[MultiIndex] Random Access mental model?

Hi, I'm trying to get a grip on what it means when I have a random access index in a multi_index_container. I have no mental model for what data structure you're actually creating, which makes it difficult to evaluate multi-index vs. hand-rolling my own container. If I was doing this myself, I'd use a combination of these two: hash_map<key, value> deque<hash_map<key, value>::pointer> because I need to maintain an LRU cache of what has been put in the map (i.e. I need O(1) push_back and pop_front). MultiIndex only lets me use sequenced<> which it implies essentially has the properties of list<hash_map<key, value>::iterator>... although I can imagine you could save a lot by using the same nodes for the hash_map and the list. Do you do that? Regardless, I could still save roughly one pointer per node with my deque. I'd think about trying to modify MultiIndex to let it do random access with deques, but I can't make head or tail of the implementation code used for random access. Could someone clarify what's going on in there? -- Dave Abrahams BoostPro Computing http://www.boostpro.com

David Abrahams <dave <at> boostpro.com> writes:
Hi,
Hi Dave, allow me to address this post of yours first and defer the answer to the others you've send on Boost.MultiIndex, as those will need more elaboration.
I'm trying to get a grip on what it means when I have a random access index in a multi_index_container. I have no mental model for what data structure you're actually creating, which makes it difficult to evaluate multi-index vs. hand-rolling my own container.
If I was doing this myself, I'd use a combination of these two:
hash_map<key, value> deque<hash_map<key, value>::pointer>
because I need to maintain an LRU cache of what has been put in the map (i.e. I need O(1) push_back and pop_front). MultiIndex only lets me use sequenced<> which it implies essentially has the properties of list<hash_map<key, value>::iterator>... although I can imagine you could save a lot by using the same nodes for the hash_map and the list. Do you do that?
Yep, this is done. Only one node per element is allocated. This is true regardless of the indices used, including random access indices. If you want to visualize this, each element node has as many node headers as indices are, each one stacked on top of the next. Some indices (namely, hashed and random access) use additional data structures external to the nodes themselves (this is obvious in the case of hashed indices, as they are entirely similar to unordered_set).
Regardless, I could still save roughly one pointer per node with my deque. I'd think about trying to modify MultiIndex to let it do random access with deques, but I can't make head or tail of the implementation code used for random access.
The data structure of a random access index is basically the same as depicted for a little container I call stable_vector: http://bannalia.blogspot.com/2008/08/stable-vectors.html So, each element is stored in its own node (as is been already said) and there is an additionally internal vector of pointers that keeps the elements together while providing O(1) access. The up-pointers described in the aforementioned article are necessary to provide stable iterators. The overhead of a random access index is one pointer per node (the up-pointer) plus the size of the internal pointer vector. Some figures are calculated at: http://bannalia.blogspot.com/2008/09/introducing-stablevector.html The deque-based structure you propose would save, as you say, roughly one pointer per node with respect to sequenced indices and also with respect to random access indices, which have the up-pointer your proposed data structure lacks, while on the other hand it requires an extra pointer as the deque stores pointers while multi_index_containers enjoy the header stacking property referred to above. So, roughly speaking, things are even. On the other hand, this up-pointer is essential to ensure iterator stability and iterator projection, which are features that currently the lib take for granted for all the different index types available.
Could someone clarify what's going on in there?
Hope the answer helped clarify the issue. Please come back otherwise. Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
on Fri Oct 31 2008, Joaquin M Lopez Munoz <joaquin-AT-tid.es> wrote:
David Abrahams <dave <at> boostpro.com> writes:
Hi,
Hi Dave, allow me to address this post of yours first and defer the answer to the others you've send on Boost.MultiIndex, as those will need more elaboration.
Thanks. This is the most important one.
I'm trying to get a grip on what it means when I have a random access index in a multi_index_container. I have no mental model for what data structure you're actually creating, which makes it difficult to evaluate multi-index vs. hand-rolling my own container.
If I was doing this myself, I'd use a combination of these two:
hash_map<key, value> deque<hash_map<key, value>::pointer>
because I need to maintain an LRU cache of what has been put in the map (i.e. I need O(1) push_back and pop_front). MultiIndex only lets me use sequenced<> which it implies essentially has the properties of list<hash_map<key, value>::iterator>... although I can imagine you could save a lot by using the same nodes for the hash_map and the list. Do you do that?
Yep, this is done. Only one node per element is allocated. This is true regardless of the indices used, including random access indices. If you want to visualize this, each element node has as many node headers as indices are, each one stacked on top of the next.
I think random access shouldn't need to add a node header unless you want to do something like look up a key in the hash index and delete that element. Maybe a feature-model interface would be a more powerful way to approach this space, so we don't have to pay for what we don't use.
Some indices (namely, hashed and random access) use additional data structures external to the nodes themselves (this is obvious in the case of hashed indices, as they are entirely similar to unordered_set).
Yes, and I expect random access indices to do the same.
Regardless, I could still save roughly one pointer per node with my deque. I'd think about trying to modify MultiIndex to let it do random access with deques, but I can't make head or tail of the implementation code used for random access.
The data structure of a random access index is basically the same as depicted for a little container I call stable_vector:
That's what I figured... although the back-pointers are only needed if you need to delete and you can't get ahold of an iterator into the vector -- the same case I mentioned above.
So, each element is stored in its own node (as is been already said) and there is an additionally internal vector of pointers that keeps the elements together while providing O(1) access. The up-pointers described in the aforementioned article are necessary to provide stable iterators.
The overhead of a random access index is one pointer per node (the up-pointer) plus the size of the internal pointer vector. Some figures are calculated at:
http://bannalia.blogspot.com/2008/09/introducing-stablevector.html
The deque-based structure you propose would save, as you say, roughly one pointer per node with respect to sequenced indices and also with respect to random access indices, which have the up-pointer your proposed data structure lacks, while on the other hand it requires an extra pointer as the deque stores pointers while multi_index_containers enjoy the header stacking property referred to above.
So, roughly speaking, things are even.
Sorry, I don't see it. Since I need O(1) pop-front I am using sequenced<> which IIUC is a doubly-linked list. Therefore your nodes have this overhead: next-in-list, prev-in-list, and next-in-hash-bucket = 3 pointers and mine have only next-in-hash-bucket. Add one pointer of overhead in the deque and I am storing 2 pointers.
On the other hand, this up-pointer is essential to ensure iterator stability and iterator projection, which are features that currently the lib take for granted for all the different index types available.
