the two compilers directly, what you are seeing is that on GCC the speed up of qi_parse over atoi/strtol is less than that of MSVC, but this tells nothing about the absolute performance of the two compilers on this test (i.e. you never showed any absolute times).
For what we know the gcc atoi might just be faster than msvc one. And in fact a quick google search brings these two pages:
http://tinyurl.com/mqa5yl [msvc8 atoi performance is 58% of that of msvc6] http://tinyurl.com/mzyw66 [thread containing a comparison of atoi functions of different languages and compilers, in particular it seems that MSVC atoi is really 2 times slower than gcc atoi]
A slow atoi on MSVC would explain such a difference in the tests, assuming that the ability of both compilers to optimize qi_parse is about the same.
Finally, I see from the error messages that OvermindDL is using gcc.3.4, which is now fairly old, maybe he should try with a more recent one. Also -march=native or whatever architecture he is using might help.
Here are my tests with absolute numbers on one machine: MSVC 9: atoi_test: 6.8413257003 [s] strtol_test: 6.5168116888 [s] spirit_int_test: 2.0843406163 [s] gcc-4.3.2: atoi_test: 6.6410000000 [s] strtol_test: 6.2970000000 [s] spirit_int_test: 1.8280000000 [s] I'm starting to get impressed with g++ optimizations. If you want to verify the results, you can try it out from the boost SVN trunk at BOOST_ROOT/libs/spirit/benchmarks/qi/int_parser.cpp Here are my floating point tests: MSVC 9: atof_test: 8.4475158037 [s] strtod_test: 8.9236700525 [s] spirit_double_test: 2.9671239036 [s] gcc-4.3.2: atof_test: 12.4380000000 [s] strtod_test: 12.5940000000 [s] spirit_double_test: 2.7030000000 [s] Now that's rockin! In any case, this goes to show that Spirit numeric parsers are way faster than the corresponding low-level C routines. It shows that you can write extremely tight generic C++ code that rivals, if not surpasses C. Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
I ran the Visual Studio build again, still got about the same as I got in my last email, so yea, Visual Studio is a lot better on templates then GCC is. I wonder why GCC performs so much worse...
Indeed - an open issue. Perhaps I will play with some other options (march etc.) to see if there's something I've overlooked. Well, I have to say I'm gaining more respect for the MS compiler - I last used it a very long time ago, back then it was awful!
*scratches head*
I must be missing something very obvious, but I do not see how your and OvermindDL benchmarks can support this conclusion: as far as I can tell, you two never compared the two compilers directly, what you are seeing is that on GCC the speed up of qi_parse over atoi/strtol is less than that of MSVC, but this tells nothing about the absolute performance of the two compilers on this test (i.e. you never showed any absolute times).
As you can probably guess I don't really like absolute times. It is simple enough to try and do a cross comparison in a similar manner to the way relative values are currently calculated - it will just need a bit of tweaking, I'll give that some thought.
For what we know the gcc atoi might just be faster than msvc one. And in fact a quick google search brings these two pages:
http://tinyurl.com/mqa5yl [msvc8 atoi performance is 58% of that of msvc6] http://tinyurl.com/mzyw66 [thread containing a comparison of atoi functions of different languages and compilers, in particular it seems that MSVC atoi is really 2 times slower than gcc atoi]
A slow atoi on MSVC would explain such a difference in the tests, assuming that the ability of both compilers to optimize qi_parse is about the same.
Ah, good point - mea culpa! This is where my (diminishing) ignorance of computers gets highlighted - I was under the impression that the standard library calls would be calling the same underlying things for both compilers - clearly I'm mistaken. Thanks for the comment. My code was not originally intended for benchmarking compilers / platforms - it's just getting that way! -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Edward Grace skrev:
I'm clearly going to have to ponder this in some depth. While I've thought about trying to get the maths (statistics) right, I've not really given the nitty gritty of the machine's operation a great deal of thought.
Well, there you have it. I'd love to have your expertise on statistics
I claim none! I've been trying to learn as I go - perhaps a little knowledge is a dangerous thing!
plus Matthias Troyer, et al. test harness be combined in an easy to use benchmarking library.
Be careful what you wish for, it might come true... ;-)
Benchmarking is such a black art :-) !
I totally agree! Like presumably many others, this appeared to me to be a trivial problem - at first sight. In fact it's anything but straightforward. I bet there are half a dozen or so PhDs sitting in this particular dark recess of computing.
Well, I normally use a tool like vtune running the code on real data. Do you think such a tool is unreliable? -Thorsten
Thorsten Ottosen wrote:
Edward Grace skrev:
I'm clearly going to have to ponder this in some depth. While I've thought about trying to get the maths (statistics) right, I've not really given the nitty gritty of the machine's operation a great deal of thought.
Well, there you have it. I'd love to have your expertise on statistics
I claim none! I've been trying to learn as I go - perhaps a little knowledge is a dangerous thing!
plus Matthias Troyer, et al. test harness be combined in an easy to use benchmarking library.
Be careful what you wish for, it might come true... ;-)
Benchmarking is such a black art :-) !
I totally agree! Like presumably many others, this appeared to me to be a trivial problem - at first sight. In fact it's anything but straightforward. I bet there are half a dozen or so PhDs sitting in this particular dark recess of computing.
Well, I normally use a tool like vtune running the code on real data. Do you think such a tool is unreliable?
I'd like my benchmarks to be freely verifiable by anyone. It has to be cross-platform, free and can be bundled with Boost. Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net

Thorsten Ottosen wrote:
Edward Grace skrev:
I'm clearly going to have to ponder this in some depth. While I've thought about trying to get the maths (statistics) right, I've not really given the nitty gritty of the machine's operation a great deal of thought.
Well, there you have it. I'd love to have your expertise on statistics
I claim none! I've been trying to learn as I go - perhaps a little knowledge is a dangerous thing!
plus Matthias Troyer, et al. test harness be combined in an easy to use benchmarking library.
Be careful what you wish for, it might come true... ;-)
Benchmarking is such a black art :-) !
I totally agree! Like presumably many others, this appeared to me to be a trivial problem - at first sight. In fact it's anything but straightforward. I bet there are half a dozen or so PhDs sitting in this particular dark recess of computing.
Well, I normally use a tool like vtune running the code on real data. Do you think such a tool is unreliable?
VTune is for tuning application performance. VTune is too big a hammer for measuring benchmark runtime. Benchmarks are about wall clock time of a piece of code as a metric for performance of something else. How you measure that time and how you report those measurements is a problem that is prone to error. Personally I perform several runs of the same benchmark and then take the minimum time as the time I report. This excludes all outliers due to OS and such. If a car company reported the average (mean or median) 0 to 60 mph for a given car when their test driver was trying to see how fast it was everyone would think they were crazy. Why should the fact that he pushed the gas too hard on some of the trials and spun out and not hard enough on others count against the car? I also typically don't have the luxury of benchmarking on an unloaded machine, so I have to make sure to do things fairly, for instance, instead of runing many trials of A then many trials of B and taking the minimum for each I run many trials of A then B back to back and take the minimum. That way A and B on average see the same environement over the course of the experiement. If I run A and B in the same process I run A first then B and then B first and then A as a separate run to ensure that the order doesn't impact their performance. Usually benchmarking implies comparision, so the key concern is that the results are fair. Regards, Luke
Again this is a long one but I feel it's worth discussing these things in some detail --- only by truly understanding the problem can we try to solve it. (Something funny is going on regarding my access to this list - I keep getting things in strange order and with the wrong subject line. Anyhow - to add my oar in to this discussion.)
