
behold! i've put my lib in the vault/linalg there are sources as well as documentation (zipped html and CHM file) if you are interested you might try to use it or even perform some performance testing (would you mind to post results in that case?) i tried to write documentation so that any user would be able to figure out what's going on and use the lib without difficulties if you'd run through it i hope you get the image of my proposition any constructive comments are welcome -- Pavel ps do anyone know how to kill directories in the vault?

DE wrote:
behold!
i've put my lib in the vault/linalg there are sources as well as documentation (zipped html and CHM file)
if you are interested you might try to use it or even perform some performance testing (would you mind to post results in that case?)
i tried to write documentation so that any user would be able to figure out what's going on and use the lib without difficulties if you'd run through it i hope you get the image of my proposition
A few comments : * prefer operator () to operator[]. operator[] is never needed and is less generic * do you handle multi-dimensional matrix with dim > 2 ? * separating matrix and vector is a bad idea cause a vector is always a matrix. Moreover, you lead the user to wonder about the "orientation" of the vector. * a lot of things need to be doen as policy instead of separate class * If you want to handle more complex operations, using a NRC allcoation schema is better than a sole T* for holding data * why rewriting expr. tempalte from scratch when proto's around ?
on 14.08.2009 at 19:56 Joel Falcou wrote :
DE wrote:
behold!
i've put my lib in the vault/linalg there are sources as well as documentation (zipped html and CHM file)
if you are interested you might try to use it or even perform some performance testing (would you mind to post results in that case?)
i tried to write documentation so that any user would be able to figure out what's going on and use the lib without difficulties if you'd run through it i hope you get the image of my proposition A few comments :
* prefer operator () to operator[]. operator[] is never needed and is less generic internally i alwayse use () but [] are provided for users' convenience
* do you handle multi-dimensional matrix with dim > 2 ? nope
* separating matrix and vector is a bad idea cause a vector is always a matrix. Moreover, you lead the user to wonder about the "orientation" of the vector. but they are handled differently (different public interface) vector is modeled after std::valarray (everybody knows about valarray) and matrix is just a generalization of std::valarray behavior oh and vector is a column-vector
* a lot of things need to be doen as policy instead of separate class what do you mean by policy?
* If you want to handle more complex operations, using a NRC allcoation schema is better than a sole T* for holding data don't get it (forgive my unliteratedness)
* why rewriting expr. tempalte from scratch when proto's around ? i've heard and forgotten i've seen and memorized i've done and understood ...or something like this
-- Pavel
DE wrote:
* prefer operator () to operator[]. operator[] is never needed and is less generic
internally i alwayse use () but [] are provided for users' convenience
It's really not needed. operator(i) is the same semantically and I don't think any STD concept require []. Having matrix be real function object is also a good way to use htem more generically.
but they are handled differently (different public interface) vector is modeled after std::valarray (everybody knows about valarray) and matrix is just a generalization of std::valarray behavior oh and vector is a column-vector
Just don't name it vector then. In lin. Alg. a vector is a matrix with one dimension equal to 1. if not, ppl will wonder why matrix*vector doesn't mean what they think it does.
what do you mean by policy?
You should have one matrix class whose tempalte parameters allow for customization. Want a matrix with static data : matrix<float, settings<static_> >
don't get it (forgive my unliteratedness)
NRC allocation states that a array of N dimension is stored as N array of pointers, each pointinng to sub-element of the next one, the last one being a large, monolithic contiguous array of data. This allow for N-dimensionnal acces via chains of [] and ensures cache locality at the latest level. It's easy to write, can be recursively extended for arbitrary dimension number and ease the writings of code that requires you to extract or work on complex sub-array. performances of access is roughly the same that T* (within a 2% margin). this requires to have an iterface that takes smthg lika boost::array for handling set of dimensions and indexing. sample 2D code here : http://codepad.org/nDy8z2iG of course this has to be hidden in the implementation.
i've heard and forgotten i've seen and memorized i've done and understood ...or something like thi which means ?
