[Review][PQS] Review ends

Hello, boosters! Any given day exists for 50 hours, but it does end at some point. Likewise, the PQS review ends at some point. I will arbitrarily say midnight UTC and the timezone of the author. However, it will take me roughly a week to collate all of the reviews and reach an official decision, so don't feel shy about posting or mailing me additional reviews. I thank the reviewers very much for reviewing the library, and I thank Andy Little even more for all of his work responding to the reviews and for writing the library in the first place! -Fred Bertsch

Hello, I'm posting this review a bit after the deadline, and I'm very sorry about that. This is caused by the fact that I didn't know that all mailing list members can write a review. When I learned about that, I had only about 2 days left, but still I wanted to perform a deep analysis of what is in pqs. --------------------------------------------------- * Do you think the library should be accepted as a Boost library? Yes, I think it should. The scientific community, and industry are in desperate need of such library, rejecting it just because it's not perfect would be a very bad decision. It's not uncommon that boost libraries evolve once included, I believe that this will be the case here. Moreover including it will greatly increase the amount of feedback received and in result the library will reach the "perfect" state much faster. After performing checks (described below) I'm sure that the library is ready for inclusion. Note: below I often refer to yade ( http://yade.berlios.de/ ) which is a framework for performing scientific simulations. Yade is my current project, and a part of my PhD. I have done tests of using pqs inside yade, performed speed benchmarks and unit tests. --------------------------------------------------- * What is your evaluation of the documentation? Before trying pqs I've read almost whole documentation (skipped few pages). So those comments and suggestions below were written before I actually tried using pqs: As stated by other reviewers the introduction is a bit offtopic. Summary given by review manager fits here best. In "Definition of terms" an UML diagram would be nice, or at least some of those diagrams that are automatically generated by doxygen. Later I discovered that in html version there is a diagram, but not in pdf version. I wonder if any other reviewer would complain less if he saw this diagram in pdf. Downloading pdf was much easier than unpacking the library and opening index.html from it ;) I'd prefer a different name for coherent_unit and incoherent_unit, for example si_unit and non_si_unit. Several terms ( 'dimensional analysis', 'dimensionally_equivalent', 'dimensional_math', 'dimensionless', 'dimensionful', 'physical_quantity', 'physical_quantity_system', 'rational_number', 'unit_output_symbol', 'unit_symbol' ) do not appear on the Entity Relationship Diagram. Therefore their meaning is for me unclear: classes, methods or concepts? If they are concepts then underscore ("_") shouldn't be used in their name. Method names can be written in the ERD diagram inside rectangle of a given class, separated by horizontal line (UML notation), so that it would be possible to look up methods in the diagram. Also a reference-style listing of all classes and methods in the library would be nice (this kind of documentation is usually auto generated by doxygen). This listing would have references to correct places in synopsis. It would be also *very* useful if at the end of the doc, there was a referenced list of all examples in the manual, and also a list of all pictures. In Rationale:Clarity section the example with PQ_Box should be written full 'ready to compile' (because it is the first longer example that appears in the manual). Also IMHO Rationale section should be put before Definition of terms. Usually definition of terms is put at the beginning, but usually it is much shorter. A causal reader who doesn't know what he should read, will read from top to bottom - and in this respect it's more important that he reads Rationale first. Because if he reads Definitions first - he may lose his enthusiasm due to fact that definitions are _always_ boring (no matter how hard you try to make them interesting). I prefer "per": m_per_s, etc... In pdf page 3, missing space: "The keyword typeofis used". In pdf page 5, missing space: "distinguish between different but dimensionally_equivalentabstract_quantities." In pdf page 18 there is a reference to "Example 3a", but all examples are unlabelled, so I can only detect from the context of the sentence which example is actually referred. It would be useful to label all examples. (and make a full list of all examples at the end). In pdf page 23 comment is too long to fit on the page. In pdf page 28 - mistaken underline In pdf page 32 - I prefer synopsis written in valid C++, for example simple copy'n'paste from file t1_quantity.hpp would work. In fact I had difficulty in understanding line "if IsDimensionless<abstract_quantity>", and lines following it, until I guessed that it's some kind of Cpp pseudocode. In pdf page 51 - mistaken underline. Word "useage" hurts my eyes. Heh, and vim's spellchecker underlines it as a bad word ;) --------------------------------------------------- * What is your evaluation of the implementation? More constants, including mathematical ones, would be nice. I don't like the separation of "three_d" and "two_d" - where quaternions should be put then - "four_d" ? I've gone through similar problems in my own design (just browse older revisions of yade in subversion repository http://tinyurl.com/lgk8t ), and finally I've found it most convenient to put vector (both 2d and 3d), quaternion and matrix inside "math". It was simply too cumbersome to type everywhere all those lenghty namespace names (and I used various variants, including 2d / 3d distinction). Therefore I strongly suggest to use simply namespace "math" and put inside vector2d, vector3d, quaternion and matrix. Extra namespaces increase fragmentation. Also please kindly consider following exampls, what name is more descriptive and shorter? three_d::vect math::vector3d OK, my favourite name is one letter longer, but still - "math" says a lot more that "three_d", so this name is more descriptive, IMHO. Please be verbose, please rename vect to vector3d and vector2d, when putting them into single namespace. Also I prefer name quaternion, over quat. I'm sorry about elaborating so much about this topic - that's because it's close to my heart. In fact I can adapt to any library layout which Andy choses, but what others think? I believe that in matrices there is no need to support both row-column and column-row notation explicitly, but rather to keep internal compatibility thorough whole library. Based on that I'd strongly suggest to rename rc_matrix into matrix, and never implement cr_matrix. There is an interesting reasoning about this problem inside panda3d software manual (given time I'll find it later). It's nice to see timer included. (but missing from docs?) It would be nice if t1_quantity was renamed to some descriptive word. Perhaps a discussion on the mailing list would help to discover a better word. I did not delve as much as I would want into the implementation of t1_quantity, due to lack of time. I noticed that there are two similar files, length.hpp and length_.hpp, but there is no force_.hpp, or any other file with _ at the end. This puzzles me a bit. --------------------------------------------------- * What is your evaluation of the design? The design as shown on the Entity Relationship Diagram ( /libs/pqs/doc/html/pqs/pqs_erm.html ) is so clear, that I can hardly imagine making a better design. It must be noted however that I've never written my own units library. I'm not sure if fixing number of dimensions to exactly 7 is good decision, perhaps it could be changed at later date, after the library is included to boost. Those extra dimensions would be non-si of course, but could be useful for some people (storage capacity of a harddrive comes to mind, or unit of information measured with libraries of congress ;). It's good that Andy plans to implement vector, matrix and quaternions operations, that will perform necessary unit checking during computation (all at compile time!). My concern however is that Finite Element Method uses large matrices (for example with 1000 columns), and I'm sure that users will prefer to stick with ublas and all functionality provided by libraries they are already using. Instead of more general (and perhaps impossible) solution that would allow use of pqs with any other math library, I recommend to investigate tight integration with boost::numeric::ublas. I'm sure that people responsible for that library will gladly accept the idea, and accept any patches related to this. Basically this will make boost::ublas a ,,sort of'' part of pqs. Other solution would be to reimplement such huge matrices in pqs, but how far Andy could go? --------------------------------------------------- * With what compiler did you try the library? gcc version 3.3.5 (Debian 1:3.3.5-13) I have compared compilation times with and without pqs. Whole yade consists of over 20000 lines of C++ and it compiles in 10minutes on my AMD 4400+ (when I'm too lazy to use distcc which can reduce this time to 3 minutes - ideal when I'm in hurry). Because pqs is just in one small module (about 100 lines of code) I measured the time for compiling only this module. I took 5 measures, and computed average: without pqs: 3.8 seconds with pqs : 4.8 seconds That gives about 21% increase. It would mean that if I used pqs in whole yade 10 minutes could possibly become 12 (or 4 minutes with distcc). not much difference I think. Full recompiles do not happen often, anyways. --------------------------------------------------- * Did you try to use the library? Did you have any problems? First I've compiled some of the examples without any problems at all. When working with the first example I discovered that it would be nice if include path for headers was shorter, like following: #include <boost/units/length.hpp> // to get length #include <boost/units/io/length.hpp> // or sth similar to get IO for length. (input.hpp is OK too) When working with