Well, I normally use a tool like vtune running the code on real data. Do you think such a tool is unreliable?
VTune is a sweet piece of kit, as are other profilers. I don't think they are unreliable - one just has to understand what they do and / or don't do and their limitations. For example, consider the 'fast' and 'slow' functions in my code which nominally differ in run-time by around 0.5%. Do you think the 'fire and forget' operation of a profiler would *reliably* detect this difference? [This is not a rhetorical question - I don't know and am genuinely curious]. It appears that my benchmarking does. Obviously this is a contrived example, no one is likely to care about 0.5% differences. For example, when you see that function 'abracadabra' takes 14.3323% of the run-time - how reliable is that number? When you compare it to the other function that takes 14.5231% is it actually faster? Are you sure? What happens if you profile again do you come to the same conclusion? From my point of view profilers are useless as they are for the off- line optimising of code. My original goal, as I have remarked before (somewhat obliquely) is that I wish to select the 'best' function or parameters dynamically at run-time. In other words, consider a set of functions (algorithms) which nominally do the same thing, I want to be able to do (I may be syntactically clumsy here) std::set<unary_function> sf; sf.insert(function_a); sf.insert(function_b); sf.insert(function_c)); .. .. .. function_pointer f = get_fastest_function(sf,test_argument); .. .. f(argument); // <--- This is now the fastest implementation of whatever we want. Here, the relative speed of the different functions could be 100% and differ for differing sizes of data such that it may not be possible to know a priori which is quickest. Likewise it may be run in a heterogeneous environment so that the knowledge about which function/ parameter combination works best on node "A" is exactly wrong for node "B". This may sound like a niche requirement - it is!
VTune is for tuning application performance. VTune is too big a hammer for measuring benchmark runtime. Benchmarks are about wall clock time of a piece of code as a metric for performance of something else. How you measure that time and how you report those measurements is a problem that is prone to error.
Ok, I should have read the whole email before writing the above monologue -- agreed. Though I'd caution against a bare 'wall clock' times in favour of relative times (some times of course you may *have* to measure the wall-clock time).
Personally I perform several runs of the same benchmark and then take the minimum time as the time I report.
Be very cautious about that for a number of reasons. a) By reporting the minimum, without qualifying your statement, you are lying. For example if you say "My code takes 10.112 seconds to run." people are unlikely to ever observe that time - it is by construction atypical. b) If ever you do this (use the minimum or maximum) then you are unwittingly sampling an extreme value distribution: http://en.wikipedia.org/wiki/Extreme_value_distribution For example - say you 'know' that the measured times are normally distributed with mean (and median) zero and a variance of 10. If you take, say 100 measurements and then take the minimum - how is that minimum distributed? In other words if your repeat this - again and again - what does the histogram of the minimum look like? What you will find is that the dispersion (variance or otherwise) on the median is small say \sigma^2=0.15 whereas the dispersion on the minimum can be much larger \sigma^2=1.8 - *and* the distribution is highly asymmetrical. If your two times were nominally separated by around 0.5 you would not necessarily reliably determine which was fastest from the minima since the distributions of the minima could overlap. Attached are two examples, histograms of the observed minimum for many trials and the observed median for many trials of the above scenario. Notice that the histogram of the observed minimum is *far* broader than the observed median. I suggest you experiment with this - you may be (unpleasantly) surprised; it's somewhat counter-intuitive an appropriate MATLAB (ok- ok put away the pitchforks) snippet below % EV clear all; v_median=zeros(50000,1); % Lots of trials to get a decent looking histogram. v_min=v_median; for m=1:length(v_median) v=randn(100,1).*sqrt(10); % Normally distributed, try other distributions. v_median(m)=median(v); v_min(m)=min(v); end figure(1); hist(v_median,51); figure(2); hist(v_min,51);
This excludes all outliers due to OS and such.
That may well be the aim, but I'm not sure it does get you what you want. This is where understanding of the maths (statistics) needs to be blended with an understanding of the machine. Your use of the minimum could make it *less* possible to infer something from the measurements. On the other hand you might be right - I don't know for sure -- but I am sceptical.
If a car company reported the average (mean or median) 0 to 60 mph for a given car when their test driver was trying to see how fast it was everyone would think they were crazy.
That's all down to marketing. I imagine they *do* determine it, they just don't report it that way. Most people couldn't care less what these numbers actually mean - just that it's 'better' than the other one. In the infamous words of "Spinal Tap" - "it goes up to eleven!".
Why should the fact that he pushed the gas too hard on some of the trials and spun out and not hard enough on others count against the car?
I imagine they test a number of different cars rather than just the same car a lot of times and that the reported time is some form of median. This would mean that half the cars will go a little faster - half a little slower than this 'typical' car. Almost certainly the testing criteria and their analysis is more sophisticated than that - speculation on my part -- anyone in the car industry?
I also typically don't have the luxury of benchmarking on an unloaded machine, so I have to make sure to do things fairly, for instance, instead of runing many trials of A then many trials of B and taking the minimum for each I run many trials of A then B back to back and take the minimum. That way A and B on average see the same environement over the course of the experiement.
Hopefully. As someone pointed out "It's a dark art"!
If I run A and B in the same process I run A first then B and then B first and then A as a separate run to ensure that the order doesn't impact their performance.
Just to add to the mix, I suggest randomising the order in which you run them (that's what I do) that way you are very unlikely to accidentally synchronise yourself with some other process e.g. ABBBABAABAB etc...
Usually benchmarking implies comparision, so the key concern is that the results are fair.
Easy to write very hard to do! ;-) Regards, -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Edward Grace wrote:
Personally I perform several runs of the same benchmark and then take the minimum time as the time I report.
Be very cautious about that for a number of reasons.
a) By reporting the minimum, without qualifying your statement, you are lying. For example if you say "My code takes 10.112 seconds to run." people are unlikely to ever observe that time - it is by construction atypical.
I try to be explicit about explaining what metric I'm reporting. If I'm reporting the minimum of ten trials I report it as the minimum of ten trials. Taking the minimum of ten trials and comparing it to the minimum of twenty trials and not qaulifying it would be even more dishonest because it isn't fair. I compare same number of trails, report that it is the minimum and the number of trails.
b) If ever you do this (use the minimum or maximum) then you are unwittingly sampling an extreme value distribution:
http://en.wikipedia.org/wiki/Extreme_value_distribution
For example - say you 'know' that the measured times are normally distributed with mean (and median) zero and a variance of 10. If you take, say 100 measurements and then take the minimum - how is that minimum distributed? In other words if your repeat this - again and again - what does the histogram of the minimum look like?
What you will find is that the dispersion (variance or otherwise) on the median is small say \sigma^2=0.15 whereas the dispersion on the minimum can be much larger \sigma^2=1.8 - *and* the distribution is highly asymmetrical.
If your two times were nominally separated by around 0.5 you would not necessarily reliably determine which was fastest from the minima since the distributions of the minima could overlap.
Attached are two examples, histograms of the observed minimum for many trials and the observed median for many trials of the above scenario. Notice that the histogram of the observed minimum is *far* broader than the observed median.