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 14.08.2009 at 20:45 joel wrote :
internally i alwayse use () but [] are provided for users' convenience It's really not needed. operator(i) is the same semantically and I don't think any STD concept require []. Having matrix be real function object is also a good way to use htem more generically. i see no contra in you words so i don't get why to drop nice subscript operator[]
but they are handled differently (different public interface) vector is modeled after std::valarray (everybody knows about valarray) and matrix is just a generalization of std::valarray behavior oh and vector is a column-vector Just don't name it vector then. In lin. Alg. a vector is a matrix with one dimension equal to 1. if not, ppl will wonder why matrix*vector doesn't mean what they think it does. well i always thought that 'vector' is a column vector if not stated explicitly otherwise for me it's obvious so (matrix*vector) is obviously a vector (column vector)
You should have one matrix class whose tempalte parameters allow for customization. Want a matrix with static data : matrix<float, settings<static_> > i thought about that and i agree that your variant is a better idea but i have not started to refine the code yet to my flavor it must be something like
matrix<double, some_container_like_type<double> > //^^ double? or even matrix<double, some_container_like_template_type> //template template parameter is used
NRC allocation states that a array of N dimension is stored as N array of pointers, each pointinng to sub-element of the next one, the last one being a large, monolithic contiguous array of data. This allow for N-dimensionnal acces via chains of [] and ensures cache locality at the latest level. It's easy to write, can be recursively extended for arbitrary dimension number and ease the writings of code that requires you to extract or work on complex sub-array. performances of access is roughly the same that T* (within a 2% margin). this requires to have an iterface that takes smthg lika boost::array for handling set of dimensions and indexing. sample 2D code here : http://codepad.org/nDy8z2iG of course this has to be hidden in the implementation. sounds cool but i have no any tasks with >2 order involved so i was not even considering i will think about it is it a must have feature in your opinion?
i've heard and forgotten i've seen and memorized i've done and understood ...or something like thi which means ? which means that if i have not done that i have not understood it
-- Pavel
i see no contra in you words so i don't get why to drop nice subscript operator[]
In fatc I just noticed you had both v_v so moot point here.
well i always thought that 'vector' is a column vector if not stated explicitly otherwise for me it's obvious so (matrix*vector) is obviously a vector (column vector)
Well, explicit things are better when explicited.
but i have not started to refine the code yet to my flavor it must be something like
matrix<double, some_container_like_type<double> > //^^ double? or even
matrix<double, some_container_like_template_type> //template template parameter is used
Well, the policy things is extendable to a lot of thing : shape, dimension, storage, static size,optional behavior etc... static/dynamic is just an example. Here is a sample of NT² code where I create a 3D matrix with compile time size use 5x5 tiling when evaluated and unrolled by a factor 3 : matrix<float, settings( _3D::OfSize<50,50>, tiling<5,5>, unroll<3> ) > m; Now the same matrix but with a static storage matrix<float, settings( _3D::OfSize<50,50>, static_storage, tiling<5,5>, unroll<3> ) > n;
sounds cool but i have no any tasks with >2 order involved so i was not even considering i will think about it is it a must have feature in your opinion? Well, it really makes things like :
m(_i,_j) = m(_i+1,_j+1) * n(_j,_i); really easy to implement. Other nice things is : m( (3 < _i < 5) && ( _j % 3) ) = value; and other boolean based acces. You can also impelemnt matrix-matrix acces in a pinch. aka matrix<float> x; matrix<int> u; x(u) = ...; More over it has no side effect on performances so using it or not is always good.
which means that if i have not done that i have not understood it
OK I've stopepd fiddlign with ET by hand since proto is out cause it makes things easier to reason about. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 14.08.2009 at 21:30 joel wrote :
i see no contra in you words so i don't get why to drop nice subscript operator[] In fatc I just noticed you had both v_v so moot point here. agree
Well, it really makes things like : m(_i,_j) = m(_i+1,_j+1) * n(_j,_i); really easy to implement. Other nice things is : m( (3 < _i < 5) && ( _j % 3) ) = value; and other boolean based acces. You can also impelemnt matrix-matrix acces in a pinch. aka matrix<float> x; matrix<int> u; x(u) = ...; More over it has no side effect on performances so using it or not is always good. good point agree
-- Pavel
and talking about that... it looks as perversion to me who would access to matrix like that? if u is a matrix of 2xN or Nx2 it can be seen as a list of indexes.