In my application, the ability to erase nodes through hash iterators doesn't matter, but the per-node storage cost does.
Could someone clarify what's going on in there?
Hope the answer helped clarify the issue. Please come back otherwise.
Except for the fact that we are coming up with different numbers for the data structure overhead, yeah. Thanks, -- Dave Abrahams BoostPro Computing http://www.boostpro.com
on Fri Oct 31 2008, David Abrahams <dave-AT-boostpro.com> wrote:
Sorry, I don't see it. Since I need O(1) pop-front I am using sequenced<> which IIUC is a doubly-linked list. Therefore your nodes have this overhead:
next-in-list, prev-in-list, and next-in-hash-bucket = 3 pointers
and mine have only next-in-hash-bucket. Add one pointer of overhead in the deque and I am storing 2 pointers.
Actually, MultiIndex could give me *almost* everything I need by threading a singly-linked list through the hash nodes (instead of doubly-linked). That's enough for a FIFO queue. Turns out I need a little more than that; I essentially need a bool that tells me whether the node is in the FIFO queue yet. Since I can use a NULL queue pointer for that purpose, it looks like I'll be rolling my own. -- Dave Abrahams BoostPro Computing http://www.boostpro.com
________________________________________ De: boost-bounces@lists.boost.org [boost-bounces@lists.boost.org] En nombre de David Abrahams [dave@boostpro.com] Enviado el: sábado, 01 de noviembre de 2008 14:08 Para: boost@lists.boost.org Asunto: Re: [boost] [MultiIndex] Random Access mental model? on Fri Oct 31 2008, David Abrahams <dave-AT-boostpro.com> wrote:
Actually, MultiIndex could give me *almost* everything I need by threading a singly-linked list through the hash nodes (instead of doubly-linked). That's enough for a FIFO queue.
You can do that with Boost.Intrusive, and that will indeed save you one pointer per node as compared with the Boost.MultiIndex-based solution. If you're resorting to manually combining a hash_map and a slist<pointer> then you'd begaining nothing, as in the hash_map+ deque<pointer> case described in my previous post.
Turns out I need a little more than that; I essentially need a bool that tells me whether the node is in the FIFO queue yet. Since I can use a NULL queue pointer for that purpose, it looks like I'll be rolling my own.
Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
on Sat Nov 01 2008, JOAQUIN M. LOPEZ MUÑOZ <joaquin-AT-tid.es> wrote:
on Fri Oct 31 2008, David Abrahams <dave-AT-boostpro.com> wrote:
Actually, MultiIndex could give me *almost* everything I need by threading a singly-linked list through the hash nodes (instead of doubly-linked). That's enough for a FIFO queue.
You can do that with Boost.Intrusive, and that will indeed save you one pointer per node as compared with the Boost.MultiIndex-based solution. If you're resorting to manually combining a hash_map and a slist<pointer> then you'd begaining nothing, as in the hash_map+ deque<pointer> case described in my previous post.
No, the deque saves a lot of memory. The slist would indeed gain nothing as you do indeed need an additional "next" pointer per element for an slist. But as I wrote earlier, I need something else. -- Dave Abrahams BoostPro Computing http://www.boostpro.com
on Sat Nov 01 2008, JOAQUIN M. LOPEZ MUÑOZ <joaquin-AT-tid.es> wrote:
Actually, MultiIndex could give me *almost* everything I need by threading a singly-linked list through the hash nodes (instead of doubly-linked). That's enough for a FIFO queue.
You can do that with Boost.Intrusive, and that will indeed save you one pointer per node as compared with the Boost.MultiIndex-based solution. If you're resorting to manually combining a hash_map and a slist<pointer> then you'd begaining nothing, as in the hash_map+ deque<pointer> case described in my previous post.
Turns out I need a little more than that; I essentially need a bool that tells me whether the node is in the FIFO queue yet. Since I can use a NULL queue pointer for that purpose, it looks like I'll be rolling my own.
I handn't looked at Boost.Intrusive before. While it looks interesting, it seems pretty complicated and I can't quite see any point in using it when I could just use Boost.Unordered with a value_type that holds an additional pointer. Maybe I'm missing something; I don't know. -- Dave Abrahams BoostPro Computing http://www.boostpro.com
David Abrahams <dave <at> boostpro.com> writes:
on Sat Nov 01 2008, JOAQUIN M. LOPEZ MUÑOZ <joaquin-AT-tid.es> wrote:
Actually, MultiIndex could give me *almost* everything I need by threading a singly-linked list through the hash nodes (instead of doubly-linked). That's enough for a FIFO queue.
You can do that with Boost.Intrusive, and that will indeed save you one pointer per node as compared with the Boost.MultiIndex-based solution. If you're resorting to manually combining a hash_map and a slist<pointer> then you'd begaining nothing, as in the hash_map+ deque<pointer> case described in my previous post.
[...]
I handn't looked at Boost.Intrusive before. While it looks interesting, it seems pretty complicated and I can't quite see any point in using it when I could just use Boost.Unordered with a value_type that holds an additional pointer. Maybe I'm missing something; I don't know.
Of course anything you can do with Boost.Intrusive (or any other lib) you can do without. For such a simple thing as a forward_list you might not want to incur the cost of learning a new library. In my opinion, however, Boost.Intrusive really pays off. Joaquín M López Muñoz Telefónica, Investigación y Desarrollo

David Abrahams wrote:
on Sat Nov 01 2008, JOAQUIN M. LOPEZ MUÑOZ <joaquin-AT-tid.es> wrote:
Actually, MultiIndex could give me *almost* everything I need by threading a singly-linked list through the hash nodes (instead of doubly-linked). That's enough for a FIFO queue. You can do that with Boost.Intrusive, and that will indeed save you one pointer per node as compared with the Boost.MultiIndex-based solution. If you're resorting to manually combining a hash_map and a slist<pointer> then you'd begaining nothing, as in the hash_map+ deque<pointer> case described in my previous post.
Turns out I need a little more than that; I essentially need a bool that tells me whether the node is in the FIFO queue yet. Since I can use a NULL queue pointer for that purpose, it looks like I'll be rolling my own.
I handn't looked at Boost.Intrusive before. While it looks interesting, it seems pretty complicated and I can't quite see any point in using it when I could just use Boost.Unordered with a value_type that holds an additional pointer. Maybe I'm missing something; I don't know.