In this particular case of runtime the distribution is usually not normal. There is some theoritical fastest the program could go if nothing like the OS or execution of other programs on the same machine cause it to run slower. This is the number we actually want. We can't measure it, but we observe that there is a "floor" under our data and the more times we run the more clear it becomes where that floor is. It just won't run faster than that no matter how often we run. The minimum value tends to be closer to the mode of the distribution than to the median because runtimes cluster around the minimum value and tail off above. The idea is that using the minimum as the metric eliminates most of the "noise" introduced into the data by stuff unrelated to what you are trying to measure. Taking the median is just taking the median of the noise. In an ideal compute environment your runtimes would be so similar from run to run you wouldn't bother to run more than once. If there is noise in your data set your statistic should be designed to eliminate the noise, not characterize it. In my recent boostcon presentation my benchmarks were all for a single trial of each algorithm for each benchmark because noise would be eliminated during the curve fitting of the data for analysis of how well the algorithms scaled (if not by the conversion to logarithmic axis....) If I had taken the minimum of some number of trials I would have reported that in the paper. Regards, Luke
[ Warning to all - the following is a long, complex response -- don't bother reading unless you are *really* interested in the pedantic nuances of timing stuff! It may cause your eyes to glaze over and loss of consciousness. Apologies also for clogging up inboxes with pngs - be thankful for the mailing sentry bouncing this thing out until it got short enough! It just didn't read well with hyperlinked pictures. ] On 30 Jul 2009, at 23:21, Simonson, Lucanus J wrote:
Edward Grace wrote:
Personally I perform several runs of the same benchmark and then take the minimum time as the time I report.
Be very cautious about that for a number of reasons.
a) By reporting the minimum, without qualifying your statement, you are lying. For example if you say "My code takes 10.112 seconds to run." people are unlikely to ever observe that time - it is by construction atypical.
I try to be explicit about explaining what metric I'm reporting. If I'm reporting the minimum of ten trials I report it as the minimum of ten trials.
Good show! Re-reading my comments, it looks a bit adversarial - it's not intended to be! I'm not accusing you of falsehood or dodgy dealings! Apologies if that was the apparent tone!
Taking the minimum of ten trials and comparing it to the minimum of twenty trials and not qaulifying it would be even more dishonest because it isn't fair. I compare same number of trails, report that it is the minimum and the number of trails.
b) If ever you do this (use the minimum or maximum) then you are unwittingly sampling an extreme value distribution:
http://en.wikipedia.org/wiki/Extreme_value_distribution
For example - say you 'know' that the measured times are normally distributed with mean (and median) zero and a variance of 10. If you
[...]
scenario. Notice that the histogram of the observed minimum is *far* broader than the observed median.
In this particular case of runtime the distribution is usually not normal.
Of course, hence the quotes around 'know'. My demonstration of the effect of taking the minimum is based on the normal distribution since everyone knows it and it's assumed to be 'nice'. If you repeat what I did with another distribution (e.g. uniform, or Pareto) both of which have a well defined minimum you will still see the same effect! In fact, you are likely to observe even more extreme behaviour! I did not discuss more realistic distributions since it would cause people's eyes to glaze over even faster than this will!
There is some theoritical fastest the program could go if nothing like the OS or execution of other programs on the same machine cause it to run slower. This is the number we actually want. We can't measure it, but we observe that there is a "floor" under our data and the more times we run the more clear it becomes where that floor is.
Sure. This is partially a philosophical point regarding what one is trying to measure. In your case if you are trying to determine the fastest speed that the code could possibly go (and you don't have a real-time OS) then the minimum observed time looks like a good idea. I don't object to the use of the minimum (or any other estimator) per se, at least not yet. What one wishes to measure should determine the choice of estimator. For example, I do not want to know the minimum possible time as that is not indicative of the typical time. I want to compare the typical execution times of two codes *with* the OS taken in to account since, in the real world, this is what a user will notice and therefore what matters to me. Paraphrasing "Hamlet", 'To median or not to median - that is not quite the question.' My point is far more subtle than I think you have appreciated. The crux is that whatever your estimator you need to understand how it's distributed if you want to infer anything from it. So, if you *are* going to use the minimum (which is not robust) then you need to be aware that you may be inadvertently bitten by extreme value theory - consequently you should consider the form of the dispersion - it sure as heck won't be normal! This may seem bizarre - these things often are! To give you a concrete example, consider the following code (this also contains PDFs of the plots): http://tinyurl.com/n6kfe7 Here, we crudely time a simple function using a given number of iterations in a fairly typical manner. We repeat this timing 4001 times and then report the minimum and median of these 4001 acquisitions. This constitutes 'a measurement'. Each experimental 'measurement' is carried out for a randomly chosen number of iterations of the main timing loop and is hopefully independent. This is to try and satisfy the first i in iid (independent and identically distributed). For those of you bash oriented I do: ./ejg-make-input-for-empirical-ev > inputs.dat rm test.dat; while read line; do echo $line; echo $line | ./ejg- empirical-ev >> test.dat; done < inputs.dat No attempt is made to 'sanitise' the computer, nor do I deliberately load it. The raw results are shown below, The most obvious observation is that as the number of iterations increases the times both appear to converge in an asymptotic-like manner towards some 'true' value. This is clearly the effect of some overhead (e.g. the time taken to call the clock) having progressively less impact on the overall time. Secondly, the minimum observed time is lower than the median (as expected). What you may find a little surprising is that the *variation* of the minimum observed time is far greater than the variation in the median observed time. This is the key to my warning! If we crudely account for the overhead of the clock (which of course will also be stochastic - but let's ignore that) and subtract it then this phenomenon becomes even more stark. The variation of the observed times is now far clearer. Also, notice that rogue-looking red point in the bottom left of the main plot - for small numbers of iterations the dispersion of the minimum is massive compared to the dispersion of the median. You will also notice that there's now little difference between the predominant value of the median and minimum in this case. Now consider the inset, the second obvious characteristic is that the times do not appear to fluctuate entirely randomly with iteration number - instead there is obvious structure - indeed a sudden jump in behaviour around n=60. This is likely to be a strong interference effect between the clock and the function that's being measured and other architecture dependent issues (e.g. cache) that I won't pretend to fully understand. It's also indicative of how to interpret the observed variation - it's not necessarily purely random, but random + pseudorandom. Like std::rand(), if you keep the same seed (number of iterations) you may well observe the same result. That does not however mean that your true variance is zero - it's just hidden! Looking at the zoom in the inset it's clear to see that the median time has a generally far lower dispersion than the minimum time (by around an order of magnitude). There are even situations where the minimum time is clearly greater than the median time - directly counter to your expectation. This is not universally the case, but the general behaviour is perfectly clear. This can be considered to be a direct result of extreme value theory. If you use the minimum (or similar quantile) to estimate something about a random variable the result may have a large dispersion (variance) compared to the median. Just because you haven't seen it (changed the seed in your random number generator) doesn't mean it's not there! The practical amongst you may well say "Hey - who cares, we're talking about tiny differences!" I agree! So, is the moral of this tale to avoid using the minimum and instead to use the median? Not at all. I'm agnostic on this issue for reasons I mentioned above, however when / if one uses the minimum one needs to be careful and be aware of the (hidden) assumptions! For example, as various aspects of the timing change one may observe a sudden change in the cdf, 'magic' in the cache could perhaps cause the median measure to change far more than the minimum measure - so even though median may have better nominal precision, the minimum may well have better nominal accuracy. If you look in the code you'll see evidence that I've mucked around with different quantiles - I have not closed my mind to using the minimum!