the examples I decided to add quaternions to pqs, because in yade quaternion calculations play a crucial role. I used three_d::vect as a base source file. I was really pleasently surprised how easy adding them turned out to be! I was afraid that some unexpected obstacles will stop me on my way (which will cause this review to be send after the deadline of 9.june (oops it's after the deadline now!)). I've sent this quaternion implementation to Andy privately, I hope that it will be included. It lacks many commonly used methods, but the base foundation for it is prepared, which I consider a success of pqs design. I should stress again, that I've virtually done nothing in effort that those quaternions will support units - those units were supported right away. Only thing I didn't know (but didn't consider important - as I spent less than 2h to complete the task) - was how to define a return type of squared unit (used by method squared_magnitude() ). Then I started to adapt yade to pqs. I decided to use units only in one module - that one where the actual calculation loop for selected simulation resides (the most crucial part of whole simulation). Yade is capable of modelling various models, so I picked the most causal one - simple DEM simulation: spheres falling onto flat plane below: http://tinyurl.com/hjy9g . Pqs was used only in simulation loop, so I expected extra slowdown due to converting data to/from physical quantities at the start/end of each loop. However it was simpler than converting all the data structures in yade. During the process I needed a unit to express a spring stiffness (hooke's law F=kx, where k is [N/m] and x is [m]). But because Fred Bertsch has just now posted an email that "review ends" I decided not to add a new unit N_div_m, but rather I used Pa that was multiplied during calculations by 1 meter constant (so maybe adding new units should be made simpler). During the process of adapting yade to use pqs I was impressed in overall how easy it did come by. As an indicator: on the first time when my modified code compiled without errors it was running correctly. I was really surprised, and this shows the power of units. Especially when I recall how much time I've spent more than year ago to debug this code! This gives me a clear picture of how much time can be saved with pqs library. How often your code, dear reader, ran correctly after the first compile? ;) First thing I did after sucessfully compiling was to perform a unit test simulation and compare the simulation state. I did this by running the simulation for 1000 iterations (all the spheres dropped down to the flat plane below and formed a pile), and saving spheres coordinates and their orientation every 50th iteration. I used type double for whole calculation, and boost::lexical_cast<std::string>(double) to save coordinates with 16 decimal places. So I had 20 files from each run, which I could compare between pqs and non-pqs version. Comparing them showed that in 100th iteration about 20 spheres (out of 1000) had coordinates differing on the last decimal place. In 150th iteration all spheres' coordinates differed on average on last 2 decimal places. In 200th it was 3 last decimal places. The difference was growing during time. In 500th it was last 8 decimal places. Due to the chaotic nature of this simulation, every error will accumulate and grow. So I can conclude that in the simulation loop with pqs there appeared a small chance of having different last digit than expected. And this error accumulated over time. I'm not sure if this error is caused by pqs, or maybe by extra assignments and conversions. Personally I think that it's because the order in which components of the equation were added and multiplied was changed. After performing above checks (aka. unit test) I did speed test, to benchmark pqs. Results are not in favor of pqs, but then I should remind that they are skewed due to extra constructor calls in pqs version. Those constructor calls would not be here if I converted whole yade's data structure to pqs. So perhaps I should not make those results public? Since I have no time now to consider whether to make them public or not, here they are: without pqs (three runs): Computation time: 370.939 seconds Computation time: 382.615 seconds Computation time: 360.418 seconds with pqs - and extra constructor calls, which would be avoided if I converted whole data structure! (three runs): Computation time: 415.724 seconds Computation time: 423.181 seconds Computation time: 421.799 seconds that makes a difference of roughly 11% - 13% Previously when working with this code I've seen a speed difference of ~2% just because of one extra constructor call in this loop. While I performed this benchmark with good intentions I still cannot say whether pqs is slower or not. This question will be answered when I fully convert yade to pqs. It's possible that I will discover something new with kcachegrind profiler - but due to the lack of time (review deadline) I cannot post profiler results now. If anybody wants to see the code I used it's here: http://tinyurl.com/r83tr , while the original code is here: http://tinyurl.com/ouhbc . Quick glance at the code shows 21 extra assignments of double, and 9 extra construtcor calls. Also I should note here, that during my work with yade, every time I made a design decision which favored clean design over calculation speed I was later rewarded. The reward was, that clean design allowed unexpected optimizations in different pieces of code, which at the end resulted in faster calculation speed. I have reasons to believe that this will be also the case with pqs. During this adaptation of yade to pqs I encountered only one small obstacle: operator *= for vect was missing. I had to write { vect1 = vect1 * some_scalar;}; Also vect has a function magnitude(), please add squared_magnitude(). I tried to add it myself, but got lost in defining a squared return type. --------------------------------------------------- * How much effort did you put into your evaluation? A glance? A quick reading? In-depth study? As much as a human can, given just 48 hours. Sounds a bit funny - that's because earlier I was not aware that any boost mailing list member can perform a review. So maybe it qualifies even as an in-depth study, but I'm not sure. --------------------------------------------------- * Are you knowledgeable about the problem domain? Instead of claiming good (or bad knowledge) I should rather describe my background, which should let you decide whether I'm knowledgeable: Physics : I'm working at a technical university, doing a PhD which focuses on modelling behavior of concrete. I'm familiar with Finite Element Method, with Discrete approach, with various material models (viscoelastic, hypoplastic, cohesive, etc). I've had experience with modelling granular materials and cloth. Currently I'm developing (mentioned earlier) a framework for performing physical simulatios - http://yade.berlios.de/ . I have 16 english-language publications (9 of them are just conference materials, 6 of them are in scientific journals, and 1 is in renowed scientific journal "Granular Matter"). No more details, as I feel now like boasting ;) C++ : I have over 10 years experience with programming in C++ (mostly guided by my brother Bronek who is more active on this mailing list ;). As my achievements in this field I'd like to list serialization library in yade. After thorough testing we decided that boost::serialization does not qualify for our needs - we needed not-on-the-fly serialization (important design decision), and better support for various formats - xml easier to read by human, binary, text, etc. We even developed a backend which allows to serialize classes (their registered components) into QT dialog window (well, currently unfinished, as containers are left out, but soon this will be fixed). Another would be a multimethods library in yade, I made it as a "dreaded excercise left for the reader" - those words Andrei Alexandrescu used at the end of his chapter about multimethods in "Modern C++ Design". In this implementation recursive templates allow theoretically unlimited number of dimensions (at this moment only 3 are used), and up to 15 arguments in multimethod call. This library focuses on speed, so a callback matrix is used. By looking at this source code (in subversion repository of yade http://tinyurl.com/hxbr7 ) you can judge my familiarity with C++. (I'm more proud of multimethods in terms of template programming, so look there first, serialization is still waiting for some cleaning ;) --------------------------------------------------- * What is your evaluation of the potential usefulness of the library? For people working in science and engineering this library is extremely useful. There is a bad need for such library in the scientific community. I had a chance to envision myself how pqs reduces the chance of making stupid mistake in calculations. Once my code compiled without errors it was correct! If I recall now how much time I've spent debugging this code more than year ago, I see that pqs allows to save huge amounts of time. --------------------------------------------------- * Other random comment: I feel there is a need for another discussions how to call this library in boost. Most people do not like "pqs", some people (including me) prefer name "units", but others have strong and reasonable arguments against name "units" (but I'm not sure if anything else was proposed). -- Janek Kozicki |
Janek Kozicki said: (by the date of Sat, 10 Jun 2006 02:17:33 +0200)
--------------------------------------------------- * What is your evaluation of the documentation?
actually this first section is quite boring, and repeats comments of other people. Fell free to skip that. More interesting stuff is below ;) -- Janek Kozicki |

Hi Janek, "Janek Kozicki" wrote
Hello,
I'm posting this review a bit after the deadline, and I'm very sorry about that. This is caused by the fact that I didn't know that all mailing list members can write a review. When I learned about that, I had only about 2 days left, but still I wanted to perform a deep analysis of what is in pqs.
--------------------------------------------------- * Do you think the library should be accepted as a Boost library?