The point of using Intrusive is that you only allocate once instead of one for every container. When we use two STL-like containers we are allocating dynamic memory so we have a size payload for each allocation from the memory allocator (usually 1 or 2 pointers). I haven't followed the thread but in your first post you say you need an unordered map and a list of values to obtain fast access to the first element. Intrusive is a bit low-level, because you need to allocate values yourself and then insert them in intrusive containers (and there are no maps only sets) but this offers some advantages as can allocate several values (burst allocation) in a vector to minimize any memory payload and speed up the insertion. With Intrusive a combination of a hash multiset and a singly linked list might seem like this: #include <vector> #include <boost/intrusive/unordered_set.hpp> #include <boost/intrusive/slist.hpp> #include <boost/functional/hash.hpp> using namespace boost::intrusive; template<class Key, class Value> class MyClass : public unordered_set_base_hook<> , public slist_base_hook<> { public: typedef Key key_type; typedef Value value_type; Key key_; Value value_; MyClass() : key_(), value_() {} MyClass(const Key &k, const Value &v) : key_(k), value_(v) {} friend bool operator== (const MyClass &a, const MyClass &b) { return a.key_ == b.key_; } friend std::size_t hash_value(const MyClass &value) { using boost::hash_value; return hash_value(value.key_); } }; //Comparison functor to search a value from a key template<class MyClass> struct key_value_compare { typedef typename MyClass::key_type key_type; bool operator()(const key_type &k, const MyClass &v) const { return k == v.key_; } bool operator()(const MyClass &v, const key_type &k) const { return v.key_ == k; } }; //Hash functor to search a value from a key template<class Key> struct key_hasher { std::size_t operator()(const Key &k) const { using boost::hash_value; return hash_value(k); } }; // typedef MyClass<int, std::string> value_type; typedef key_value_compare<value_type> key_value_comp; typedef key_hasher<int> key_hash; //Define an unordered_set that will link value_types typedef unordered_multiset<value_type> Umset; //Define a singly linked list the will link value_types typedef slist<value_type> Slist; int main() { //Create a vector with 100 different value_type objects std::vector<value_type> values(100); for(int i = 0; i < 100; ++i) values[i].key_ = i; //Intrusive containers don't allocate so //bucket array must be provided externally Umset::bucket_type buckets[100]; //Link values in an unordered set and a slist Umset uset(Umset::bucket_traits(buckets, 100)); Slist lru_list; //Insert values in both containers for(int i = 0; i < 100; ++i){ uset.insert(values[i]); lru_list.push_front(values[i]); } //Search an element using a whole value_type for(int i = 0; i < 100; ++i){ value_type search_this(i, ""); if(uset.end() == uset.find(search_this)) return 1; } //Search an element using a custom predicate instead of //building a whole value_type for(int i = 0; i < 100; ++i){ if(uset.end() == uset.find(i, key_hash(), key_value_comp())) return 1; } //Obtain most recent value... value_type &v = lru_list.front(); //Erase value from lru lru_list.pop_front(); //Erase it from the map from an iterator //obtained from the value uset.erase(uset.iterator_to(v)); return 0; }
on Sat Nov 01 2008, Ion Gaztañaga <igaztanaga-AT-gmail.com> wrote:
David Abrahams wrote:
on Sat Nov 01 2008, JOAQUIN M. LOPEZ MUÑOZ <joaquin-AT-tid.es> wrote:
Actually, MultiIndex could give me *almost* everything I need by threading a singly-linked list through the hash nodes (instead of doubly-linked). That's enough for a FIFO queue. You can do that with Boost.Intrusive, and that will indeed save you one pointer per node as compared with the Boost.MultiIndex-based solution. If you're resorting to manually combining a hash_map and a slist<pointer> then you'd begaining nothing, as in the hash_map+ deque<pointer> case described in my previous post.
Turns out I need a little more than that; I essentially need a bool that tells me whether the node is in the FIFO queue yet. Since I can use a NULL queue pointer for that purpose, it looks like I'll be rolling my own.
I handn't looked at Boost.Intrusive before. While it looks interesting, it seems pretty complicated and I can't quite see any point in using it when I could just use Boost.Unordered with a value_type that holds an additional pointer. Maybe I'm missing something; I don't know.
The point of using Intrusive is that you only allocate once instead of one for every container.
I know. I think you must misunderstand me. When I wrote of using "a value_type that holds an additional pointer" I meant that I would build the FIFO queue using the hash nodes, roughly: // Totally untested!! // My values happen to be default constructible; if they // weren't and Boost.Intrusive could help, I might take // advantage of it. Otherwise, I know how to take care of // it myself but I am trying to keep this posting simple. template <class Key, class Value> struct fifo_value { fifo_value() : next(0) {} fifo_value(Value v, Key* next = 0) : value(v), next(next) {} Value value; Key* next; }; template <class Key, class Value> struct fifo_hashmap { fifo_hashmap() : head(&last), tail(&head) {} // Insert the key with no value void insert_key(Key k) { map[k]; } // Has the value been pushed onto the FIFO? bool has_value(Key k) const { typename map_type::iterator pos = map.find(k); return pos != map.end() && pos->second.next; } // Has the key been inserted in the map? bool mapped(Key k) const { return map.find(k) != map.end(); } // push a value for the given key onto the FIFO void push(Key const& k, Value const& v) { typename map_type::iterator pos = map.insert(k, fifo_value(v, &last)); *tail = &pos->first; tail = &pos->second.next; } // Pop the first value off of the FIFO void pop() { Key* h = head; typename map_type::iterator pos = map.find(*h); head = pos->second.next; map.erase(pos); } private: typedef unordered_map<key, fifo_value<key, value> > map_type; map_type map; Key* head; Key** tail; static Key last; }; That implements pretty much all the operations I need.
When we use two STL-like containers we are allocating dynamic memory so we have a size payload for each allocation from the memory allocator (usually 1 or 2 pointers).