DE wrote: that's a common idiom in matlab. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 14.08.2009 at 22:21 joel wrote :
and talking about that... it looks as perversion to me who would access to matrix like that? if u is a matrix of 2xN or Nx2 it can be seen as a list of indexes.
DE wrote: that's a common idiom in matlab. now i see it's like a generalized slice for valarray at that point i totally agree
-- Pavel

On 14 Aug 2009, at 19:01, DE wrote:
and talking about that... it looks as perversion to me who would access to matrix like that? if u is a matrix of 2xN or Nx2 it can be seen as a list of indexes.
DE wrote: that's a common idiom in matlab.
Seconded - this kind of indirect indexing is exceptionally useful. -ed
but they are handled differently (different public interface) vector is modeled after std::valarray (everybody knows about valarray) and matrix is just a generalization of std::valarray behavior oh and vector is a column-vector
Just don't name it vector then. In lin. Alg. a vector is a matrix with one dimension equal to 1. if not, ppl will wonder why matrix*vector doesn't mean what they think it does.
Just to stick my oar in -- there is also a subtle difference between a covector and a vector. This rarely seems to get a look-in when people implement linear algebra stuff. They may well be represented as a tuple in both cases but they interact differently. For example. covector*vector = scalar [inner product] vector*covector = tensor [outer product] Usually they are represented as columns (vectors) and rows (covectors). a) 1 2 3 b) 1 2 3 a*b = 14 (inner product) b*a = 1 2 3 2 4 6 3 6 9 (outer product) [N.B. there are still only 6 independent components]
http://en.wikipedia.org/wiki/ Einstein_notation#Common_operations_in_this_notation It would be great if these objects could be made to 'do the right thing', MATLAB does, mostly (it's MAT lab after all not TENS lab). Being able to write stuff like: vector w,u,v; // They are all (column) vectors. ... w = levi_civita*u*v; and get out the conventional cross product u x v when u and v have length 3, as a special case of exterior products, or, w = wedge(u,v); // Wedge product, function form w = u ^ v; // Wedge product operator form. Though I'm not sure it has the right precedence properties... would be pretty neat. I'll go away and hide now.... -ed
Edward Grace wrote:
but they are handled differently (different public interface) vector is modeled after std::valarray (everybody knows about valarray) and matrix is just a generalization of std::valarray behavior oh and vector is a column-vector
Just don't name it vector then. In lin. Alg. a vector is a matrix with one dimension equal to 1. if not, ppl will wonder why matrix*vector doesn't mean what they think it does.
Just to stick my oar in -- there is also a subtle difference between a covector and a vector. This rarely seems to get a look-in when people implement linear algebra stuff. They may well be represented as a tuple in both cases but they interact differently. For example.
Exactly and that's lead to impractical interface. Having vector be matrix with one dim = 1 solves this. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 14.08.2009 at 21:23 Edward Grace wrote :
Just to stick my oar in -- there is also a subtle difference between a covector and a vector. This rarely seems to get a look-in when people implement linear algebra stuff. They may well be represented as a tuple in both cases but they interact differently. For example. covector*vector = scalar [inner product] vector*covector = tensor [outer product] Usually they are represented as columns (vectors) and rows (covectors).
a) 1 2 3
b) 1 2 3
a*b = 14 (inner product) b*a = 1 2 3 2 4 6 3 6 9 (outer product) [N.B. there are still only 6 independent components] well if we consider a vector to be a column vector then inner product will be
http://en.wikipedia.org/wiki/ Einstein_notation#Common_operations_in_this_notation It would be great if these objects could be made to 'do the right thing', MATLAB does, mostly (it's MAT lab after all not TENS lab). Being able to write stuff like: vector w,u,v; // They are all (column) vectors. ... w = levi_civita*u*v; and get out the conventional cross product u x v when u and v have length 3, as a special case of exterior products, or, w = wedge(u,v); // Wedge product, function form w = u ^ v; // Wedge product operator form. Though I'm not sure it has the right precedence properties... would be pretty neat. I'll go away and hide now.... unfortunately i think in linalg domain (you think in tensor domain i guess) so we may misanderstand each other in the end i think it's possible to attach a mechanism to support tensor style operations by the way w = u ^ v; it's terribly wrong to overload '^' in such a way
transpose(vector)*vector //covector*vector; actually here we //get 1x1 matrix and outer product vector*transpose(vector) //vector*covector since a vector is actually a matrix we can transpose it the following is much MUCH more better solution:
w = wedge(u,v);
-- Pavel
it's terribly wrong to overload '^' in such a way the following is much MUCH more better solution:
w = wedge(u,v);
w = cross_product(u,v) please :p -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
On 14 Aug 2009, at 18:43, DE wrote:
it's terribly wrong to overload '^' in such a way
Why? The precedence rules? Fair enough - sometimes what's tempting is bad for you, but you still want to try it anyway!