Yes, I think it should. The scientific community, and industry are in desperate need of such library, rejecting it just because it's not perfect would be a very bad decision. It's not uncommon that boost libraries evolve once included, I believe that this will be the case here. Moreover including it will greatly increase the amount of feedback received and in result the library will reach the "perfect" state much faster. After performing checks (described below) I'm sure that the library is ready for inclusion.
Great. Thanks for the yes vote.
Note: below I often refer to yade ( http://yade.berlios.de/ ) which is a framework for performing scientific simulations. Yade is my current project, and a part of my PhD.
Yes, I know yade or at least watched some sample videos. Its a great project I have done tests of using pqs inside yade, performed
speed benchmarks and unit tests.
OK. I havent done anything but very minor performance tests on pqs, so that will be interesting.
--------------------------------------------------- * What is your evaluation of the documentation?
Before trying pqs I've read almost whole documentation (skipped few pages). So those comments and suggestions below were written before I actually tried using pqs:
As stated by other reviewers the introduction is a bit offtopic. Summary given by review manager fits here best. In "Definition of terms" an UML diagram would be nice, or at least some of those diagrams that are automatically generated by doxygen. Later I discovered that in html version there is a diagram, but not in pdf version. I wonder if any other reviewer would complain less if he saw this diagram in pdf. Downloading pdf was much easier than unpacking the library and opening index.html from it ;)
Yes it was a bit too easy!
I'd prefer a different name for coherent_unit and incoherent_unit, for example si_unit and non_si_unit.
OK.
Several terms ( 'dimensional analysis', 'dimensionally_equivalent', 'dimensional_math', 'dimensionless', 'dimensionful', 'physical_quantity', 'physical_quantity_system', 'rational_number', 'unit_output_symbol', 'unit_symbol' ) do not appear on the Entity Relationship Diagram. Therefore their meaning is for me unclear: classes, methods or concepts? If they are concepts then underscore ("_") shouldn't be used in their name. Method names can be written in the ERD diagram inside rectangle of a given class, separated by horizontal line (UML notation), so that it would be possible to look up methods in the diagram.
OK. I need to study UML for diagrams
Also a reference-style listing of all classes and methods in the library would be nice (this kind of documentation is usually auto generated by doxygen). This listing would have references to correct places in synopsis. It would be also *very* useful if at the end of the doc, there was a referenced list of all examples in the manual, and also a list of all pictures.
OK.
In Rationale:Clarity section the example with PQ_Box should be written full 'ready to compile' (because it is the first longer example that appears in the manual).
OK.
Also IMHO Rationale section should be put before Definition of terms. Usually definition of terms is put at the beginning, but usually it is much shorter. A causal reader who doesn't know what he should read, will read from top to bottom - and in this respect it's more important that he reads Rationale first. Because if he reads Definitions first - he may lose his enthusiasm due to fact that definitions are _always_ boring (no matter how hard you try to make them interesting).
IMO the optimal layout for documentation is a hierachical (or star) structure rather than a serial one. In using Quickbook I traded convenience for flexibility. OTOH I guess the serial style works for pdf's.
I prefer "per": m_per_s, etc...
OK. I think the majority do too.
In pdf page 3, missing space: "The keyword typeofis used".
In pdf page 5, missing space: "distinguish between different but dimensionally_equivalentabstract_quantities."
QuickBook 1.1? is to blame for that one AFAICS by concatenating adjacent links. (Since then I have discovered how to add explicit spaces)
In pdf page 18 there is a reference to "Example 3a", but all examples are unlabelled, so I can only detect from the context of the sentence which example is actually referred. It would be useful to label all examples. (and make a full list of all examples at the end).
That shows the vintage of the example. Its copy pasted from Example 3a in the pqs 2 series docs. Yes. All examples should be numbered. In fact stuff such as sections, paragraphs, diagrams etc should be numbered.
In pdf page 23 comment is too long to fit on the page.
In pdf page 28 - mistaken underline
In pdf page 32 - I prefer synopsis written in valid C++, for example simple copy'n'paste from file t1_quantity.hpp would work. In fact I had difficulty in understanding line "if IsDimensionless<abstract_quantity>", and lines following it, until I guessed that it's some kind of Cpp pseudocode.
I could make it clear and maybe try to follow conventions too. Maybe I should make like GIL: http://opensource.adobe.com/structPoint2DConcept.html
In pdf page 51 - mistaken underline.
I think that might be an problem in the Quickbook --> pdf chain.
Word "useage" hurts my eyes. Heh, and vim's spellchecker underlines it as a bad word ;)
OK. bad spelling.
--------------------------------------------------- * What is your evaluation of the implementation?
More constants, including mathematical ones, would be nice.
The selection included is just for demonstration. All the constants in SP961 should be included: http://physics.nist.gov/cuu/pdf/chart1.pdf
I don't like the separation of "three_d" and "two_d" - where quaternions should be put then - "four_d" ?
My rationale is that quaternions exist in a 3D space. OTOH complex would be in two_d because it exists in a 2D space.
I've gone through similar problems in my own design (just browse older revisions of yade in subversion repository http://tinyurl.com/lgk8t ), and finally I've found it most convenient to put vector (both 2d and 3d), quaternion and matrix inside "math". It was simply too cumbersome to type everywhere all those lenghty namespace names (and I used various variants, including 2d / 3d distinction). Therefore I strongly suggest to use simply namespace "math" and put inside vector2d, vector3d, quaternion and matrix. Extra namespaces increase fragmentation.
OK.
Also please kindly consider following exampls, what name is more descriptive and shorter?
three_d::vect math::vector3d
OK, my favourite name is one letter longer, but still - "math" says a lot more that "three_d", so this name is more descriptive, IMHO.
Maybe even lose math:: ?
Please be verbose, please rename vect to vector3d and vector2d, when putting them into single namespace. Also I prefer name quaternion, over quat.
OK.
I'm sorry about elaborating so much about this topic - that's because it's close to my heart. In fact I can adapt to any library layout which Andy choses, but what others think?
IMO it makes sense to put 3D entities in a 3D space and 2D entities in a 2D space, but its not critical to me either way
I believe that in matrices there is no need to support both row-column and column-row notation explicitly, but rather to keep internal compatibility thorough whole library. Based on that I'd strongly suggest to rename rc_matrix into matrix, and never implement cr_matrix. There is an interesting reasoning about this problem inside panda3d software manual (given time I'll find it later).
Its certainly less work sticking to one type of matrix so I dont object to that. There may be performance resaons to choose on or other type?
It's nice to see timer included. (but missing from docs?)
It was a bit of fun for intended for simple performance timing, but should be documented yes.
It would be nice if t1_quantity was renamed to some descriptive word. Perhaps a discussion on the mailing list would help to discover a better word.
Perhaps just quantity1, quantity2, quantity3 or quantitya, quantityb, quantityc.
I did not delve as much as I would want into the implementation of t1_quantity, due to lack of time. I noticed that there are two similar files, length.hpp and length_.hpp, but there is no force_.hpp, or any other file with _ at the end. This puzzles me a bit.
Oops...length_.hpp should have been removed from the package.
--------------------------------------------------- * What is your evaluation of the design?
The design as shown on the Entity Relationship Diagram ( /libs/pqs/doc/html/pqs/pqs_erm.html ) is so clear, that I can hardly imagine making a better design. It must be noted however that I've never written my own units library.
I need to redo it usin the correct symbols maybe and see if it can be used for other systems than SI or not.
I'm not sure if fixing number of dimensions to exactly 7 is good decision, perhaps it could be changed at later date, after the library is included to boost. Those extra dimensions would be non-si of course, but could be useful for some people (storage capacity of a harddrive comes to mind, or unit of information measured with libraries of congress ;).
I think the number of dimensions could be configurable. This is dependent on PQS becoming superceded too though, because PQS is only useful in SI IMO.
It's good that Andy plans to implement vector, matrix and quaternions operations, that will perform necessary unit checking during computation (all at compile time!). My concern however is that Finite Element Method uses large matrices (for example with 1000 columns), and I'm sure that users will prefer to stick with ublas and all functionality provided by libraries they are already using. Instead of more general (and perhaps impossible) solution that would allow use of pqs with any other math library, I recommend to investigate tight integration with boost::numeric::ublas. I'm sure that people responsible for that library will gladly accept the idea, and accept any patches related to this. Basically this will make boost::ublas a ,,sort of'' part of pqs. Other solution would be to reimplement such huge matrices in pqs, but how far Andy could go?