It just won't run faster than that no matter how often we run.
Have you tried varying the number of iterations? You'll find that for some iteration lengths it may go significantly faster - doubtless this is a machine architecture issue, I don't know why - but it happens.
The idea is that using the minimum as the metric eliminates most of the "noise" introduced into the data by stuff unrelated to what you are trying to measure. Taking the median is just taking the median of the noise.
Not necessarily - as you can see from the above plots. Just because your estimator is repeatable for a given number of iterations doesn't mean it's 'ok' or eliminated the 'noise' - it's far more subtle than that.
In an ideal compute environment your runtimes would be so similar from run to run you wouldn't bother to run more than once. If there is noise in your data set your statistic should be designed to eliminate the noise, not characterize it.
If you want to try and eliminate it you need to characterise it. This is why relative measurements are so important if you desire precision - the noise is always there, no matter what you do, so having 'well behaved' noise (e.g. asymptotically normal) means you can infer things in a meaningful manner when you take differences. If you have no idea what the form of your noise is - or think you've eliminated it you can get repeatable results but they may be a subtle distortion of the truth. By taking the minimum you are not necessarily avoiding the 'noise', you may think you are - indeed it may look like you are, but you could have just done a good job of hiding it!
In my recent boostcon presentation my benchmarks were all for a single trial of each algorithm for each benchmark because noise would be eliminated during the curve fitting of the data for analysis of how well the algorithms scaled (if not by the conversion to logarithmic axis....)
As an aside you may find least absolute deviation (LAD) regression more appropriate than ordinary least squares (I'm assuming you used OLS of course). For practical application what you've done is almost certainly fine, 'good enough for government work' as the saying goes - I'm not suggesting it isn't. After all, as I have already commented, when human experimenters are involved we can eyeball the results and see when things look fishy or don't behave as expected. Ultimately - the take away message is apparently axiomatic 'truths' are not always as true as one might think. A dark art indeed! ;-) -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
{kind=link}
{kind=link}

OvermindDL1 wrote:
On Fri, Jul 31, 2009 at 2:37 PM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
On 31 Jul 2009, at 20:01, Phil Endecott wrote:
Edward Grace wrote:

-----Original Message----- From: boost-bounces@lists.boost.org [mailto:boost-bounces@lists.boost.org] On Behalf Of Phil Endecott Sent: 01 August 2009 16:34 To: boost@lists.boost.org Subject: Re: [boost] boost] Boost.Plot? - Scalable Vector Graphics (was [expressive] performance tuning
No, I'm not looking at the website archive, I'm looking at the list digest email.
FWIW, the email and attachments are all fine for me - using Outlook 2007 and Firefox 3.5 and Adobe Reader. Paul PS But I note that my original post on SVG has been hijacked - not that it matters much. --- Paul A. Bristow Prizet Farmhouse Kendal, UK LA8 8AB +44 1539 561830, mobile +44 7714330204 pbristow@hetp.u-net.com
Simonson, Lucanus J wrote:
Personally I perform several runs of the same benchmark and then take the minimum time as the time I report. This excludes all outliers due to OS and such. If a car company reported the average (mean or median) 0 to 60 mph for a given car when their test driver was trying to see how fast it was everyone would think they were crazy. Why should the fact that he pushed the gas too hard on some of the trials and spun out and not hard enough on others count against the car? I also typically don't have the luxury of benchmarking on an unloaded machine, so I have to make sure to do things fairly, for instance, instead of runing many trials of A then many trials of B and taking the minimum for each I run many trials of A then B back to back and take the minimum. That way A and B on average se e the same environement over the course of the experiement. If I run A and B in the same process I run A first then B and then B first and then A as a separate run to ensure that the order doesn't impact their performance.
Usually benchmarking implies comparision, so the key concern is that the results are fair.
This makes a lot of sense. Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net

On 28 Jul 2009, at 11:46, Edward Grace wrote:
On 28 Jul 2009, at 18:17, Joel de Guzman wrote:
Edward Grace wrote:
That is a *lot* more reasonable, although Spirit is still most definitely faster then the built-in functions. :)
That's good though - one up for Boost!
My latest benchmarks for integers and floating points reveal a 3x speed over atoi/strtol and friend C functions. You mentioned a need to parse small numbers very quickly? Spirit does. The tests I have take that into consideration too. If you guys want to take a peek, it's in the Boost trunk in libs/benchmarks.
Sure. Can you give me an exact url? The last time I went on a code hunt in SVN I found the wrong thing.
Some numbers:
/////////////////////////////////////////////////////////////////////////// atoi_test: 0.9265067422 [s] {checksum: d5b76d60} strtol_test: 1.0766213977 [s] {checksum: d5b76d60} spirit_int_test: 0.3097019879 [s] {checksum: d5b76d60}
/////////////////////////////////////////////////////////////////////////// atof_test: 7.3012049917 [s] {checksum: 3b7d82b0} strtod_test: 8.0042894122 [s] {checksum: 3b7d82b0} spirit_double_test: 2.6729373333 [s] {checksum: 3b7d82b0}
This time, I am using the benchmarking harness by David Abrahams, Matthias Troyer, Michael Gauckler.
This?
There's some interesting trickery in there by the looks of things for eliminating the optimiser nastiness - that's not something I've thought about much I'll take a look.
In the comments,
42 // operation to at least update the L1 cache. *** Note: This 43 // concern is specific to the particular application at which 44 // we're targeting the test. ***
that seems quite important but a little opaque out of context.
We did a loop over multiple accumulators in this test since this was the application scenario. We wanted to measure the abstraction penalty of using the Boost.Parameter library, but wanted it in a scenario where the functions called at least access the L1 cache so that we are not influenced by non-realistic too much simplified code that might be optimized too much.
One thing I take exception to is the (effective) use of the mean as a measurement of central tendency - perhaps their trickery has eliminated the heavy tail. I'll have to take a look and see how it compares to my approach.
Yes, we wanted to eliminate irrelevant heavy tails mainly by running the test multiple times. Why should the cost of e.g. swapping Word and Excel out of main memory to get space to run your test be measured as part of your test? This is a cost that *any* program might have to pay at times, no matter which algorithm you are comparing. I do not want such extreme events that are outside of my program's control mess up the comparisons. Another comment about heavy tails: if they are there then I want to analyze them and understand them. If they are absent then the mean is fine. We typically run the benchmark multiple times to eliminate heavy tails caused by swapping, etc..
How do your relative timings compare if you repeat them while (say) watching a DVD? [*]
Again, if you carte about performance of codes while you wach a DVD then that is just the benchmark you should run. My codes typically run while I am not watching a DVD and hence I do not repeat them while watching a DVD.
[*] This may seem a perverse question. I'm interested in robust performance measurement, in other words accurately working out which function is fastest while the machine is under choppy loading -- not a sanitised testing environment - so the fastest function can be selected by the code itself.
Again, my codes, and most performance-sensitive codes that I know of run in a rather "sanitized" environment without users watching DVDs or playing games on the machine while they run. If you want tests under choppy load then you have to provide a "sanitized" and reproducible choppy load environment. Matthias
When I compile and run the tests now, I get this: initializing input strings... Calibrating overhead......done Timer overhead (t_c) ~= : 12 Jitter ~= : 8.43769e-015 qi_parse vs atoi : 170.429 170.438 170.482% faster. qi_parse vs strtol : 167.589 167.601 167.668% faster. strtol vs atoi : 1.04669 1.05746 1.06165% faster. qi_parse vs qi_parse : 0 0 0% faster.