w = wedge(u,v);
w = cross_product(u,v) please :p
Err, that's only true in 3D (vectors of length 3). There's no such thing as a cross product between (say) vectors of length 2,4 or indeed anything else. The cross product is, in effect, a restricted version of the exterior (wedge) product which exists for higher dimensions. -ed
Err, that's only true in 3D (vectors of length 3). There's no such thing as a cross product between (say) vectors of length 2,4 or indeed anything else. The cross product is, in effect, a restricted version of the exterior (wedge) product which exists for higher dimensions. Oh, I thought cross product was the general name. I'll note the term wedge for future ref.
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 15.08.2009 at 1:12 Edward Grace wrote :
it's terribly wrong to overload '^' in such a way Why? The precedence rules? Fair enough - sometimes what's tempting is bad for you, but you still want to try it anyway! because '^' is associated with bitwise xor operator and there is no such operation on vectors it is semantically wrong
w = wedge(u,v); w = cross_product(u,v) please :p Err, that's only true in 3D (vectors of length 3). There's no such thing as a cross product between (say) vectors of length 2,4 or indeed anything else. The cross product is, in effect, a restricted version of the exterior (wedge) product which exists for higher dimensions. if i get the point right consider wedge_product(u,v) or exterior_product(u,v)
-- Pavel
On 14 Aug 2009, at 22:27, DE wrote:
on 15.08.2009 at 1:12 Edward Grace wrote :
it's terribly wrong to overload '^' in such a way Why? The precedence rules? Fair enough - sometimes what's tempting is bad for you, but you still want to try it anyway! because '^' is associated with bitwise xor operator and there is no such operation on vectors it is semantically wrong
Err - surely the point of overloading is to assign meaningful context specific behaviour to the same operator, so. unsigned a,b,c; c = a ^ b; // ^ => XOR makes sense. pseudovector<3> c; vector<3> a,b; c = a ^ b; // ^ => Wedge product makes sense XOR does not. It seems reasonable - at least at first sight. I can understand the objection vis-a-vis operator precedence and associativity constraints though - e.g. pseudoscalar<double> s; vector<3> a,b,c; s = a ^ b ^ c; // Equivalent to scalar triple product. What's first (a ^ b) ^ c, a ^ (b ^ c) it shouldn't matter - I don't recall the implicit associativity , precedence of the XOR operator.... Anyhow, wedge(a,b) --- much less potential for trouble ! ;-) One thing to bare in mind, type trouble! Sticking with ^, since it's easier to write. If each entity is a vector of length 3, a ^ b ^ c | | +---+---+ | directed area a.k.a. bivector [a pseudovector] | | +--------+---------+ | directed volume a.k.a. trivector [a pseudovector] If, for example, b and c were pseudovectors then s would be a (true) scalar and could be assigned to the concrete type double. This is where carrying along some (meta) information concerning the transformation rules of these different entities would be both tricky and crucial.
w = wedge(u,v); w = cross_product(u,v) please :p Err, that's only true in 3D (vectors of length 3). There's no such thing as a cross product between (say) vectors of length 2,4 or indeed anything else. The cross product is, in effect, a restricted version of the exterior (wedge) product which exists for higher dimensions. if i get the point right consider wedge_product(u,v) or exterior_product(u,v)
Yes indeed. Or, if the vector has exactly 3 elements you can say... vector<3> u,v; cross_product(u,v); but only then. -ed P.S. Anyone wondering what the heck a pseudo-vector/scalar is: http://en.wikipedia.org/wiki/Triple_product just when you thought the distinction between vectors / covectors was confusing enough!