I dont know if its possible. Another option is to cast the quantities to numerics. IOW exit the type checking. I will have to ask on the ublas list.
--------------------------------------------------- * With what compiler did you try the library?
gcc version 3.3.5 (Debian 1:3.3.5-13)
I have compared compilation times with and without pqs. Whole yade consists of over 20000 lines of C++ and it compiles in 10minutes on my AMD 4400+ (when I'm too lazy to use distcc which can reduce this time to 3 minutes - ideal when I'm in hurry). Because pqs is just in one small module (about 100 lines of code) I measured the time for compiling only this module. I took 5 measures, and computed average:
without pqs: 3.8 seconds with pqs : 4.8 seconds
That gives about 21% increase. It would mean that if I used pqs in whole yade 10 minutes could possibly become 12 (or 4 minutes with distcc). not much difference I think. Full recompiles do not happen often, anyways.
It is interesting to see the comparison. I spent some time trying to keep compile times down.
--------------------------------------------------- * Did you try to use the library? Did you have any problems?
First I've compiled some of the examples without any problems at all. When working with the first example I discovered that it would be nice if include path for headers was shorter, like following:
#include <boost/units/length.hpp> // to get length #include <boost/units/io/length.hpp> // or sth similar to get IO for length. (input.hpp is OK too)
I think that is better than the current arrangement.
When working with the examples I decided to add quaternions to pqs, because in yade quaternion calculations play a crucial role. I used three_d::vect as a base source file. I was really pleasently surprised how easy adding them turned out to be! I was afraid that some unexpected obstacles will stop me on my way (which will cause this review to be send after the deadline of 9.june (oops it's after the deadline now!)). I've sent this quaternion implementation to Andy privately, I hope that it will be included.
Yes Thanks! I am currently digesting it!
It lacks many commonly used methods, but the base foundation for it is prepared, which I consider a success of pqs design. I should stress again, that I've virtually done nothing in effort that those quaternions will support units - those units were supported right away. Only thing I didn't know (but didn't consider important - as I spent less than 2h to complete the task) - was how to define a return type of squared unit (used by method squared_magnitude() ).
This currently just uses the binary_operation function as elsewhere, but may be simpler with Boost Typeof
Then I started to adapt yade to pqs. I decided to use units only in one module - that one where the actual calculation loop for selected simulation resides (the most crucial part of whole simulation). Yade is capable of modelling various models, so I picked the most causal one - simple DEM simulation: spheres falling onto flat plane below: http://tinyurl.com/hjy9g . Pqs was used only in simulation loop, so I expected extra slowdown due to converting data to/from physical quantities at the start/end of each loop. However it was simpler than converting all the data structures in yade. During the process I needed a unit to express a spring stiffness (hooke's law F=kx, where k is [N/m] and x is [m]). But because Fred Bertsch has just now posted an email that "review ends" I decided not to add a new unit N_div_m, but rather I used Pa that was multiplied during calculations by 1 meter constant (so maybe adding new units should be made simpler). During the process of adapting yade to use pqs I was impressed in overall how easy it did come by. As an indicator: on the first time when my modified code compiled without errors it was running correctly. I was really surprised, and this shows the power of units.
That is good to hear.
Especially when I recall how much time I've spent more than year ago to debug this code! This gives me a clear picture of how much time can be saved with pqs library. How often your code, dear reader, ran correctly after the first compile? ;)
If it could be achieved with no drop in performance then it will be near perfect!
First thing I did after sucessfully compiling was to perform a unit test simulation and compare the simulation state. I did this by running the simulation for 1000 iterations (all the spheres dropped down to the flat plane below and formed a pile), and saving spheres coordinates and their orientation every 50th iteration. I used type double for whole calculation, and boost::lexical_cast<std::string>(double) to save coordinates with 16 decimal places.
So I had 20 files from each run, which I could compare between pqs and non-pqs version. Comparing them showed that in 100th iteration about 20 spheres (out of 1000) had coordinates differing on the last decimal place. In 150th iteration all spheres' coordinates differed on average on last 2 decimal places. In 200th it was 3 last decimal places. The difference was growing during time. In 500th it was last 8 decimal places. Due to the chaotic nature of this simulation, every error will accumulate and grow. So I can conclude that in the simulation loop with pqs there appeared a small chance of having different last digit than expected. And this error accumulated over time. I'm not sure if this error is caused by pqs, or maybe by extra assignments and conversions. Personally I think that it's because the order in which components of the equation were added and multiplied was changed.
OK. I don't know what is causing this, except that pqs changes division and multiplication in some cases. I also use Boost Numeric converter. I guess I will need to look into the actual code to determine this. I had better admit that the implementation is not very pretty and should be totally reworked.
After performing above checks (aka. unit test) I did speed test, to benchmark pqs. Results are not in favor of pqs, but then I should remind that they are skewed due to extra constructor calls in pqs version. Those constructor calls would not be here if I converted whole yade's data structure to pqs. So perhaps I should not make those results public? Since I have no time now to consider whether to make them public or not, here they are:
without pqs (three runs): Computation time: 370.939 seconds Computation time: 382.615 seconds Computation time: 360.418 seconds
with pqs - and extra constructor calls, which would be avoided if I converted whole data structure! (three runs): Computation time: 415.724 seconds Computation time: 423.181 seconds Computation time: 421.799 seconds
that makes a difference of roughly 11% - 13%
OK. Bear in mind that I have spent no time in optimising PQS for performance. The use of pqs for dimensional analysis checking and best performance may need to consist in writing code using typedef defined so that quantities/ floating point types are swapped in to do dimensional analysis then swapped out in favour of floats in finished code. I have written some code this way. Within certain rules ( no operations that scales a value between units for example, which could be set up to flag an error) it should be the most effective method. All these useages are possible including the default style, the SI_units style preferred by Jesper Schmidt and the style described above... using another 'view'/ frontend or call it what you will on the underlying type.
Previously when working with this code I've seen a speed difference of ~2% just because of one extra constructor call in this loop. While I performed this benchmark with good intentions I still cannot say whether pqs is slower or not. This question will be answered when I fully convert yade to pqs. It's possible that I will discover something new with kcachegrind profiler - but due to the lack of time (review deadline) I cannot post profiler results now. If anybody wants to see the code I used it's here: http://tinyurl.com/r83tr , while the original code is here: http://tinyurl.com/ouhbc . Quick glance at the code shows 21 extra assignments of double, and 9 extra construtcor calls.
Also I should note here, that during my work with yade, every time I made a design decision which favored clean design over calculation speed I was later rewarded. The reward was, that clean design allowed unexpected optimizations in different pieces of code, which at the end resulted in faster calculation speed. I have reasons to believe that this will be also the case with pqs.
Yes. High performance hasnt had much work done on it. I suspect that some of my attempts at code enhancement might have caused slow downs. I should test different implementations, which I havent done.
During this adaptation of yade to pqs I encountered only one small obstacle: operator *= for vect was missing. I had to write { vect1 = vect1 * some_scalar;};
Also vect has a function magnitude(), please add squared_magnitude(). I tried to add it myself, but got lost in defining a squared return type.
OK. vect is quite new and unfinished, needs a lot of work and tests of course.
--------------------------------------------------- * How much effort did you put into your evaluation? A glance? A quick reading? In-depth study?
As much as a human can, given just 48 hours. Sounds a bit funny - that's because earlier I was not aware that any boost mailing list member can perform a review. So maybe it qualifies even as an in-depth study, but I'm not sure.
Maybe. Its a very impressive review all round .
--------------------------------------------------- * Are you knowledgeable about the problem domain?