I know. -- Dave Abrahams BoostPro Computing http://www.boostpro.com
David Abrahams wrote:
I know. I think you must misunderstand me. When I wrote of using "a value_type that holds an additional pointer" I meant that I would build the FIFO queue using the hash nodes, roughly:
Ok, thanks for the example. The only advantages I see to implement this class with Boost.Intrusive is that pop() could be faster (and no-throw): void pop() { value_type & v = fifo->front(); fifo.pop_front(); //Nothrow map.erase(map.iterator_to(v)); } and that you avoid copies (what happens if the key is already in the map in your example?):
// push a value for the given key onto the FIFO void push(Key const& k, Value const& v) { typename map_type::iterator pos = map.insert(k, fifo_value(v, &last));
*tail = &pos->first; tail = &pos->second.next; }
Supposing you want to avoid duplicate values then // push a value for the given key onto the FIFO void push(Key const& k, Value const& v) { typename map_type::insert_commit_data data; //Test if the key is there without constructing //the value if(!map.insert_check(key, key_hasher() , key_mapped_compare(), data).second){ //Already present, return return; } //Success guaranteed, now commit mapped_type *m= new mapped_type(k, v); //Nothrow map.insert_commit(*m, data); //If slist is implemented with cachelast<true> option //you have O(1) push_back() fifo->push_back(*m); } If you allow duplicates then I suppose you meant unordered_multimap instead of unordered_map, so just forget insert_check/insert_commit and do direct insertion: mapped_type *m= new mapped_type(k, v); map.insert(*m, data); fifo->push_back(*m); The drawback is that you need to define a "mapped_type" that stores Value and Key and do the memory management. Please let me know if the example was helpful or I'm wrong (again). Regards, Ion
on Sat Nov 01 2008, Ion Gaztañaga <igaztanaga-AT-gmail.com> wrote:
David Abrahams wrote:
I know. I think you must misunderstand me. When I wrote of using "a value_type that holds an additional pointer" I meant that I would build the FIFO queue using the hash nodes, roughly:
Ok, thanks for the example. The only advantages I see to implement this class with Boost.Intrusive is that pop() could be faster (and no-throw):
void pop() { value_type & v = fifo->front(); fifo.pop_front(); //Nothrow map.erase(map.iterator_to(v)); }
Mine is already nothrow unless you have a throwing hash or equality comparison, but yes, it's always better if you can map from addresses to iterators.
and that you avoid copies (what happens if the key is already in the map in your example?):
// push a value for the given key onto the FIFO void push(Key const& k, Value const& v) { typename map_type::iterator pos = map.insert(k, fifo_value(v, &last));
*tail = &pos->first; tail = &pos->second.next; }
C'mon, it was just an untested sketch. Obviously I can handle that case.
Supposing you want to avoid duplicate values then
I have no need for duplicate values but I don't especially need the map to do anything to avoid them.
// push a value for the given key onto the FIFO void push(Key const& k, Value const& v) { typename map_type::insert_commit_data data; //Test if the key is there without constructing //the value if(!map.insert_check(key, key_hasher() , key_mapped_compare(), data).second){ //Already present, return return; } //Success guaranteed, now commit mapped_type *m= new mapped_type(k, v); //Nothrow map.insert_commit(*m, data); //If slist is implemented with cachelast<true> option //you have O(1) push_back() fifo->push_back(*m); }
Is that Boost.Intrusive code or...?
Please let me know if the example was helpful or I'm wrong
It could be helpful if it is pointing the way to do this most efficiently with Boost.Intrusive. There's not quite enough detail there for me to tell yet, but at least now I'm motivated to look into it further. Wow, that's a cool library! I didn't know it had avl trees, splay trees, scapegoat trees, ... etc. Cheers, -- Dave Abrahams BoostPro Computing http://www.boostpro.com
David Abrahams wrote:
on Sat Nov 01 2008, Ion Gaztañaga <igaztanaga-AT-gmail.com> wrote:
and that you avoid copies (what happens if the key is already in the map in your example?):
C'mon, it was just an untested sketch. Obviously I can handle that case.
I know ;-), it was just to show if you could benefit from insert_check/insert_commit trick and avoid building a full value in that case.
// push a value for the given key onto the FIFO void push(Key const& k, Value const& v) { typename map_type::insert_commit_data data; //Test if the key is there without constructing //the value if(!map.insert_check(key, key_hasher() , key_mapped_compare(), data).second){ //Already present, return return; } //Success guaranteed, now commit mapped_type *m= new mapped_type(k, v); //Nothrow map.insert_commit(*m, data); //If slist is implemented with cachelast<true> option //you have O(1) push_back() fifo->push_back(*m); }
Is that Boost.Intrusive code or...?
I'm on a trip, so I won't be able to follow the thread in the Newsgroup. Please write me directly if you want more explanations. Here is a full example compiled with Visual 7.1: #include <boost/intrusive/set.hpp> #include <boost/intrusive/slist.hpp> #include <string> using namespace boost::intrusive; template <class Value> struct fifo_value : public slist_base_hook<> { fifo_value() : next(0) {} fifo_value(Value v) : value(v) {} Value value; }; template <class Key, class Value> struct fifo_mapped_value : public set_base_hook<> { typedef fifo_value<Value> value_type; Key key_; value_type fifo_value_; fifo_mapped_value(const Key &k, const Value &v) : key_(k), fifo_value_(v) {} template<class ConvertibleKey, class ConvertibleValue> fifo_mapped_value( const ConvertibleKey &k , const ConvertibleValue &v) : key_(k), fifo_value_(v) {} friend bool operator<( const fifo_mapped_value &l , const fifo_mapped_value &r) { return l.key_ < r.key_; } }; template <class Key, class Value> class fifo_map { typedef fifo_mapped_value<Key, Value> mapped_type; typedef multiset<mapped_type > map_type; typedef fifo_value<Value> value_type; typedef slist< value_type , cache_last<true> > fifo_type; fifo_map(const fifo_map &); fifo_map & operator=(const fifo_map &); public: fifo_map() {} struct deleter { void operator()(mapped_type *m) const { delete m; } }; struct key_mapped_compare { bool operator()(const Key &k, const mapped_type &v) const { return k < v.key_; } bool operator()(const mapped_type &v, const Key &k) const { return v.key_ < k; } }; ~fifo_map() { //Unlink all elements fifo.clear(); //Unlink and destroy map.clear_and_dispose(deleter()); } // Has the value been pushed onto the FIFO? bool has_value(const Key &k) const { typename map_type::const_iterator pos = map.find(k, key_mapped_compare()); return pos != map.cend(); } // Has the key been inserted in the map? bool mapped(Key k) const { return map.find(k) != map.end(); } // push a value for the given key onto the FIFO template<class ConvertibleKey, class ConvertibleValue> void push(ConvertibleKey const& k, ConvertibleValue const& v) { mapped_type *m= new mapped_type(k, v); map.insert(*m); fifo.push_back(m->fifo_value_); } // Pop the first value off of the FIFO void pop() { value_type &v = fifo.front(); value_type mapped_type::*ptr_to_mem = &mapped_type::fifo_value_; //Yes, this in detail namespace, but I plan to make it public //and I don't have time to think something to avoid this ;-) mapped_type &m = *detail::parent_from_member <mapped_type, value_type>(&v, ptr_to_mem); fifo.pop_front(); map.erase(map.iterator_to(m)); delete &m; } private: map_type map; fifo_type fifo; }; int main() { fifo_map<int, std::string> f_map; f_map.push(0, "asdf"); if(!f_map.has_value(0)) return 1; f_map.pop(); if(f_map.has_value(0)) return 1; return 0; }
Wow, that's a cool library! I didn't know it had avl trees, splay trees, scapegoat trees, ... etc.