Edward Grace wrote:
Err - surely the point of overloading is to assign meaningful context specific behaviour to the same operator, so.
unsigned a,b,c; c = a ^ b; // ^ => XOR makes sense.
pseudovector<3> c; vector<3> a,b; c = a ^ b; // ^ => Wedge product makes sense XOR does not.
Well, except there is use case in computer vision or machien learning in which you have large matrix of integer on which you apply bitwise operation before feeding to some solver. ^ is clearly 'elementwise xor' in this context. so wedge_product is a better alternative.
If, for example, b and c were pseudovectors then s would be a (true) scalar and could be assigned to the concrete type double. This is where carrying along some (meta) information concerning the transformation rules of these different entities would be both tricky and crucial. In NT2 matrix of size(1,1) are castable to scalar and such operations works flawlessly.
________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
On 15 Aug 2009, at 07:28, joel wrote:
Edward Grace wrote:
Err - surely the point of overloading is to assign meaningful context specific behaviour to the same operator, so.
unsigned a,b,c; c = a ^ b; // ^ => XOR makes sense.
pseudovector<3> c; vector<3> a,b; c = a ^ b; // ^ => Wedge product makes sense XOR does not.
Well, except there is use case in computer vision or machien learning in which you have large matrix of integer on which you apply bitwise operation before feeding to some solver. ^ is clearly 'elementwise xor' in this context.
Hmm, is the 'vector' and 'matrix' paradime you have in mind in the same manner as MATLAB? There they seem to be two-faced, they are mathematical vectors and matricies but also just collections of values. Perhaps there needs to be a reasonable distinction between element wise operations and global operations on the object, for instance all the different types of product - Matrix product (* in MATLAB) - Hadamard product (.* in MATLAB) - Kronecker product (kron(A,B) in MATLAB) - Tensor product (tprod MATLAB Mex http://www.mathworks.com/ matlabcentral/fileexchange/16275)
so wedge_product is a better alternative.
Fair enough...
If, for example, b and c were pseudovectors then s would be a (true) scalar and could be assigned to the concrete type double. This is where carrying along some (meta) information concerning the transformation rules of these different entities would be both tricky and crucial. In NT2 matrix of size(1,1) are castable to scalar and such operations works flawlessly.
Hmm, on second thoughts distinguishing between a pseudo<vector/ scalar> and vector/scalar probably doesn't matter for any practical purposes. -ed
Edward Grace wrote: > Hmm, is the 'vector' and 'matrix' paradime you have in mind in the > same manner as MATLAB? Yes, NT2 is no more no less than a copycat of Matlab in C++ > There they seem to be two-faced, they are mathematical vectors and > matricies but also just collections of values. They are. nt2::matrix acts a s multi-dimensional collection of numerical values that supports large nbr of functions and methods. > Perhaps there needs to be a reasonable distinction between element > wise operations and global operations on the object, for instance all > the different types of product > > - Matrix product (* in MATLAB) > - Hadamard product (.* in MATLAB) > - Kronecker product (kron(A,B) in MATLAB) > - Tensor product (tprod MATLAB Mex > http://www.mathworks.com/matlabcentral/fileexchange/16275) What I do now is having : - * being matrix product - mul() beign Hadamard - kron and tprod bieng what they are. Of course matrix * scalar falls back to Hadamard. The underlying principles of NT2 is that matrix is the common representation for all domain-specific entities. So we have a polynom, image and even transform object that reuse components of matrix to perform their computation but with a stricter semantic. Matrix also play the role of Lin. Alg. matrix and vector. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
On 15 Aug 2009, at 11:00, joel wrote:
Edward Grace wrote:
Hmm, is the 'vector' and 'matrix' paradime you have in mind in the same manner as MATLAB? Yes, NT2 is no more no less than a copycat of Matlab in C++
Right, I'm intrigued. Let's have a butchers! -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
i'll try just one more time on 15.08.2009 at 14:00 joel wrote :