Instead of claiming good (or bad knowledge) I should rather describe my background, which should let you decide whether I'm knowledgeable:
Physics : I'm working at a technical university, doing a PhD which focuses on modelling behavior of concrete. I'm familiar with Finite Element Method, with Discrete approach, with various material models (viscoelastic, hypoplastic, cohesive, etc). I've had experience with modelling granular materials and cloth. Currently I'm developing (mentioned earlier) a framework for performing physical simulatios - http://yade.berlios.de/ . I have 16 english-language publications (9 of them are just conference materials, 6 of them are in scientific journals, and 1 is in renowed scientific journal "Granular Matter"). No more details, as I feel now like boasting ;)
C++ : I have over 10 years experience with programming in C++ (mostly guided by my brother Bronek who is more active on this mailing list ;). As my achievements in this field I'd like to list serialization library in yade. After thorough testing we decided that boost::serialization does not qualify for our needs - we needed not-on-the-fly serialization (important design decision), and better support for various formats - xml easier to read by human, binary, text, etc. We even developed a backend which allows to serialize classes (their registered components) into QT dialog window (well, currently unfinished, as containers are left out, but soon this will be fixed). Another would be a multimethods library in yade, I made it as a "dreaded excercise left for the reader" - those words Andrei Alexandrescu used at the end of his chapter about multimethods in "Modern C++ Design". In this implementation recursive templates allow theoretically unlimited number of dimensions (at this moment only 3 are used), and up to 15 arguments in multimethod call. This library focuses on speed, so a callback matrix is used. By looking at this source code (in subversion repository of yade http://tinyurl.com/hxbr7 ) you can judge my familiarity with C++. (I'm more proud of multimethods in terms of template programming, so look there first, serialization is still waiting for some cleaning ;)
--------------------------------------------------- * What is your evaluation of the potential usefulness of the library?
For people working in science and engineering this library is extremely useful. There is a bad need for such library in the scientific community. I had a chance to envision myself how pqs reduces the chance of making stupid mistake in calculations. Once my code compiled without errors it was correct! If I recall now how much time I've spent debugging this code more than year ago, I see that pqs allows to save huge amounts of time.
I am glad to hear it. Now all thats needed is the original performance.
--------------------------------------------------- * Other random comment:
I feel there is a need for another discussions how to call this library in boost. Most people do not like "pqs", some people (including me) prefer name "units", but others have strong and reasonable arguments against name "units" (but I'm not sure if anything else was proposed).
It might be good to see what emerges out of the review. Maybe an enhanced units library. If so pqs might keep its name for reference/ comparison with the new library. Thanks for the very comprehensive review. Oh and the vote too! regards Andy Little

Just a few observations... On 6/10/06, Andy Little <andy@servocomm.freeserve.co.uk> wrote:
IMO it makes sense to put 3D entities in a 3D space and 2D entities in a 2D space, but its not critical to me either way
Can the vector not be templated on length? I know a simple (dimensionless) vector can be templated on length ( http://gpwiki.org/index.php/C_plus_plus:Tutorials:TemplateVector ), but perhaps PQS needs something that prevents this...
I believe that in matrices there is no need to support both row-column and column-row notation explicitly, but rather to keep internal compatibility thorough whole library. Based on that I'd strongly suggest to rename rc_matrix into matrix, and never implement cr_matrix. There is an interesting reasoning about this problem inside panda3d software manual (given time I'll find it later).
Its certainly less work sticking to one type of matrix so I dont object to that. There may be performance resaons to choose on or other type?
If the internal storage for the matrix is usable as an array, interfacing with different C apis would be much easier if the ordering could be chosen (or at least relied upon). As I recall, OpenGL uses column-major and DirectX uses row-major, so there could be big savings in not needing to copy the values when passing the data to those APIs.
me22 said: (by the date of Sat, 10 Jun 2006 14:07:12 -0400)
Can the vector not be templated on length?
no. there is no need for that.
If the internal storage for the matrix is usable as an array, interfacing with different C apis would be much easier if the ordering could be chosen (or at least relied upon). As I recall, OpenGL uses column-major and DirectX uses row-major, so there could be big savings in not needing to copy the values when passing the data to those APIs.
purpose of units library is not to provide interface with graphic libraries. it might work, it might not. -- Janek Kozicki |
Andy Little said: (by the date of Sat, 10 Jun 2006 17:58:35 +0100) Hello :) <snip>
It would be nice if t1_quantity was renamed to some descriptive word. Perhaps a discussion on the mailing list would help to discover a better word.
Perhaps just quantity1, quantity2, quantity3 or quantitya, quantityb, quantityc.
OK, I'll give it a shot, because the point is not to move number (or letter) to the end of the name: # t1_quantity where the dimension and unit are fixed [during compilation]. fixed_quantity // it's fixed, right? # t2_quantity where the dimension is fixed [during compilation] but the unit can be modified at runtime. scalable_quantity // changing unit means, that the underlying numbers are scaled # t3_quantity where the dimension and unit can be modified at runtime. free_quantity // it's free, right? <snip>
I recommend to investigate tight integration with boost::numeric::ublas. I'm sure that people responsible for that library will gladly accept the idea, and accept any patches related to this. Basically this will make boost::ublas a ,,sort of'' part of pqs. Other solution would be to reimplement such huge matrices in pqs, but how far Andy could go?
I dont know if its possible. Another option is to cast the quantities to numerics. IOW exit the type checking. I will have to ask on the ublas list.
I must admit that I don't know where to start. Asking on ublas list is a very good idea. I remember that Noel Belcourt spent some time trying to adapt his Finite Element code to pqs - maybe he has some interesting suggestions about that. <snip>
OK. I need to study UML for diagrams
start here: http://www.objectmentor.com/resources/listArticles?key=topic&topic=UML <snip>
until I guessed that it's some kind of Cpp pseudocode. I could make it clear and maybe try to follow conventions too. Maybe I should make like GIL:
I'd prefer real C++, what others think? <snip>
OK, my favourite name is one letter longer, but still - "math" says a lot more than "three_d", so this name is more descriptive, IMHO.
Maybe even lose math:: ?
hmm.. I'm not sure. maybe better not. Having vector3d in the same directory/namespace as unit length makes me feel uneasy. boost::units::math - is clear to understand - math classes with support for units. I don't mind writing one extra namespace name when it makes perfect sense. Paul said wisely: "write once, read many". Math constants will also reside there. <snip>
rename rc_matrix into matrix, and never implement cr_matrix. There is an interesting reasoning about this problem inside panda3d software manual (given time I'll find it later).
Its certainly less work sticking to one type of matrix so I dont object to that. There may be performance resaons to choose on or other type?
I have found that excerpt in panda3d manual. But for whatever reasons in new release of manual they have removed this chapter. So I can't point some URL to it, instead I have added it as an attchment. (Note to readers: it is .html, you might want open it in your favourite browser). There shouldn't be any performance differences. It's just that vectors will work with matrices (be internally compatibile). And that's all. <snip>
without pqs: 3.8 seconds with pqs : 4.8 seconds
It is interesting to see the comparison. I spent some time trying to keep compile times down.
IMHO compilation time is not that important. We have distcc, and processors are getting faster and multicore. Design, (and runtime speed, which comes with good design) - that's what really matters. <snip>
#include <boost/units/length.hpp> // to get length #include <boost/units/io/length.hpp> // or sth similar to get IO for length. (input.hpp is OK too)
I think that is better than the current arrangement.
yeah :) <snip>
use a typedef defined so that quantities/ floating point types are swapped in to do dimensional analysis then swapped out in favour of floats in finished code. I have written some code this way.
that would be a nice option. At least to compare perfomance difference: speed with and without units.
All these usages are possible including the default style, the SI_units style preferred by Jesper Schmidt and the style described above...
I can't find his posts on the mailing list... <snip>
operator *= for vect was missing. I had to write { vect1 = vect1 * some_scalar;}; Also vect has a function magnitude(), please add squared_magnitude().
OK. vect is quite new and unfinished, needs a lot of work and tests of course.
I bet I can help a bit with that. -- Janek Kozicki |
{kind=link}
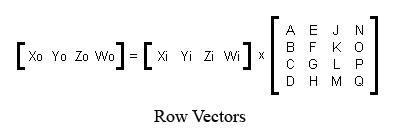{kind=link}
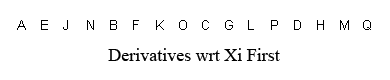{kind=link}
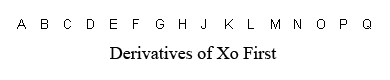{kind=link}
Janek Kozicki said: (by the date of Sat, 10 Jun 2006 22:07:36 +0200)
I have found that excerpt in panda3d manual. But for whatever reasons in new release of manual they have removed this chapter. So I can't point some URL to it, instead I have added it as an attchment. (Note to readers: it is .html, you might want open it in your favourite browser).