Hi OvermindDL1, When you've woken up would you mind taking a quick squiz at the following (anyone else - please feel free) ejg_uint_parser_0_0_4_bind_1.cpp in the following part of Boost Vault, http://tinyurl.com/lro5ok It's an attempt to crystallise the boo-boo you pointed out. I've tried to do everything without ghastly global variables - it's also a salient lesson on const correctness. If that'd been observed in the first place the iterator cock-up wouldn't have happened. ================== $ ./ejg_uint_parser Enter buffer size: 10000 initializing input strings... Checking that the parsers are functioning correctly... atoi is behaving itself! strtol is behaving itself! qi is behaving itself! Proceeding to timing tests.Calibrating overhead......done Timer overhead (t_c) ~= : 117.426 Jitter ~= : 25.9133 qi_parse vs atoi : 86.0764 86.3074 86.4471% faster. qi_parse vs strtol : 71.9253 72.1881 72.5288% faster. strtol vs atoi : 8.0502 8.26097 8.47215% faster. qi_parse vs qi_parse : -0.0274542 0.0393936 0.231944% faster. All done! ==================== On my platform this is entirely consistent with the simple one-liner modification you mentioned to the previous code. Take home message - yes Spirit really *is* faster. ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997

I'm really appreciative of the testing you are all doing with parsing code and hope that at the end we can see both how fast and how clear and maintainable the various styles of parser code become (focus on accuracy, speed then perhaps more on the clarity). Its great to see the enthusiasm and results. Looking forward to more tips once we have a fair test directly pitting spirit with expressive and other parsing methodologies. I also am encouraged by what Edward's timer might add though I'm a little wary of possible inclusion of code following FFTW's license as it may be incompatible with Boost. Edward, I do wonder about the statistical significance metrics you provide (great idea by the way). I'm wondering if your code assumes a normal timing duration distribution and if so, can it 'measure' whether the distribution of results conform to this assumption. In my experience, timing benchmarks can suffer from having outliers (usually OS-induced by not having a RTOS) that make the distribution less than 'normal'. Would it be possible to establish that the given sample set of timings correspond to a normal distribution (or perhaps discard a certain percentage of outliers if necessary). I'm no statistics person, but I have seen cases where 10,000 timing samples have been biased by 10 samples that probably relate to a program issue or a severe OS issue. e.g. normally 1 ms per iteration, 10 @ 1-10s each
Paul, [Excuse the following - perhaps it's an attack of logorrhea ]
I also am encouraged by what Edward's timer might add though I'm a little wary of possible inclusion of code following FFTW's license as it may be incompatible with Boost.
I'm pretty sure the FFTW license is Boost compatible (judging by the comments in the header and the BSD-like adoption of FFTW in many commercial and open source projects) however my aim is for a robust performance framework that is chronometer agnostic - there's no need to use FFTW's timer. The getticks() macro just happens to be a handy cross platform implementation! There are other concerns that I need to address regarding the licensing and provenance of this code. For now I am simply keen to see if it works for other people and in other real world situations - hence the application to the boost::spirit / xpressive debate. After all, you can read books on nonparametric statistical inference until you are paralysed with inaction - the only real way to know if it works is to try it and get other people involved and apply it in real-world situations. From that I'm sure I will learn a lot and then be in a situation to weed out unnecessary cruft (e.g. bootstrap resampling) and add useful stuff (potentially the cache related code mentioned earlier). After that it's a case of reviewing everything that's left after I've done my weeding and making sure it's appropriate.
Edward, I do wonder about the statistical significance metrics you provide (great idea by the way). I'm wondering if your code assumes a normal timing duration distribution and if so, can it 'measure' whether the distribution of results conform to this assumption.
It makes few assumptions about any underlying probability density function (not even that it's strongly stationary) since it's based on nonparametric techniques. Key to this is that, while the underlying distribution may not be normal or even known, the distribution of certain statistics estimated from a sample *is* well known. For example, the median is asymptotically normal (with certain constraints on the PDF). In other words if you take a large sample and calculate the median - then repeat this ad nauseam, the resulting medians will be approximately normally distributed. For a concrete example this is put to use in the calculation of the confidence bounds - by using the Wilcoxon signed-rank test for which the W+ statistic has a well known distribution. We can therefore determine if one function is faster than another in a (hopefully) statistically significant way.
In my experience, timing benchmarks can suffer from having outliers
I don't view these as 'outliers' in the normal usage of 'measurement error' - they are measurements that are just as valid as any other - one just has to ask "what is this measuring - the function under test or the OS?". Often it's the latter but there is (as I see it) no clear border-line between classifying any given measurement as one and not the other. Consequently I view 'throwing away' (trimming) measurements with great suspicion.
(usually OS-induced by not having a RTOS)
RTOS? Real-time OS?? Do these eliminate this effect?
that make the distribution less than 'normal'.
The distribution would not be normal even in principle. It must have a well defined minimum, but (in principle) has no upper bound - the (gross) lack of symmetry rules out normality in a heartbeat!
Would it be possible to establish that the given sample set of timings correspond to a normal distribution (or perhaps discard a certain percentage of outliers if necessary).
It is possible to determine if the sample corresponds to a known distribution - the Kolmogorov-Smirnov test. However which one should we check? There is no fundamental requirement for the measurements to belong to any family - even vaguely. In fact it may not even be smooth!
I'm no statistics person, but I have seen cases where 10,000 timing samples have been biased by 10 samples that probably relate to a program issue or a severe OS issue. e.g. normally 1 ms per iteration, 10 @ 1-10s each
Yes - that issue has a dramatic impact on the robustness of (or lack thereof) of the mean. Often of course these things are even vaguely IID (independent and identically distributed) - burst like behaviour can lead to strongly non-stationary behaviour. For example some garbage collector might go nuts and skew your timing. That's why, in my view, it's so important to compare relative timings and to obtain confidence bounds. Pragmatically one might argue that when you're doing these things at the console during development and making decisions it's not really a major issue. One can look at the numbers and say "hmm, fishy - I don't trust that" and tinker around until the result is in line with your expectation. That's part of the art that is experimental science and many of us do it everyday without even realising. How to codify that opinion into something that's autonomous and capable of e.g. selecting the 'correct' function in a high-load multi- user environment in the real world is far from clear however. That is my goal. -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Paul Baxter wrote:
I'm really appreciative of the testing you are all doing with parsing code and hope that at the end we can see both how fast and how clear and maintainable the various styles of parser code become (focus on accuracy, speed then perhaps more on the clarity).
Its great to see the enthusiasm and results. Looking forward to more tips once we have a fair test directly pitting spirit with expressive and other parsing methodologies.
Keep i mind that we are testing just one small aspect of parsing/ text processing. It just so happens that spirit is designed to be optimal in this *specific* use case. xpressive will definitely shine in other areas (e.g. searching, replacing). So, as always, use the right tool for the job. Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
Joel de Guzman wrote:
Paul Baxter wrote:
I'm really appreciative of the testing you are all doing with parsing code and hope that at the end we can see both how fast and how clear and maintainable the various styles of parser code become (focus on accuracy, speed then perhaps more on the clarity).