The underlying principles of NT2 is that matrix is the common representation for all domain-specific entities. So we have a polynom, image and even transform object that reuse components of matrix to perform their computation but with a stricter semantic. Matrix also play the role of Lin. Alg. matrix and vector. ok suppose i'm a not too experienced programmer and i want to express that my function foo() takes a column vector as a parameter considering 'matrix' and 'vector' be distinct types i would write:
void foo(const lib::vector<some_type> &v); it is type safe and the intent is very clear as foo() author i know that i get v.size() by 1 matrix (actually a vector) and can access elements with subscript operator[] it is common and it is among the first things every programmer learns how would i deal with generic matrix? -- Pavel
DE wrote:
suppose i'm a not too experienced programmer and i want to express that my function foo() takes a column vector as a parameter considering 'matrix' and 'vector' be distinct types i would write:
void foo(const lib::vector<some_type> &v);
it is type safe and the intent is very clear as foo() author i know that i get v.size() by 1 matrix (actually a vector) and can access elements with subscript operator[] it is common and it is among the first things every programmer learns
how would i deal with generic matrix Using latest NT2 interface, you'll use a semi-statically bound matrix :
void foo( nt2::matrix<T, settings( OfSize<unspec, 1>)> const& v ); -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35

On Fri, 14 Aug 2009, Edward Grace wrote:
On 14 Aug 2009, at 18:43, DE wrote:
w = wedge(u,v);
w = cross_product(u,v) please :p
Err, that's only true in 3D (vectors of length 3). There's no such thing as a cross product between (say) vectors of length 2,4 or indeed anything else. The cross product is, in effect, a restricted version of the exterior (wedge) product which exists for higher dimensions.
Actually, it was developed the other way; the exterior product is one possible generalization of the cross product to higher dimensions. The cross product is unique in R3, but other generalizations are possible. IMO, cross_product(u,v) should still be provided for R3, even if it is simply an inline call to exterior_product(u,v). - Daniel
On 14 Aug 2009, at 22:53, dherring@ll.mit.edu wrote:
On Fri, 14 Aug 2009, Edward Grace wrote:
On 14 Aug 2009, at 18:43, DE wrote:
w = wedge(u,v);
w = cross_product(u,v) please :p
Err, that's only true in 3D (vectors of length 3). There's no such thing as a cross product between (say) vectors of length 2,4 or indeed anything else. The cross product is, in effect, a restricted version of the exterior (wedge) product which exists for higher dimensions.
Actually, it was developed the other way; the exterior product is one possible generalization of the cross product to higher dimensions.
Mea culpa - you're right of course. Maths history often seems to get 'renormalised' like this. Like the unit vectors being i,j,k when these characters originally (Hamilton) referred to the imaginary numbers of the quaternion. Then quaternions fell out of fashion and vector calculus took over so now everyone thinks i,j,k are and were always just the unit vectors of R3. Talk to an algebraist and they'll say - "oh, quaternions <insert dismissive sneer here> just a type of Clifford Algebra" - so the competition continues!
The cross product is unique in R3, but other generalizations are possible. IMO, cross_product(u,v) should still be provided for R3, even if it is simply an inline call to exterior_product(u,v).
Once one has gone and made things more complicated they can be simplified again and one can pretend it was always that way! That's how the game works no? ;-) -ed

DE wrote: [snip]
(outer product) [N.B. there are still only 6 independent components] well if we consider a vector to be a column vector then inner product will be
transpose(vector)*vector //covector*vector; actually here we //get 1x1 matrix
vector*transpose(vector) //vector*covector
+1 for this syntax Rutger
On 14 Aug 2009, at 18:41, joel wrote:
DE wrote: [snip]
(outer product) [N.B. there are still only 6 independent components] well if we consider a vector to be a column vector then inner product will be
transpose(vector)*vector //covector*vector; actually here we //get 1x1 matrix
vector*transpose(vector) //vector*covector
+1 for this syntax
Rutger
+1 here too.