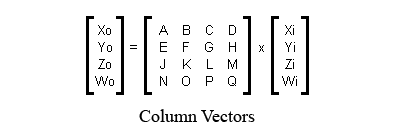
oops. I see that this .html got stripped out for unknown reasons. Copy/paste below. see pictures attached to previous post. -- Janek Kozicki | Periodically, the question arises: does Panda store matrices in column-major or row-major format? Unfortunately, people who ask that question often fail to realize that there are four ways to represent matrices, two of which are called "column major," and two of which are called "row major." So the answer to the question is not very useful. This section explains the four possible ways to represent matrices, and then explains which one panda uses. The Problem In graphics, matrices are mainly used to transform vertices. So one way to write a matrix is to write the four transform equations that it represents. Assuming that the purpose of a matrix is to transform an input-vector (Xi,Yi,Zi,Wi) into an output vector (Xo,Yo,Zo,Wo), the four equations are: Xo = A*Xi + B*Yi + C*Zi + D*Wi Yo = E*Xi + F*Yi + G*Zi + H*Wi Zo = J*Xi + K*Yi + L*Zi + M*Wi Wo = N*Xi + O*Yi + P*Zi + Q*Wi There are two different orders that you can store these coefficients in RAM: Storage Option 1: A,B,C,D,E,F,G,H,J,K,L,M,N,O,P,Q Storage Option 2: A,E,J,N,B,F,K,O,C,G,L,P,D,H,M,Q Also, when you're typesetting these coefficients in a manual (or printing them on the screen), there are two possible ways to typeset them: A B C D E F G H J K L M N O P Q Typesetting Option 1 A E J N B F K O C G L P D H M Q Typesetting Option 2 These are independent choices! There is no reliable relationship between the order that people choose to store the numbers, and the order in which they choose to typeset them. That means that any given system could use one of four different notations. So clearly, the two terms "row major" and "column major" are not enough to distinguish the four possibilities. Worse yet, to my knowledge, there is no established terminology to name the four possibilities. So the next part of this section is dedicated to coming up with a usable terminology. The Coefficients are Derivatives The equations above contain sixteen coefficients. Those coefficients are derivatives. For example, the coefficient "G" could also be called "the derivative of Yo with respect to Zi." This gives us a handy way to refer to groups of coefficients. Collectively, the coefficients "A,B,C,D" could also be called "the derivatives of Xo with respect to Xi,Yi,Zi,Wi" or just "the derivatives of Xo" for short. The coefficients "A,E,J,N" could also be called "the derivatives of Xo,Yo,Zo,Wo with respect to Xi" or just "the derivatives with respect to Xi" for short. This is a good way to refer to groups of four coefficients because it unambiguously names four of them without reference to which storage option or which typesetting option you choose. What to Call the Two Ways of Storing a Matrix. So here, again, are the two ways of storing a matrix. But using this newfound realization that the coefficients are derivatives, I have a meaningful way to name the two different ways of storing a matrix: Image:deriv-xo.png Image:deriv-xi.png In the first storage scheme, the derivatives of Xo are stored first. In the second storage scheme, the derivatives with respect to Xi are stored first. What to Call the Two Ways of Printing a Matrix. One way to write the four equations above is to write them out using proper mathematical notation. There are two ways to do this, shown below: Image:matrix-c.png Image:matrix-r.png Notice that the two matrices shown above are laid out differently. The first layout is the appropriate layout for use with column vectors. The second layout is the appropriate layout for use with row vectors. So that gives me a possible terminology for the two different ways of typesetting a matrix: the "row-vector-compatible" notation, and the "column-vector-compatible" notation. The Four Possibilities So now, the four possible representations that an engine could use are: 1. Store derivatives of Xo first, typeset in row-vector-compatible notation. 2. Store derivatives of Xo first, typeset in column-vector-compatible notation. 3. Store derivatives wrt Xi first, typeset in row-vector-compatible notation. 4. Store derivatives wrt Xi first, typeset in column-vector-compatible notation. The Terms "Column Major" and "Row Major" The term "row-major" means "the first four coefficients that you store, are also the first row when you typeset." So the four possibilities break down like this: 1. Store derivatives of Xo first, typeset in row-vector-compatible notation (COLUMN MAJOR) 2. Store derivatives of Xo first, typeset in column-vector-compatible notation (ROW MAJOR) 3. Store derivatives wrt Xi first, typeset in row-vector-compatible notation (ROW MAJOR) 4. Store derivatives wrt Xi first, typeset in column-vector-compatible notation (COLUMN MAJOR) That makes the terms "row major" and "column major" singularly useless, in my opinion. They tell you nothing about the actual storage or typesetting order. Panda Notation Now that I've established my terminology, I can tell you what panda uses. If you examine the panda source code, in the method "LMatrix4f::xform," you will find the four transform equations. I have simplified them somewhat (ie, removed some of the C++ quirks) in order to put them here: define VECTOR4_MATRIX4_PRODUCT(output, input, M) \ output._0 = input._0*M._00 + input._1*M._10 + input._2*M._20 + input._3*M._30; \ output._1 = input._0*M._01 + input._1*M._11 + input._2*M._21 + input._3*M._31; \ output._2 = input._0*M._02 + input._1*M._12 + input._2*M._22 + input._3*M._32; \ output._3 = input._0*M._03 + input._1*M._13 + input._2*M._23 + input._3*M._33; Then, if you look in the corresponding header file for matrices, you will see the matrix class definition: struct { FLOATTYPE _00, _01, _02, _03; FLOATTYPE _10, _11, _12, _13; FLOATTYPE _20, _21, _22, _23; FLOATTYPE _30, _31, _32, _33; } m; So this class definition shows not only how the coefficients of the four equations are stored, but also the layout in which they were intended to be typeset. So from this, you can see that panda stores derivatives wrt Xi first, and it typesets in row-vector-compatible notation. Interoperability with OpenGL and DirectX Panda is code-compatible with both OpenGL and DirectX. All three use the same storage format: derivatives wrt Xi first. You can pass a panda matrix directly to OpenGL's "glLoadMatrixf" or DirectX's "SetTransform". However, remember that typesetting format and data storage format are independent choices. Even though two engines are interoperable at the code level (because their data storage formats match), their manuals might disagree with each other (because their typesetting formats do not match). The panda typesetting conventions and the OpenGL typesetting conventions are opposite from each other. The OpenGL manuals use a column-vector-compatible notation. The Panda manuals use a row-vector-compatible notation. I do not know what typesetting conventions the DirectX manual uses.
"Janek Kozicki"
Andy Little
Hello :)
<snip>
It would be nice if t1_quantity was renamed to some descriptive word. Perhaps a discussion on the mailing list would help to discover a better word.
Perhaps just quantity1, quantity2, quantity3 or quantitya, quantityb, quantityc.
OK, I'll give it a shot, because the point is not to move number (or letter) to the end of the name:
OK ... :-) Thanks for the suggestions that follow:
# t1_quantity where the dimension and unit are fixed [during compilation].
fixed_quantity // it's fixed, right?
Its dimension and unit are fixed, but its value isnt fixed, but the name is better than t1_quantity !
# t2_quantity where the dimension is fixed [during compilation] but the unit can be modified at runtime.
scalable_quantity // changing unit means, that the underlying numbers are scaled
OK.
# t3_quantity where the dimension and unit can be modified at runtime.
free_quantity // it's free, right?
I did think of uni_quantity or universal quantity Yes these names make more sense. FWIW I think there is another important variant. This is a quantity whose dimension can change , but whose unit is fixed. The purpose of this would be for run-time dimensional analysis of calculations with a guarantee of no scaling. . OTOH the 'free_quantity' could have a flag settable to restrict its operations so that scaling is banned. The free_quantity would be switched in for debugging and switched out for release as Leland Brown described earlier.
<snip>
I recommend to investigate tight integration with boost::numeric::ublas. I'm sure that people responsible for that library will gladly accept the idea, and accept any patches related to this. Basically this will make boost::ublas a ,,sort of'' part of pqs. Other solution would be to reimplement such huge matrices in pqs, but how far Andy could go?