Its great to see the enthusiasm and results. Looking forward to more tips once we have a fair test directly pitting spirit with expressive and other parsing methodologies.
Keep i mind that we are testing just one small aspect of parsing/ text processing. It just so happens that spirit is designed to be optimal in this *specific* use case. xpressive will definitely shine in other areas (e.g. searching, replacing). So, as always, use the right tool for the job.
IIRC, xpressive was faster than Spirit 1. Spirit 2 has leapfrogged xpressive in performance. That pleases me -- a regex engine with exhaustive backtracking semantics has no business being faster than a parser generator. :-) Kudos to Joel and Hartmut. Sorry I haven't kept up with this discussion. Things in my day job have taken a turn for the busy. -- Eric Niebler BoostPro Computing http://www.boostpro.com
On Tue, Jul 28, 2009 at 11:09 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
When I compile and run the tests now, I get this: initializing input strings... Calibrating overhead......done Timer overhead (t_c) ~= : 12 Jitter ~= : 8.43769e-015 qi_parse vs atoi : 170.429 170.438 170.482% faster. qi_parse vs strtol : 167.589 167.601 167.668% faster. strtol vs atoi : 1.04669 1.05746 1.06165% faster. qi_parse vs qi_parse : 0 0 0% faster.
Hi OvermindDL1,
When you've woken up would you mind taking a quick squiz at the following (anyone else - please feel free)
ejg_uint_parser_0_0_4_bind_1.cpp
in the following part of Boost Vault, http://tinyurl.com/lro5ok
It's an attempt to crystallise the boo-boo you pointed out. I've tried to do everything without ghastly global variables - it's also a salient lesson on const correctness. If that'd been observed in the first place the iterator cock-up wouldn't have happened.
================== $ ./ejg_uint_parser Enter buffer size: 10000 initializing input strings...
Checking that the parsers are functioning correctly... atoi is behaving itself! strtol is behaving itself! qi is behaving itself!
Proceeding to timing tests.Calibrating overhead......done Timer overhead (t_c) ~= : 117.426 Jitter ~= : 25.9133 qi_parse vs atoi : 86.0764 86.3074 86.4471% faster. qi_parse vs strtol : 71.9253 72.1881 72.5288% faster. strtol vs atoi : 8.0502 8.26097 8.47215% faster. qi_parse vs qi_parse : -0.0274542 0.0393936 0.231944% faster.
All done! ====================
On my platform this is entirely consistent with the simple one-liner modification you mentioned to the previous code.
Take home message - yes Spirit really *is* faster.
Enter buffer size: 10000 initializing input strings... Checking that the parsers are functioning correctly... atoi is behaving itself! strtol is behaving itself! qi is behaving itself! Proceeding to timing tests.Calibrating overhead......done Timer overhead (t_c) ~= : 12 Jitter ~= : 8.43769e-015 qi_parse vs atoi : 160.834 187.892 197.781% faster. qi_parse vs strtol : 152.088 173.709 197.184% faster. strtol vs atoi : 5.34019 7.29527 9.82952% faster. qi_parse vs qi_parse : -3.12862 -0.194198 1.53912% faster. All done! MSVC definitely compiles templates code better then GCC it seems (you said you were using GCC yes?). Also, I think I might know why QI is faster then atoi/strtol. atoi/strtol handle local as I recall, QI does not...
OvermindDL1 wrote:
Also, I think I might know why QI is faster then atoi/strtol. atoi/strtol handle local as I recall, QI does not...
Sorry, I can't parse that. What do you mean by "handle local"? Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
On Tue, Jul 28, 2009 at 8:14 PM, Joel de Guzman<joel@boost-consulting.com> wrote:
OvermindDL1 wrote:
Also, I think I might know why QI is faster then atoi/strtol. atoi/strtol handle local as I recall, QI does not...
Sorry, I can't parse that. What do you mean by "handle local"?
Er, locale*
OvermindDL1 wrote:
On Tue, Jul 28, 2009 at 8:14 PM, Joel de Guzman<joel@boost-consulting.com> wrote:
OvermindDL1 wrote:
Also, I think I might know why QI is faster then atoi/strtol. atoi/strtol handle local as I recall, QI does not... Sorry, I can't parse that. What do you mean by "handle local"?
Er, locale*
Sure, that's one. The reason is because spirit numerics are customizable. And they are even more customizable than the locales provide. For example, you can tweak the floating point parsers to handle numbers like: 1,234,567,890 or 1.234567890 exp -200 with the same high performance. And, surely, you can customize them to handle locales. Regards, -- Joel de Guzman http://www.boostpro.com http://spirit.sf.net
Proceeding to timing tests.Calibrating overhead......done Timer overhead (t_c) ~= : 117.426 Jitter ~= : 25.9133 qi_parse vs atoi : 86.0764 86.3074 86.4471% faster. qi_parse vs strtol : 71.9253 72.1881 72.5288% faster. strtol vs atoi : 8.0502 8.26097 8.47215% faster. qi_parse vs qi_parse : -0.0274542 0.0393936 0.231944% faster.
All done! ====================
On my platform this is entirely consistent with the simple one-liner modification you mentioned to the previous code.
Take home message - yes Spirit really *is* faster.
Enter buffer size: 10000 initializing input strings...
Checking that the parsers are functioning correctly... atoi is behaving itself! strtol is behaving itself! qi is behaving itself!
Proceeding to timing tests.Calibrating overhead......done Timer overhead (t_c) ~= : 12 Jitter ~= : 8.43769e-015 qi_parse vs atoi : 160.834 187.892 197.781% faster. qi_parse vs strtol : 152.088 173.709 197.184% faster. strtol vs atoi : 5.34019 7.29527 9.82952% faster. qi_parse vs qi_parse : -3.12862 -0.194198 1.53912% faster.
All done!
[fixed with font required] Interesting. So, there is no difference between the speedup of strtol and atoi between your platform and mine (their confidence intervals overlap). strtol vs atoi OvermindDL1: [5.3 ---------x-------- 9.8] % Ed: [8.1 --x- 8.5] % on the other hand qi_parse is significantly faster under Windows on your architecture compared to atoi than OS X. qi_parse vs atoi OvermindDL1: [160.8 ---------x-- 197.8] % Ed: [86.0 -----x----- 86.4] % Likewise in both cases the timing of qi_parse against itself shows no difference since the confidence interval includes zero. qi_parse vs qi_parse OvermindDL1: [-3.13 ----------- 0 ----------- +1.54] % Ed: [-0.03 -- 0 -- +0.23] %
MSVC definitely compiles templates code better then GCC
More warnings?
it seems (you said you were using GCC yes?).
Yes.... I wonder why am I starting to feel sheepish about that... -ed
On Wed, Jul 29, 2009 at 4:20 AM, Edward Grace<ej.grace@imperial.ac.uk> wrote:
Proceeding to timing tests.Calibrating overhead......done Timer overhead (t_c) ~= : 117.426 Jitter ~= : 25.9133 qi_parse vs atoi : 86.0764 86.3074 86.4471% faster. qi_parse vs strtol : 71.9253 72.1881 72.5288% faster. strtol vs atoi : 8.0502 8.26097 8.47215% faster. qi_parse vs qi_parse : -0.0274542 0.0393936 0.231944% faster.
All done! ====================
On my platform this is entirely consistent with the simple one-liner modification you mentioned to the previous code.
Take home message - yes Spirit really *is* faster.