and outer product
vector*transpose(vector) //vector*covector
since a vector is actually a matrix we can transpose it
Well, semantics I know but they are all tensors. A scalar -> tensor of order 0, vector -> a tensor of order 1, matrix -> a tensor of order 2. ;-)
w = wedge(u,v); // Wedge product, function form w = u ^ v; // Wedge product operator form. Though I'm not sure it has the right precedence properties... would be pretty neat. I'll go away and hide now.... unfortunately i think in linalg domain (you think in tensor domain i guess) so we may misanderstand each other in the end i think it's possible to attach a mechanism to support tensor style operations by the way
The more I think about it the less inclined I am towards 'tensors are the one true way'. Since we can ultimately represent everything (conceptually) as matrices it may (perversely) make some sense to treat tensors as a special type of matrix, embuing them with certain properties. This way it keeps the development reasonably sane, works for most of the people all the time and could be extended later. I will ponder that.... -ed
The more I think about it the less inclined I am towards 'tensors are the one true way'. Since we can ultimately represent everything (conceptually) as matrices it may (perversely) make some sense to treat tensors as a special type of matrix, embuing them with certain properties. This is right. I think we can have a core representation of "N-dimension
Edward Grace wrote: body of numerical data" that get used as the base for all matrix/tensor class and expression and not the other way around.
Well, semantics I know but they are all tensors. A
scalar -> tensor of order 0, vector -> a tensor of order 1, matrix -> a tensor of order 2. ;-) This is just giving rules to transform one body into the other. And just because I like repeating myself, vector is IMHO redundant.
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
to everyone (especially joel falcou) hi again i see that we have different views on linear lagebra lib design so would you mind to waste a bit of your time to examine the design i provided (vault/linalg) and do heavily criticize it i want you make me cry! (everyone is welcomed) so i can unmask obvious flaws in it and eliminate them till now i actually don't see any critical flaws in the design implementation will be altered in any way of course -- Pavel
DE wrote:
to everyone (especially joel falcou)
Damn, I'm unmasked :p
till now i actually don't see any critical flaws in the design implementation will be altered in any way of course
Well, the problem is not the design per itself. What usually happens with such lib is that you have tons of different user types that all want disjoint set of features. Matrix lib always looks easy to do. Except they are not. I can toss you tons of questions : will you support openMP, threading, MPI, SIMD extensions, will you embed loop level optimization based on expression introspection ? Will you interface looks like matlab, maple or mathematica ? etc ... Not even counting the things we barely scratched like storage mode, allocation mode etc... That's why I'm avoiding to comment your code cause I'm developing something similar but for a somehow different audience than yours and my view will prolly be radically different than yours. I can also only reiterate the fact that I have a somehow large code base for such a thing that's maybe worth reusing. Three heads are better than two I think. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 15.08.2009 at 13:14 joel wrote :
Well, the problem is not the design per itself. What usually happens with such lib is that you have tons of different user types that all want disjoint set of features. use DRY (don't repeat yourself) idiom i got it
Matrix lib always looks easy to do. Except they are not. I can toss you tons of questions : will you support openMP, well it seems trivial to me
threading, i dream about a way like
MPI,
#include <the_lib/lib.h> #include <the_lib/threading.h> //enabling threading for the_lib that would be perfect for me possibly
SIMD definitely yes
extensions, there must be a common way for common users
will you embed loop level optimization based on expression introspection ? sooner or later
Will you interface looks like matlab, maple or mathematica ? i prefer to model STL interfaces where appropriate in general: as common as possible
etc ... Not even counting the things we barely scratched like storage mode, allocation mode etc... of course it is such a missingd feature it must be there
That's why I'm avoiding to comment your code cause I'm developing something similar but for a somehow different audience than yours and my view will prolly be radically different than yours. but i can get some useful stuff from a radically different design and utilize it to make the design better
I can also only reiterate the fact that I have a somehow large code base for such a thing that's maybe worth reusing. sorry but i didn't get the point
Three heads are better than two I think. indeed
-- Pavel
DE wrote:
well it seems trivial to me #include <the_lib/lib.h> #include <the_lib/threading.h> //enabling threading for the_lib
that would be perfect for me
MPI,SIMD ...
Yeah, come back in 2-3 years :) It's all but trivial. nT2 is only dealing with SIMD, openMp and threads and is already a 4 years work of 2 peoples.