Planning treaps for Boost 1.38 ;-)
Cheers,
Regards, Ion
David Abrahams <dave <at> boostpro.com> writes:
I know. I think you must misunderstand me. When I wrote of using "a value_type that holds an additional pointer" I meant that I would build the FIFO queue using the hash nodes, roughly:
[...] Not that this has to do with the multi-indexing capabilities of Boost.MultiIndex, but I think you can still take (a little) advantange of the lib by using a multi_index_container<hashed_unique> instead of a unordered_map, because the former has an iterator_to() member function that allows you to retrieve an iterator from a value_type*, so saving you the jump from Key* to an iterator via map.find() that your code has at pop(). Untested code based on yours follows: template <class Key, class Value> struct fifo_value { fifo_value() : next(0) {} fifo_value(Key k, Value v = Value(), fifo_value* next = 0) : key(k), value(v), next(next) {} Key key; mutable Value value; mutable const fifo_value* next; }; template <class Key, class Value> struct fifo_hashmap { fifo_hashmap() : head(&last), tail(&head) {} // Insert the key with no value void insert_key(Key k) { map.insert(value_type(k)); } // Has the value been pushed onto the FIFO? bool has_value(Key k) const { typename map_type::iterator pos = map.find(k); return pos != map.end() && pos->next; } // Has the key been inserted in the map? bool mapped(Key k) const { return map.find(k) != map.end(); } // push a value for the given key onto the FIFO void push(Key const& k, Value const& v) { std::pair<typename map_type::iterator,bool> p = map.insert(value_type(k, v, &last)); if(!p.second)p.first->value=v; *tail = &*p.first; tail = &p.first->next; } // Pop the first value off of the FIFO void pop() { // Here I don't need to do map.find(...) const value_type* h = head; typename map_type::iterator pos = map.iterator_to(*h); head = pos->next; map.erase(pos); } private: typedef fifo_value<Key, Value> value_type; typedef multi_index_container< value_type, indexed_by< hashed_unique<member<value_type, Key, &value_type::key> > > > map_type; map_type map; const value_type* head; const value_type** tail; static value_type last; }; Joaquín M López Muñoz Telefónica, Investiación y Desarrollo
on Sat Nov 01 2008, Joaquin M Lopez Munoz <joaquin-AT-tid.es> wrote:
Not that this has to do with the multi-indexing capabilities of Boost.MultiIndex, but I think you can still take (a little) advantange of the lib by using a multi_index_container<hashed_unique> instead of a unordered_map, because the former has an iterator_to() member function that allows you to retrieve an iterator from a value_type*, so saving you the jump from Key* to an iterator via map.find() that your code has at pop().
Oh, that's awesome! Thanks! -- Dave Abrahams BoostPro Computing http://www.boostpro.com
on Sat Nov 01 2008, Joaquin M Lopez Munoz <joaquin-AT-tid.es> wrote:
Not that this has to do with the multi-indexing capabilities of Boost.MultiIndex, but I think you can still take (a little) advantange of the lib by using a multi_index_container<hashed_unique> instead of a unordered_map, because the former has an iterator_to() member function that allows you to retrieve an iterator from a value_type*, so saving you the jump from Key* to an iterator via map.find() that your code has at pop().
I am using boostpro-1.34.1-svn for this project. Since it is based on boost-1.34.1, it doesn't have iterator_to yet :(. I could backport the multi_index changes, but in reality all I need is a plain unordered_map. If I could prevail upon Daniel James to add iterator_to to Boost.Unordered so it will be there in the future, I'd gladly backport that change into my version -- Dave Abrahams BoostPro Computing http://www.boostpro.com

Sorry about the slow reply. 2008/11/10 David Abrahams <dave@boostpro.com>:
If I could prevail upon Daniel James to add iterator_to to Boost.Unordered so it will be there in the future, I'd gladly backport that change into my version
I'm not sure if it's that simple. The nodes aren't PODs so I don't think 'offsetof' can't be used to get their address (or can it? I've never used it). MultiIndex copes by using aligned_storage and manually constructing the value in place, so that it can get the containing structures address. Which is a possibiliy for the unordered containers, and could help implement emplace for compilers without variadic templates (or for allocators without a variadic construct method) so it might be a good idea anyway. So I'll look into doing that. Daniel
on Tue Nov 18 2008, "Daniel James" <daniel_james-AT-fmail.co.uk> wrote:
Sorry about the slow reply.
2008/11/10 David Abrahams <dave@boostpro.com>:
If I could prevail upon Daniel James to add iterator_to to Boost.Unordered so it will be there in the future, I'd gladly backport that change into my version
I'm not sure if it's that simple. The nodes aren't PODs so I don't think 'offsetof' can't be used to get their address (or can it? I've never used it).
No, not without making them PODs.
MultiIndex copes by using aligned_storage and manually constructing the value in place, so that it can get the containing structures address. Which is a possibiliy for the unordered containers, and could help implement emplace for compilers without variadic templates (or for allocators without a variadic construct method) so it might be a good idea anyway. So I'll look into doing that.
Yeah, I think that's what all containers should be doing anyhow. -- Dave Abrahams BoostPro Computing http://www.boostpro.com

I'm not sure if it's that simple. The nodes aren't PODs so I don't think 'offsetof' can't be used to get their address (or can it? I've never used it).
No, not without making them PODs.
MultiIndex copes by using aligned_storage and manually constructing the value in place, so that it can get the containing structures address.
I'd like to point out that there is also intrusive::detail::parent_from_member, which Ion and I have proposed to move into boost::detail as I think I need it for a fusion-intrusive adapter. (http://lists.boost.org/Archives/boost/2008/06/139094.php) There is some scary code in parent_from_member but AFAIK it works everywhere. I agree that with a "real" container where you control ownership, it might be better to avoid such techniques. Gordon
Gordon Woodhull escribió:
I'm not sure if it's that simple. The nodes aren't PODs so I don't think 'offsetof' can't be used to get their address (or can it? I've never used it).