Enter buffer size: 10000 initializing input strings...
Checking that the parsers are functioning correctly... atoi is behaving itself! strtol is behaving itself! qi is behaving itself!
Proceeding to timing tests.Calibrating overhead......done Timer overhead (t_c) ~= : 12 Jitter ~= : 8.43769e-015 qi_parse vs atoi : 160.834 187.892 197.781% faster. qi_parse vs strtol : 152.088 173.709 197.184% faster. strtol vs atoi : 5.34019 7.29527 9.82952% faster. qi_parse vs qi_parse : -3.12862 -0.194198 1.53912% faster.
All done!
[fixed with font required]
Interesting. So, there is no difference between the speedup of strtol and atoi between your platform and mine (their confidence intervals overlap).
strtol vs atoi
OvermindDL1: [5.3 ---------x-------- 9.8] %
Ed: [8.1 --x- 8.5] %
on the other hand qi_parse is significantly faster under Windows on your architecture compared to atoi than OS X.
qi_parse vs atoi
OvermindDL1: [160.8 ---------x-- 197.8] %
Ed: [86.0 -----x----- 86.4] %
Likewise in both cases the timing of qi_parse against itself shows no difference since the confidence interval includes zero.
qi_parse vs qi_parse
OvermindDL1: [-3.13 ----------- 0 ----------- +1.54] %
Ed: [-0.03 -- 0 -- +0.23] %
MSVC definitely compiles templates code better then GCC
More warnings?
it seems (you said you were using GCC yes?).
Yes.... I wonder why am I starting to feel sheepish about that...
Heh, I do have cygwin completely installed and fully updated on my computer here (the recommended beta version that uses gcc 4.3 as I recall) and I do have boost trunk (from a couple weeks ago anyway) in there and compiled for it. If you can tell me what command I need to type to compile the file with all necessary optimizations, I will do that here too. Since I will be running it on the exact same computer with the same OS, but different compilers, that will prove if it really is GCC being much slower then VC, or if they are near the same on my computer, then it is something else. So, what should I type assuming I have the ejg test file and cycle.h in the current directory with the ejg in ./other_includes/ejg for full optimizations and everything?
it seems (you said you were using GCC yes?).
Yes.... I wonder why am I starting to feel sheepish about that...
Heh, I do have cygwin completely installed and fully updated on my computer here (the recommended beta version that uses gcc 4.3 as I recall) and I do have boost trunk (from a couple weeks ago anyway) in there and compiled for it. If you can tell me what command I need to type to compile the file with all necessary optimizations, I will do that here too.
Hi, assuming: * Your homed directory is $HOME * Spirit2 is in $HOME/spirit21_root, which should contain boost/ spirit/actor.hpp * The latest Boost is in $HOME/boost_root, which should contain boost/any.hpp * cycle.h is in the same directory as the file ejg_uint_parser_0_0_4_bind_1.cpp * The ejg timer stuff is in $HOME/ejg_root, this should contain ejg/timer.hpp the following stanza will work in bash (note the backslashes to break the line), first we define some environment variables for legibility, then fire up g++, # ------ cut ----- SPIRIT2=$HOME/spirit21_root BOOST=$HOME/boost_root EJG=$HOME/ejg_root g++ -DNDEBUG -O3 -ansi -pedantic -Wall -Wno-long-long -Werror \ -I$SPIRIT2 -I$BOOST -I$EJG -o ejg_uint_parser \ ejg_uint_parser_0_0_4_bind_1.cpp # ----- cut ------- The following is a synopsis of what the bits mean, in case it's not obvious. -DNDEBUG -> equivalent to #define NDEBUG, should switch off any debug parts of Boost -O3 -> Optimisation level 3 - pretty much all in! -ansi -> Require ANSI compliance of the language! -pedantic -> Really really mean it! -Wall -> Warn about everything (alegedly) -Wno-long-long -> Do not warn about long long not being a mandated C+ + standard type. -Werror -> Convert warnings to errors -I<blah> -> Include <blah> as a directory to search for include files along with the standard locations. -o <blah> -> Generate the binary file <blah> I often forget about -DNDEBUG - this can have a significant impact ~10% for Spirit2 over atoi. Presumably you define NDEBUG when compiling on Windows (or is that automatically assumed for 'Release' builds?).
Since I will be running it on the exact same computer with the same OS, but different compilers, that will prove if it really is GCC being much slower then VC, or if they are near the same on my computer, then it is something else.
I await with trepidation.... -ed
Edward Grace wrote:
Even looking at the min, Spirit is still over 25% faster then string (and that number is with an extremely high amount of statistical confidence). I use Boost.Bind to call the test function so that adds a bit of overhead, which could be noticeable on the faster thing like Spirit, so Spirit could potentially be even faster then the above test indicates.
Do you think the overhead of calling through boost::bind could be comparable to the length of time it takes to run the function?
I don't know -- haven't looked -- where boost::bind was added or why, but any unnecessary overhead should be eliminated unless it is proven to be insignificant.
Looking at the following,
testing::run_tests(std::string const & _description, tests_type const & _tests, Parser _parse, unsigned const _iterations) { [snip] }
I suggest something that simply iterates over the test data but does not check for correctness of parsing. Although it won't make a fat lot of difference in this case at least it's then consistent - you're timing the parsers not the tests for equality. The correctness test could then be done later once the timings are complete.
I should have done that from the beginning. It would be best, I think, to run through the data once for each test, to verify the result. Then, timing runs can be done without any checks. Both should run from main() each time so that any optimizations are validated before considering the performance.
Does the size of the test data set matter? In other words do you notice similar speedups if the test data will all fit in cache?
Wouldn't that give less representative performance results? _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.
Do you think the overhead of calling through boost::bind could be comparable to the length of time it takes to run the function?
I don't know -- haven't looked -- where boost::bind was added or why, but any unnecessary overhead should be eliminated unless it is proven to be insignificant.
It seems that it's not a problem. [....]
I suggest something that simply iterates over the test data but does not check for correctness of parsing. Although it won't make a fat lot of difference in this case at least it's then consistent - you're timing the parsers not the tests for equality. The correctness test could then be done later once the timings are complete.
I should have done that from the beginning. It would be best, I think, to run through the data once for each test, to verify the result. Then, timing runs can be done without any checks. Both should run from main() each time so that any optimizations are validated before considering the performance.
Sure.
Does the size of the test data set matter? In other words do you notice similar speedups if the test data will all fit in cache?
Wouldn't that give less representative performance results?
I guess it depends what you're trying to represent when measuring the performance. If you're trying to represent the [totally contrived] case of parsing short segments of text that all fit in cache surely it's better? Or is your question more regarding the distribution of the actual values under test rather than the length? My suggestion is merely the curiosity of seeing if there is a cache dependent effect or not rather than a 'representative' measurement. I don't for a minute think it's a good idea to permanently modify someone's hard thought through and exhaustive testing. As a tongue-in-cheek aside - there's potentially some merit in having a parser that's particularly fast for numbers starting with "123". http://en.wikipedia.org/wiki/Benford%27s_law Regards, -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Edward Grace wrote:
Does the size of the test data set matter? In other words do you notice similar speedups if the test data will all fit in cache?
Wouldn't that give less representative performance results?
I guess it depends what you're trying to represent when measuring the performance. If you're trying to represent the [totally contrived] case of parsing short segments of text that all fit in cache surely it's better?