I dont know if its possible. Another option is to cast the quantities to numerics. IOW exit the type checking. I will have to ask on the ublas list.
I must admit that I don't know where to start. Asking on ublas list is a very good idea. I remember that Noel Belcourt spent some time trying to adapt his Finite Element code to pqs - maybe he has some interesting suggestions about that.
Noel Belcourt is working on a Units library which is in the Boost Sandbox. I looked at it but didnt understand the approach. What you say may shed some light on the work. Anyway I will ask him. I have been thinking about this whole issue of dimensional analysis checking and how to apply it. I realise that my view has been very one-sided because I have worked only on the so-called fixed_quantity. Because of the 'compile time checks only' constraint, the so-called 'fixed_quantity' is very restricted in what areas it can be used. Though I have little experience of matrices beyond 3d transform matrices it seems that mathematicians will do calculations in matrices which causes the quantity type of the element to change at runtime which rules out the fixed_quantity. Feedback from you and others confirms the real benefits of being able to run dimensional analysis checks on your calculations, but to be able to take out the diagnostics tools so that they dont affect the release code, seems like another area that should be explored. (Again Leland Brown has implemented this AFAIK).
until I guessed that it's some kind of Cpp pseudocode. I could make it clear and maybe try to follow conventions too. Maybe I should make like GIL:
I'd prefer real C++, what others think?
I think it follows Concepts C++ language proposals. If so then one day that code might be real C++. See : http://www.generic-programming.org/languages/conceptcpp/
<snip>
OK, my favourite name is one letter longer, but still - "math" says a lot more than "three_d", so this name is more descriptive, IMHO.
Maybe even lose math:: ?
hmm.. I'm not sure. maybe better not. Having vector3d in the same directory/namespace as unit length makes me feel uneasy.
OK. how about a namespace called three_d then ;-) Seriously though I think vector3d and three_d::vector are functionally equivalent and, bearing in mind your dislike of sticking letters and numbers on type names, I can't see whats wrong with the latter. What are the arguments for the '3d' suffix on the name?
boost::units::math - is clear to understand - math classes with support for units. I don't mind writing one extra namespace name when it makes perfect sense. Paul said wisely: "write once, read many". Math constants will also reside there.
OK. This is a contentious issue with conflicting views from several people. Hopefully math constants will be a separate library so they arent any way dependent on anything in PQS library. OTOH physics constants are, because they must be compatible with quantities so there is a direct dependency on PQS. However, the way constants are done in PQS as member elements of a struct e.g boltzmannns_constant::K, means that any sub namespace is technically redundant for them. As for geometry a 'vector' in the root namespace cant work, so either suffixing the name or a sub-namespace must be used to distinguish 2D and 3D ( and nD ??) versions. A namespace is slightly more flexible in that you can make use of using directives and using declarations so only need to qualify when using (say) two_d::vector while the default vector is implied as three_d::vector. FWIW the worst part about the 3D namespace IMO is the actual name 'three_d'.
<snip>
rename rc_matrix into matrix, and never implement cr_matrix. There is an interesting reasoning about this problem inside panda3d software manual (given time I'll find it later).
Its certainly less work sticking to one type of matrix so I dont object to that. There may be performance resaons to choose on or other type?
I have found that excerpt in panda3d manual. But for whatever reasons in new release of manual they have removed this chapter. So I can't point some URL to it, instead I have added it as an attchment. (Note to readers: it is .html, you might want open it in your favourite browser).
There shouldn't be any performance differences. It's just that vectors will work with matrices (be internally compatibile). And that's all.
I'm all in favour of less work :-)
<snip>
without pqs: 3.8 seconds with pqs : 4.8 seconds
It is interesting to see the comparison. I spent some time trying to keep compile times down.
IMHO compilation time is not that important. We have distcc, and processors are getting faster and multicore. Design, (and runtime speed, which comes with good design) - that's what really matters.
Yes, I should work on this mechanism of using the checked quantities only for debugging, but leaving no artefacts of them(like reduced speed) for release. I should also work on closing the gap betwen fixed_quantity and floats too though. [...]
use a typedef defined so that quantities/ floating point types are swapped in to do dimensional analysis then swapped out in favour of floats in finished code. I have written some code this way.
that would be a nice option. At least to compare perfomance difference: speed with and without units.
All these usages are possible including the default style, the SI_units style preferred by Jesper Schmidt and the style described above...
I can't find his posts on the mailing list...
See the post entitled '[review] forwarded comments on pqs' from Thorten Ottosen. message id news.gmane.org gmane.comp.lib.boost.devel:143767 Unfortunately I cant seem to get a direct link.
<snip>
operator *= for vect was missing. I had to write { vect1 = vect1 * some_scalar;}; Also vect has a function magnitude(), please add squared_magnitude().
OK. vect is quite new and unfinished, needs a lot of work and tests of course.
I bet I can help a bit with that.
Great. I need to sit down and think about where PQS is going in tlight of all the review feedback. It depends majorly on the review result of course. If PQS is accepted then Boost CVS and Test can be utilised, else it should really go to another database somewhere. I dont have one except a local one. I guess the Boost Vault is better than nothing though. regards Andy Little
Andy Little said: (by the date of Sun, 11 Jun 2006 09:29:25 +0100)
fixed_quantity,scalable_quantity,free_quantity
I did think of uni_quantity or universal quantity Yes these names make more sense.
of coure those are just my suggestion, you may as well decide to name them differently. The goal it to GET RID of numbers in names ;) like this: rigid_quantity , scaled_quantity , uni_quantity fully_templated_quantity, partially_templated_quantity, runtime_quantity ;P whatever. but not numbers :)
Yes, I should work on this mechanism of using the checked quantities only for debugging, but leaving no artefacts of them(like reduced speed) for release. I should also work on closing the gap betwen fixed_quantity and floats too though.
I hope that it will work. Or better - that with fixed_quantity the templates will work so good, that there will be no difference between it turned on and off. -- Janek Kozicki |

Janek Kozicki wrote:
Andy Little said: (by the date of Sun, 11 Jun 2006 09:29:25 +0100)
fixed_quantity,scalable_quantity,free_quantity
I did think of uni_quantity or universal quantity Yes these names make more sense.
of coure those are just my suggestion, you may as well decide to name them differently. The goal it to GET RID of numbers in names ;)
like this:
rigid_quantity , scaled_quantity , uni_quantity fully_templated_quantity, partially_templated_quantity, runtime_quantity ;P
whatever. but not numbers :)
No, not "whatever". It wasn't the use of numbers, per se, that everybody objected to. It's the desire to see meaningful names that communicate more clearly what the point of these things are.
Deane Yang said: (by the date of Mon, 12 Jun 2006 16:11:40 -0400)
like this:
rigid_quantity , scaled_quantity , uni_quantity fully_templated_quantity, partially_templated_quantity, runtime_quantity ;P
whatever. but not numbers :)
No, not "whatever". It wasn't the use of numbers, per se, that everybody objected to. It's the desire to see meaningful names that communicate more clearly what the point of these things are.
bingo! When I was writing above I intended to play with the imagination of the reader. To stimulate it ;) it's my hope that Andy will not trade numbers for nothing. But instead he will take something far better than numbers. -- Janek Kozicki |
"Janek Kozicki" wrote
Andy Little said: (by the date of Sun, 11 Jun 2006 09:29:25 +0100)
fixed_quantity,scalable_quantity,free_quantity
I did think of uni_quantity or universal quantity Yes these names make more sense.
of coure those are just my suggestion, you may as well decide to name them differently. The goal it to GET RID of numbers in names ;)
apart from in vectors ? :-)
like this:
rigid_quantity , scaled_quantity , uni_quantity fully_templated_quantity, partially_templated_quantity, runtime_quantity ;P
whatever. but not numbers :)
What about in vector, say vector3d ? :-)
Yes, I should work on this mechanism of using the checked quantities only for debugging, but leaving no artefacts of them(like reduced speed) for release. I should also work on closing the gap betwen fixed_quantity and floats too though.
I hope that it will work. Or better - that with fixed_quantity the templates will work so good, that there will be no difference between it turned on and off.