No, not without making them PODs.
MultiIndex copes by using aligned_storage and manually constructing the value in place, so that it can get the containing structures address.
I'd like to point out that there is also intrusive::detail::parent_from_member, which Ion and I have proposed to move into boost::detail as I think I need it for a fusion-intrusive adapter. (http://lists.boost.org/Archives/boost/2008/06/139094.php)
There is some scary code in parent_from_member but AFAIK it works everywhere.
Not everywhere, I'm afraid: http://lists.boost.org/boost-users/2007/06/28382.php There are definitely some seriously non-standard tricks there that should IMHO discourage us from using parent_from_member unrestrictedly, useful as this utility may be. Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
2008/11/27 <joaquin@tid.es>:
Not everywhere, I'm afraid:
http://lists.boost.org/boost-users/2007/06/28382.php
There are definitely some seriously non-standard tricks there that should IMHO discourage us from using parent_from_member unrestrictedly, useful as this utility may be.
I've already started on an implementation which uses a similar technique to MultiIndex so I don't think I'll need to use parent_from_member. My iterator_to will be a bit slower than MultiIndex's as I have to use the hash function to find the correct bucket. This won't be the case for local_iterator_to. Daniel
Sent from my iPhone On Nov 27, 2008, at 9:59 AM, "Daniel James" <daniel_james@fmail.co.uk> wrote:
2008/11/27 <joaquin@tid.es>:
Not everywhere, I'm afraid:
http://lists.boost.org/boost-users/2007/06/28382.php
There are definitely some seriously non-standard tricks there that should IMHO discourage us from using parent_from_member unrestrictedly, useful as this utility may be.
I've already started on an implementation which uses a similar technique to MultiIndex so I don't think I'll need to use parent_from_member. My iterator_to will be a bit slower than MultiIndex's as I have to use the hash function to find the correct bucket.
Well, that's no improvement over what I already have. I wouldn't bother providing the function unless you can do it more efficiently than that. With the precedent of multi_index it might even be misleading. The code to do that manually is simple enough IMO.
This won't be the case for local_iterator_to.
Daniel _______________________________________________ Unsubscribe & other changes: http://lists.boost.org/mailman/listinfo.cgi/boost
Hi Joaquin, On Nov 27, 2008, at 9:34 AM, joaquin@tid.es wrote:
Gordon Woodhull escribió:
There is some scary code in parent_from_member but AFAIK it works everywhere.
Not everywhere, I'm afraid:
A-ha, I see. Bummer. I might have to debug it on a couple of platforms to use it for my purposes then. Metagraph can be thought of as a multicontainer extension to MultiIndex, or as a heterogeneous extension to Graph. I am using Fusion to compose objects out of their data and Intrusive hooks, so I need a fusion::container_from_element. I am trying to think whether I could adapt Fusion to use the very nice multi_index::detail::pod_value_holder approach, but I don't see it because Fusion uses containment (member variables) rather than inheritance for composition. I assume that's more efficient at compile time (?)
There are definitely some seriously non-standard tricks there that should IMHO discourage us from using parent_from_member unrestrictedly, useful as this utility may be.
I am not as scared by the tricks (they are nicely contained) as by the violation of abstraction. OTOH it's interesting to note that only the class or a friend can grant permission to do parent_from_member for a private member, because access is checked when the member address is taken. I believe iterator_to functionality does justify the danger of parent_from_member, when properly guarded. Thanks for the heads-up and the link, Gordon
________________________________________ De: boost-bounces@lists.boost.org [boost-bounces@lists.boost.org] En nombre de David Abrahams [dave@boostpro.com] Enviado el: sábado, 01 de noviembre de 2008 0:47 Para: boost@lists.boost.org Asunto: Re: [boost] [MultiIndex] Random Access mental model? on Fri Oct 31 2008, Joaquin M Lopez Munoz <joaquin-AT-tid.es> wrote:
Yep, this is done. Only one node per element is allocated. This is true regardless of the indices used, including random access indices. If you want to visualize this, each element node has as many node headers as indices are, each one stacked on top of the next.
I think random access shouldn't need to add a node header unless you want to do something like look up a key in the hash index and delete that element. Maybe a feature-model interface would be a more powerful way to approach this space, so we don't have to pay for what we don't use.
It is very difficult (I suspect impossible) to come up with a satisfactory global picture without this up-pointer. Consider just the following scenario: I have a multi_index_container<hashed,random_access> m and an iterator to the hashed index it. m.erase(it) cannot be implemented without the up-pointer in the random-access index. (If you don't immediately realize why, picture yourself the hand-rolled composition of a hashed_map and a deque<pointer>: you can't erase an element from the combined structure given only a hash_map::iterator). There are lots of additional problems, but I think this is sufficiently serious to justify my decision. Basically, Boost.MultiIndex assumes O(1) inter-index iterator projection (getting from an iterator in an index to an iterator in another index pointing to the same element, in constant time). [...]
The deque-based structure you propose would save, as you say, roughly one pointer per node with respect to sequenced indices and also with respect to random access indices, which have the up-pointer your proposed data structure lacks, while on the other hand it requires an extra pointer as the deque stores pointers while multi_index_containers enjoy the header stacking property referred to above.
So, roughly speaking, things are even.
Sorry, I don't see it. Since I need O(1) pop-front I am using sequenced<> which IIUC is a doubly-linked list. Therefore your nodes have this overhead:
next-in-list, prev-in-list, and next-in-hash-bucket = 3 pointers
and mine have only next-in-hash-bucket. Add one pointer of overhead in the deque and I am storing 2 pointers.