I was presuming to suggest that the more representative test was that of parsing across the spectrum of possible inputs such code likely will parse in a real finance program rather than contriving small tests to focus on isolated characteristics.
Or is your question more regarding the distribution of the actual values under test rather than the length?
I don't think the lengths will vary much beyond what appears in the test input other than, possibly, the lack of really short inputs.
My suggestion is merely the curiosity of seeing if there is a cache dependent effect or not rather than a 'representative' measurement. I don't for a minute think it's a good idea to permanently modify someone's hard thought through and exhaustive testing.
I was afraid that the test code might be permanently altered and lose sight of what I think is a fairly representative set of test inputs. _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.
Wouldn't that give less representative performance results?
I guess it depends what you're trying to represent when measuring the performance. If you're trying to represent the [totally contrived] case of parsing short segments of text that all fit in cache surely it's better?
I was presuming to suggest that the more representative test was that of parsing across the spectrum of possible inputs such code likely will parse in a real finance program
Benford's law it is then... ;-)
rather than contriving small tests to focus on isolated characteristics.
Sure.
I was afraid that the test code might be permanently altered and lose sight of what I think is a fairly representative set of test inputs.
No - no not at all... I fully understand your concern -- I'm just being curious! -ed
OvermindDL1 wrote:
Okay, I basically just copy/pasted my thread-safe version of my spirit parser over and ran it, it returned bad parse with like 13/9 or something like that. According to the documentation in the original cpp file, only "1", "1 2/3", or "1.2" are valid, not "2/3", so I
From the beginning, I specified real numbers, whole numbers, mixed numbers, and fractions.
changed it to support that and ran it again, it parsed successfully with all numbers in your tests matching successfully. Here is what it
Excellent.
printed, using the horribly inaccurate time function: Testing string-based parsing Testing Xpressive-based parsing Testing Spirit-based parsing string parsing: 8s xpressive parsing: 33s spirit parsing: 6s
That's why I offered the iterations argument: increase by, say, 5 times and you'll have numbers you can compare a little more accurately.
If you do not mind, I am going to add a millisecond accuracy testing framework (test.hpp from the boost examples) to the file and change all the nasty time calls to it for a more reliable reading. I backed
I don't mind at all. It is helpful to get better accuracy as the test needn't be run with as many iterations.
For now, I have attached my modified main.cpp that includes the thread-safe spirit parser (I have not yet added the other two, do you want me to even bother?), and it includes the single
I don't know the difference among them, so I can't answer for including them or not.
P.S. I would be quite happy if anyone could get rid of that freakishly long double->int64_t cast warning in the xpressive code, I like clean builds. :)
I don't get the warning, so you'll have to be more specific. _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.
OvermindDL1 wrote:
I did a quick first test at work, just a quick compile, got some errors, and quite frankly I do not know how this compiled in gcc either. First error is: 1>r:\programming_projects\spirit_price\price_parsing\main.cpp(545) : error C2373: '_input' : redefinition; different type modifiers 1> r:\programming_projects\spirit_price\price_parsing\main.cpp(544) : see declaration of '_input'
The relevant code is: template <class T> T extract(char const * & _input, char const * _description, std::string const & _input);
That was just a copy paste error in a declaration. GCC 4.1.2 didn't complain about it for me and I have warnings up very high. You can remove the formal parameter names, if you like.
Why do the first and last function params have the same name (_input)? And which one is the real input? Based upon line 566, I changed the last _input to _value and that error (and one other) is now gone.
Yes, the third argument is _value.
Hmm, actually the third error is gone too. Now I am getting lots of Warnings (as errors since I by default have warnings treated as errors) about double to int64_t cast, both in your normal code on line 730
I don't know where you're seeing those warnings. I've addressed all such warnings I get from GCC 4.1.2. My warnings are set to "-Wall -Wno-comment -Wpointer-arith -W -Wconversion -Wno-long-long."
Also, I added a: tests.reserve(450000); right before the load_tests call, that changed the load_tests time from like 10 seconds to about 2 seconds on my system.
You're assuming the full set of test inputs. I was allowing for testing with reduced input sets. You could read the file twice to count the number of lines and then reserve enough elements to maintain flexibility and, possible, improve performance. However, that's done once before running all of the tests, so I certainly didn't worry about the performance of that initialization.
Also, why are you using time(0), that only has second accuracy?
It is simple and portable. _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.
OvermindDL1 wrote:
On Mon, Jul 27, 2009 at 1:34 PM, Stewart, Robert<Robert.Stewart@sig.com> wrote:
0. A hopefully portable definition of int64_t extracted from boost/cstdint.hpp (is there a better option for this that I missed?)
That is what is supposed to be used for multi-platform integers with 64-bit width. :)
Sorry, I meant the INT64_C macro, not the int64_t typedef. _____ Rob Stewart robert.stewart@sig.com Software Engineer, Core Software using std::disclaimer; Susquehanna International Group, LLP http://www.sig.com IMPORTANT: The information contained in this email and/or its attachments is confidential. If you are not the intended recipient, please notify the sender immediately by reply and immediately delete this message and all its attachments. Any review, use, reproduction, disclosure or dissemination of this message or any attachment by an unintended recipient is strictly prohibited. Neither this message nor any attachment is intended as or should be construed as an offer, solicitation or recommendation to buy or sell any security or other financial instrument. Neither the sender, his or her employer nor any of their respective affiliates makes any warranties as to the completeness or accuracy of any of the information contained herein or that this message or any of its attachments is free of viruses.
on Mon Jul 20 2009, "Stewart, Robert" <Robert.Stewart-AT-sig.com> wrote:
I tried posting a file with the test inputs to this list, but it made my message too large and was rejected. I didn't think it made sense to put such a file in the vault, so I have not put it there -- or anywhere -- as yet. Lacking any other concrete idea, I may post the file in the vault anyway. I will indicate as much when I do.
You can do that, or you could check it into the SVN sandbox. If you don't have write access there, just send a request to boost-owner@lists.boost.org -- Dave Abrahams BoostPro Computing http://www.boostpro.com
participants (27)
-
 Andrey Tcherepanov
Andrey Tcherepanov -
 Celtic Minstrel
Celtic Minstrel -
 Christopher Jefferson
Christopher Jefferson -
 Daniel Hulme
Daniel Hulme -
 David Abrahams
David Abrahams -
 Edouard A.
Edouard A. -
 Edward Grace
Edward Grace -
 Eric Niebler
Eric Niebler -
 Giovanni Piero Deretta
Giovanni Piero Deretta -
 Hartmut Kaiser
Hartmut Kaiser -
 Joel de Guzman
Joel de Guzman -
 John Bytheway
John Bytheway -
 jon_zhou@agilent.com
jon_zhou@agilent.com -
 Matthias Troyer
Matthias Troyer -
 Michael Caisse
Michael Caisse -
 OvermindDL1
OvermindDL1 -
 Paul A. Bristow
Paul A. Bristow -
 Paul Baxter
Paul Baxter -
 Phil Endecott
Phil Endecott -
 Raindog
Raindog -
raindog@macrohmasheen.com
-
 Robert Jones
Robert Jones -
 Simonson, Lucanus J
Simonson, Lucanus J -
 Steven Watanabe
Steven Watanabe -
 Stewart, Robert
Stewart, Robert -
 Thorsten Ottosen
Thorsten Ottosen -
 Zachary Turner
Zachary Turner