It worked very well in VC7.1, in a previous version of the library, when the assembly produced was identical to that for float types( but only for 2 small simple tests and I didnt try further): http://www.servocomm.freeserve.co.uk/Cpp/physical_quantity/perf_test.html VC7.1 has a very good optimiser and maybe that version of pqs was easier to optimise than the current one. If that turns out to be the case I may have to return to that design of implementation. In fact maybe I should try more complicated tests on that implementation to see what happens and in gcc. However I havent spent any time on that side of things with this version. I have done a very different implementation, this time using a UDT member rather than a float ( to separate the dimension from the units), which may be more difficult to optimize, and I don't know anything about the optimiser in gcc. Currently I have been more concerned with the interface than optimising the implementation. Unfortunately in pqs_3_1_x the implementation is a mess. It needs stripping out and redoing. regards Andy Little
Andy Little said: (by the date of Tue, 13 Jun 2006 00:43:30 +0100)
rigid_quantity , scaled_quantity , uni_quantity fully_templated_quantity, partially_templated_quantity, runtime_quantity ;P
whatever. but not numbers :)
What about in vector, say vector3d ? :-)
where numbers DO make some sense, in t1_quantity or in vector3d ? ;) -- Janek Kozicki |
"Janek Kozicki" wrote
Andy Little said: (by the date of Sun, 11 Jun 2006 09:29:25 +0100)
fixed_quantity,scalable_quantity,free_quantity
I did think of uni_quantity or universal quantity Yes these names make more sense.
of coure those are just my suggestion, you may as well decide to name them differently. The goal it to GET RID of numbers in names ;)
I forgot to say... thanks for the naming suggestions for the different quantity types.. They are much better than differentiating with numbers. I may use those very names. regards Andy Little

On Sat, Jun 10, 2006 at 05:58:35PM +0100, Andy Little wrote:
I don't like the separation of "three_d" and "two_d" - where quaternions should be put then - "four_d" ?
My rationale is that quaternions exist in a 3D space. OTOH complex would be in two_d because it exists in a 2D space.
quaternions are 4D (1, i, j, k), where complex is 2D (1, i). -- Carlo Wood <carlo@alinoe.com>
"Carlo Wood" <carlo@alinoe.com> wrote in message news:20060610213957.GA28109@alinoe.com...
On Sat, Jun 10, 2006 at 05:58:35PM +0100, Andy Little wrote:
I don't like the separation of "three_d" and "two_d" - where quaternions should be put then - "four_d" ?
My rationale is that quaternions exist in a 3D space. OTOH complex would be in two_d because it exists in a 2D space.
quaternions are 4D (1, i, j, k), where complex is 2D (1, i).
OK, but they are define a rotation in 3D space, do they not ? regards Andy Little
"me22" wrote
On 6/10/06, Andy Little <andy@servocomm.freeserve.co.uk> wrote:
OK, but they are define a rotation in 3D space, do they not ?
My understanding is that a *unit* quaternion can be used to represent a rotation in 3-space, but an arbitrary quaternion is 4D.
OK. So going back to the original point. The intent in PQS is to use a quaternion solely for representing a rotation in 3D space. Putting quaternion in a 3D namespace makes sense to me from that viewpoint and should help to clarify its intended purpose. regards Andy Little
On 6/11/06, Andy Little <andy@servocomm.freeserve.co.uk> wrote:
OK. So going back to the original point. The intent in PQS is to use a quaternion solely for representing a rotation in 3D space. Putting quaternion in a 3D namespace makes sense to me from that viewpoint and should help to clarify its intended purpose.
In that case I think it should be called unit_quaternion to emphasise the point. It would also make it clear that the implementation is ensuring and assuming that w*w+x*x+y*y+z*z is very close to 1. Regards, Scott McMurray
"me22" <me22.ca@gmail.com> wrote in message news:fa28b9250606111226m1809c81ai14d096e010e718f1@mail.gmail.com...
On 6/11/06, Andy Little <andy@servocomm.freeserve.co.uk> wrote:
OK. So going back to the original point. The intent in PQS is to use a quaternion solely for representing a rotation in 3D space. Putting quaternion in a 3D namespace makes sense to me from that viewpoint and should help to clarify its intended purpose.
In that case I think it should be called unit_quaternion to emphasise the point. It would also make it clear that the implementation is ensuring and assuming that w*w+x*x+y*y+z*z is very close to 1.
OK. This functionality will surely depend on the implementation of vect * quat ? In boost::quaternion the quaternion seems to be normalised during the calculation AFAICS. See <libs/math/quaternion/HS03.hpp>. I have to confess that I don't know enough about quaternions to speak with authority. As Janek Kozicki brought up yade http://yade.berlios.de/. My current plan is to look at that as an example useage. Again only for rotations. I'm not even sure yet how I can test the calculations on quaternions. I need to understand more about how they are constructed, starting maybe from an [axis-vector,angle] type maybe, simply because I can visualise that easier than 4 dimensions :-) regards Andy Little

OK. This functionality will surely depend on the implementation of vect * quat ? In boost::quaternion the quaternion seems to be normalised during the calculation AFAICS. See <libs/math/quaternion/HS03.hpp>. I have to confess that I don't know enough about quaternions to speak with authority. As Janek Kozicki brought up yade http://yade.berlios.de/. My current plan is to look at that as an example useage. Again only for rotations. I'm not even sure yet how I can test the calculations on quaternions. I need to understand more about how they are constructed, starting maybe from an [axis-vector,angle] type maybe, simply because I can visualise that easier than 4 dimensions :-)
An extremely good book on quaternions if you can get it is Quaternions and Rotation Sequences Jack B. Kuipers ISBN 0-691-05872-5 Very recommended and written in one the best styles I've seen for a technical book. hth Martin -- No virus found in this outgoing message. Checked by AVG Free Edition. Version: 7.1.394 / Virus Database: 268.8.3/362 - Release Date: 12/06/2006

Andy Little wrote:
"me22" <me22.ca@gmail.com> wrote in message news:fa28b9250606111226m1809c81ai14d096e010e718f1@mail.gmail.com...
On 6/11/06, Andy Little <andy@servocomm.freeserve.co.uk> wrote:
OK. So going back to the original point. The intent in PQS is to use a quaternion solely for representing a rotation in 3D space. Putting quaternion in a 3D namespace makes sense to me from that viewpoint and should help to clarify its intended purpose.
In that case I think it should be called unit_quaternion to emphasise the point. It would also make it clear that the implementation is ensuring and assuming that w*w+x*x+y*y+z*z is very close to 1.
OK. This functionality will surely depend on the implementation of vect * quat ? In boost::quaternion the quaternion seems to be normalised during the calculation AFAICS. See <libs/math/quaternion/HS03.hpp>. I have to confess that I don't know enough about quaternions to speak with authority. As Janek Kozicki brought up yade http://yade.berlios.de/. My current plan is to look at that as an example useage. Again only for rotations. I'm not even sure yet how I can test the calculations on quaternions. I need to understand more about how they are constructed, starting maybe from an [axis-vector,angle] type maybe, simply because I can visualise that easier than 4 dimensions :-)
IIRC, you can interpret the first 3 elements as an axis of rotation, and the last element is the amount of rotation about this vector. Jeff Flinn
Janek Kozicki said: (by the date of Sat, 10 Jun 2006 02:17:33 +0200)
without pqs (three runs): Computation time: 370.939 seconds Computation time: 382.615 seconds Computation time: 360.418 seconds
with pqs - and extra constructor calls, which would be avoided if I converted whole data structure! (three runs): Computation time: 415.724 seconds Computation time: 423.181 seconds Computation time: 421.799 seconds
that makes a difference of roughly 11% - 13%
oops. I did not pay attention to optimization level when compiling yade. I have redone checks with maximum optimization (-O3). Six runs with and six without pqs. Averaged result is now just 2% performance drop. I'm really sorry for that misinformation. -- Janek Kozicki |
participants (8)
-
 Andy Little
Andy Little -
 Carlo Wood
Carlo Wood -
 Deane Yang
Deane Yang -
 fred bertsch
fred bertsch -
 Janek Kozicki
Janek Kozicki -
 Jeff Flinn
Jeff Flinn -
 Martin Slater
Martin Slater -
 me22
me22