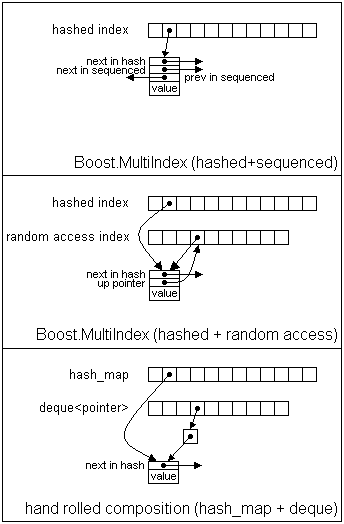
But your deque is a deque of *pointers*, so the (amortized) penalty of the deque is 2 pointers per element. Please take a look at the attached figure, where the resulting data structures are depicted for: * Boost.MultiIndex (hashed + sequenced), * Boost.MultiIndex (hashed + random access), * Hand-rolled composition (hash_map + deque). (The array labeled "deque<pointer>" does not do merit to the actual chunk-based structure used by most deque implementations, but you get the idea, there's on average one pointer per element). Do you see you've got four pointers (black dots) per element in the three structures? Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
{kind=link}
on Sat Nov 01 2008, "JOAQUIN M. LOPEZ MUÑOZ" <joaquin-AT-tid.es> wrote:
________________________________________ De: boost-bounces@lists.boost.org [boost-bounces@lists.boost.org] En nombre de David Abrahams [dave@boostpro.com] Enviado el: sábado, 01 de noviembre de 2008 0:47 Para: boost@lists.boost.org Asunto: Re: [boost] [MultiIndex] Random Access mental model?
on Fri Oct 31 2008, Joaquin M Lopez Munoz <joaquin-AT-tid.es> wrote:
Yep, this is done. Only one node per element is allocated. This is true regardless of the indices used, including random access indices. If you want to visualize this, each element node has as many node headers as indices are, each one stacked on top of the next.
I think random access shouldn't need to add a node header unless you want to do something like look up a key in the hash index and delete that element. Maybe a feature-model interface would be a more powerful way to approach this space, so we don't have to pay for what we don't use.
It is very difficult (I suspect impossible) to come up with a satisfactory global picture without this up-pointer. Consider just the following scenario:
I have a multi_index_container<hashed,random_access> m and an iterator to the hashed index it. m.erase(it) cannot be implemented without the up-pointer in the random-access index. (If you don't immediately realize why, picture yourself the hand-rolled composition of a hashed_map and a deque<pointer>: you can't erase an element from the combined structure given only a hash_map::iterator).
Yes, yes, I understood all that. It's exactly what I was referring to when I wrote "look up a key in the hash index and delete that element." If you don't immediately see why that is the same thing you're talking about, well, please tell me.
There are lots of additional problems,
I disagree with your premise. It's only a problem if it's a problem for me, and since I don't need that functionality I can use a lighter-weight data structure with no up-pointers, just like I'll use a vector instead of a deque when I don't need O(1) modification at the front.
but I think this is sufficiently serious to justify my decision. Basically, Boost.MultiIndex assumes O(1) inter-index iterator projection (getting from an iterator in an index to an iterator in another index pointing to the same element, in constant time).
That's fine; it's not the right library for my application, then.
[...]
The deque-based structure you propose would save, as you say, roughly one pointer per node with respect to sequenced indices and also with respect to random access indices, which have the up-pointer your proposed data structure lacks, while on the other hand it requires an extra pointer as the deque stores pointers while multi_index_containers enjoy the header stacking property referred to above.
So, roughly speaking, things are even.
Sorry, I don't see it. Since I need O(1) pop-front I am using sequenced<> which IIUC is a doubly-linked list. Therefore your nodes have this overhead:
next-in-list, prev-in-list, and next-in-hash-bucket = 3 pointers
and mine have only next-in-hash-bucket. Add one pointer of overhead in the deque and I am storing 2 pointers.
But your deque is a deque of *pointers*,
Uh, yes. One pointer stored in the deque per element.
so the (amortized) penalty of the deque is 2 pointers per element.
Maybe you should explain why you think so.
Please take a look at the attached figure, where the resulting data structures are depicted for:
* Boost.MultiIndex (hashed + sequenced), * Boost.MultiIndex (hashed + random access), * Hand-rolled composition (hash_map + deque).
That's not the data structure I was proposing. The deque elements would point directly to the elements in the hash_map, i.e. hash_map<key, value> + deque<std::pair<key const, value>*> The picture you drew is something like hash_map<key, value> + deque<std::pair<key const, value>**> I can't imagine why you added that extra node.
(The array labeled "deque<pointer>" does not do merit to the actual chunk-based structure used by most deque implementations, but you get the idea, there's on average one pointer per element).
That would only be true if the block size of the deque was 1, but who would build a deque that way? I'm very familiar with deque. There basically are two implementations, one of which uses a circular buffer for the array of block pointers, but fundamentally they have the same storage overhead. If there are N elements and a block can hold B elements the block array stores cieling(N/B) pointers and there are at most N*floor(N/B) + 2*B * sizeof(element) bytes of storage for blocks. As N grows, the 2*B constant becomes unimportant and you N have amortized N *sizeof(element) bytes of element storage and (N/B)*sizeof(block*) bytes of block storage. When the element is a pointer that's (N+N/B)*sizeof(pointer). The only way that can be equal to N*2*sizeof(pointer) is if B==1.
Do you see you've got four pointers (black dots) per element in the three structures?
Yes, but the deque you picture is pathologically inefficient. -- Dave Abrahams BoostPro Computing http://www.boostpro.com
Let me begin by commenting on the final part of the post: you're absolutely right the overhead of deque<pointer> is less than two pointers per element, not two as I was stating in a moment of mental confusion. So, yes, hash_map+deque<pointer> is more memory efficient than a multi_index_container<hashed,sequenced> or a multi_index_container<hashed,random_access>. Sorry for my error, I was thinking less carefully than I should. Now with the rest of the post: David Abrahams <dave <at> boostpro.com> writes:
on Sat Nov 01 2008, "JOAQUIN M. LOPEZ MUÑOZ" <joaquin-AT-tid.es> wrote:
It is very difficult (I suspect impossible) to come up with a satisfactory
global
picture without this up-pointer. Consider just the following scenario:
I have a multi_index_container<hashed,random_access> m and an iterator to the hashed index it. m.erase(it) cannot be implemented without the up-pointer in the random-access index. (If you don't immediately realize why, picture yourself the hand-rolled composition of a hashed_map and a deque<pointer>: you can't erase an element from the combined structure given only a hash_map::iterator).
Yes, yes, I understood all that. It's exactly what I was referring to when I wrote "look up a key in the hash index and delete that element." If you don't immediately see why that is the same thing you're talking about, well, please tell me.
OK, perfect; Let me elaborate a little more the potential implications of having a random_index without up pointers: hashed, ordered and sequenced indices all feature O(1) erase() member functions mimicking those of std::unordered_set, std::set and std::list, respectively. If I were to allow a no-up-pointer random_access index, that'd mean that the interface of the rest of the indices should elmiminate their erase member functions, be it at compile time (the preferred way) or by throwing or something at run time, or else provide O(N) erase behavior, *when* they are coexisting with a randon_access index. Not that this can't be done, at least in principle, but it breaks the current index orthogonality in (IMHO) nasty ways. What's more, the following type multi_index_container<random_access,random_access> couldn't provide any O(1) erase method. Again, this is feasible and in fact a natural implication of the data structures involved, but my design choice was to avoid this kind of anomalies and go for regularity and orthogonality. This also implies that you can devise smarter data structures for some particular purposes, like the case you're dealing with.
There are lots of additional problems,
I disagree with your premise. It's only a problem if it's a problem for me,
I honestly don't understand what this statement means.
and since I don't need that functionality I can use a lighter-weight data structure with no up-pointers, just like I'll use a vector instead of a deque when I don't need O(1) modification at the front.
but I think this is sufficiently serious to justify my decision. Basically, Boost.MultiIndex assumes O(1) inter-index iterator projection (getting from an iterator in an index to an iterator in another index pointing to the same element, in constant time).
That's fine; it's not the right library for my application, then.
This is correct. For your purposes you can have a hand-rolled data structure that beats any possible realization based on Boost.MultiIndex in terms of memory efficiency. Sorry for having dragged this thread longer than necessary with my initial confusion on the ha_map+deque<pointer> issue. [rest snipped as it was addressed at the beginning of this post] Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
on Sat Nov 01 2008, Joaquin M Lopez Munoz <joaquin-AT-tid.es> wrote:
Let me begin by commenting on the final part of the post: you're absolutely right the overhead of deque<pointer> is less than two pointers per element, not two as I was stating in a moment of mental confusion. So, yes, hash_map+deque<pointer> is more memory efficient than a multi_index_container<hashed,sequenced> or a multi_index_container<hashed,random_access>. Sorry for my error, I was thinking less carefully than I should.
Now with the rest of the post:
David Abrahams <dave <at> boostpro.com> writes:
on Sat Nov 01 2008, "JOAQUIN M. LOPEZ MUÑOZ" <joaquin-AT-tid.es> wrote:
It is very difficult (I suspect impossible) to come up with a satisfactory
global
picture without this up-pointer. Consider just the following scenario:
I have a multi_index_container<hashed,random_access> m and an iterator to the hashed index it. m.erase(it) cannot be implemented without the up-pointer in the random-access index. (If you don't immediately realize why, picture yourself the hand-rolled composition of a hashed_map and a deque<pointer>: you can't erase an element from the combined structure given only a hash_map::iterator).
Yes, yes, I understood all that. It's exactly what I was referring to when I wrote "look up a key in the hash index and delete that element." If you don't immediately see why that is the same thing you're talking about, well, please tell me.
OK, perfect; Let me elaborate a little more the potential implications of having a random_index without up pointers: hashed, ordered and sequenced indices all feature O(1) erase() member functions mimicking those of std::unordered_set, std::set and std::list, respectively. If I were to allow a no-up-pointer random_access index, that'd mean that the interface of the rest of the indices should elmiminate their erase member functions, be it at compile time (the preferred way) or by throwing or something at run time, or else provide O(N) erase behavior, *when* they are coexisting with a randon_access index.
No, only when coexisting with a "no-up-pointer random access index." I wasn't suggesting that should be the only random index structure.
Not that this can't be done, at least in principle, but it breaks the current index orthogonality in (IMHO) nasty ways. What's more, the following type
multi_index_container<random_access,random_access>
couldn't provide any O(1) erase method.
How do you erase in O(1) from the middle of a random-access container?
Again, this is feasible and in fact a natural implication of the data structures involved, but my design choice was to avoid this kind of anomalies and go for regularity and orthogonality. This also implies that you can devise smarter data structures for some particular purposes, like the case you're dealing with.
Understood.
There are lots of additional problems,
I disagree with your premise. It's only a problem if it's a problem for me,
I honestly don't understand what this statement means.
and since I don't need that functionality I can use a lighter-weight data structure with no up-pointers, just like I'll use a vector instead of a deque when I don't need O(1) modification at the front.
Suppose you wrote a library that provided only deque, and not vector, as a random access container. Your premise seems analogous to one that says, "not having O(1) push_front for a random access container is a problem." I'm saying it's not a problem to lose a feature unless you need it, especially if you get something in exchange.
but I think this is sufficiently serious to justify my decision. Basically, Boost.MultiIndex assumes O(1) inter-index iterator projection (getting from an iterator in an index to an iterator in another index pointing to the same element, in constant time).
That's fine; it's not the right library for my application, then.
This is correct. For your purposes you can have a hand-rolled data structure that beats any possible realization based on Boost.MultiIndex in terms of memory efficiency. Sorry for having dragged this thread longer than necessary with my initial confusion on the ha_map+deque<pointer> issue.
No problem; it helped me think more clearly about what I was doing. Thanks for taking the time, -- Dave Abrahams BoostPro Computing http://www.boostpro.com
David Abrahams escribió:
on Sat Nov 01 2008, Joaquin M Lopez Munoz <joaquin-AT-tid.es> wrote:
Not that this can't be done, at least in principle, but it breaks the current index orthogonality in (IMHO) nasty ways. What's more, the following type
multi_index_container<random_access,random_access>
couldn't provide any O(1) erase method.
How do you erase in O(1) from the middle of a random-access container?
Ouch... Yep' you're right again. I have thought about this more carefully, and an no-up-pointer random access index might be designed with the following trade-offs with respect to the current random_access: * no stable iterators * no constant iterator projection Other than that, the big-O complexities (constant push_back, etc) can be kept, I think. Do you think this would be a useful addition to B.MI? A suggestion for a name coexisting with the current random_access (which should be kept for the current up-pointer index)? Anyway, I don't think this new index would serve your purposes, since you need some of the elements to be "disconnected" from the list: there might be workarounds like considering the sequence divided into two ranges [begin,first_not_connected),[first_not_connected,end) but I don't know if this holds water.
Suppose you wrote a library that provided only deque, and not vector, as a random access container. Your premise seems analogous to one that says, "not having O(1) push_front for a random access container is a problem." I'm saying it's not a problem to lose a feature unless you need it, especially if you get something in exchange.
Understood. I was meaning that it was a problem to incorporate this feature lacking components into the whole system in a coherent way, but maybe I spoke too fast (see above). Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
participants (7)
-
 Daniel James
Daniel James -
 David Abrahams
David Abrahams -
 Gordon Woodhull
Gordon Woodhull -
 Ion Gaztañaga
Ion Gaztañaga -
 Joaquin M Lopez Munoz
Joaquin M Lopez Munoz -
JOAQUIN M. LOPEZ MUÑOZ
-
joaquin@tid.es