Will you interface looks like matlab, maple or mathematica ?
i prefer to model STL interfaces where appropriate in general: as common as possible
Except most user (mathematician) don't even know them. They want to build matrix liek they do with their high level prototyping tools. They don't care about modeling Random Access Sequence or needing to fullfill DefaultConstructible concepts. That's why i consider Eigen2 and other attempt as too far from real user concern. STL like interface in addition to super-easy matlab is better but a dry STL complaint will get nobody to use it apart from already hardcore developers.
That's why I'm avoiding to comment your code cause I'm developing something similar but for a somehow different audience than yours and my view will prolly be radically different than yours.
but i can get some useful stuff from a radically different design and utilize it to make the design better
What I mean is that you're starting to duplicate all the thinds I already dealt with during my PHD and the last 2 years of research and development. But if you like banging heads on walls that other people already removed elsewhere , it's up to you. What I wanted to say is that it's maybe better if we team up, reusing our existing code base and boostify it. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
till now i actually don't see any critical flaws in the design implementation will be altered in any way of course
Well, the problem is not the design per itself. What usually happens with such lib is that you have tons of different user types that all want disjoint set of features.
Amen! I'm off on a bit of a rant here, glaze over... One thing that bugs me a little is the lack of communication between the C++ (or indeed CS) community and the scientific community, both sides are at fault here. For example: A | B C++ world | Science world - ------------------+-------------------- std::complex | Ok, finally at long last but seriously HOW LONG DID THAT TAKE!? std::vector | Huh? That's not a vector dammit! std::valarray | Huh? What only 1D - not much of an array. std::transform | Err, map? What you mean to apply something to every element in an | array I've got to write a whole new function? (yes I know about lambdas) ? [still] | Matrices such a fundamentally useful thing | that simply isn't native to the language and keeps people | tied to F90. | int/int=int | What do you mean I can divide an integer by an integer? Integers are not | closed under division - this makes no sense, I'm going to the pub. Obviously there are good reasons column A is what it is, but if one's ignorant of that it looks odd when viewed from column B. I still maintain that doing scientific computing in C++ is an uphill struggle. Some may argue that C++ is not about the library its about the language. In practice the pragmatic pick a language because of the library. The STL (and Boost of course) bridges that gap somewhat, but a ratified SSTL (Scientific Standard Template Library) would be a massive boon to C++ for science.
Matrix lib always looks easy to do. Except they are not.
The plethora of rarely used half finished C++ linear algebra libraries on the web are a testament to that.
I can toss you tons of questions : will you support openMP, threading, MPI, SIMD extensions, will you embed loop level optimization based on expression introspection ?
Joel, as an aside - have people (e.g. you) started looking at using C+ + metadata to carry out code transformations that span abstractions - potentially very useful for parallelising? For example being able to concretely make certain guarantees about the dependence of various variables (e.g. regarding aliasing) in a program could allow higher- level optimisations to be performed.
Will you interface looks like matlab, maple or mathematica ? etc ... Not even counting the things we barely scratched like storage mode, allocation mode etc...
That's why I'm avoiding to comment your code cause I'm developing something similar but for a somehow different audience than yours and my view will prolly be radically different than yours.
I can also only reiterate the fact that I have a somehow large code base for such a thing that's maybe worth reusing. Three heads are better than two I think.
One thing I would certainly be keen on seeing would be a 'best of breed' linear algebra / tensor and scientific computing library. The obvious place this should live would be Boost. That said, I think the amount of work involved here should not be underestimated. My bet is that there are so many of these 'matrix' libraries out there because people discover object orientation, then template metaprogramming and plough on to write their own library. When it gets good enough for what they want they stop - the full problem as I think Joel is eluding to is huge and very very hard indeed. Ideally a project like this should get some sort of sponsorship. If a team of (say) 4 C++ experts could be put together with a team of other stakeholders (mathematicians, physicists and engineers) and FORTRAN90 HPC experts - who will have a wealth of experience, with some industry support (e.g. NVIDIA) truly great things could happen. Oh, I forgot, after probably 10 years of development. -ed
Edward Grace wrote:
I still maintain that doing scientific computing in C++ is an uphill struggle. Some may argue that C++ is not about the library its about the language. In practice the pragmatic pick a language because of the library. The STL (and Boost of course) bridges that gap somewhat, but a ratified SSTL (Scientific Standard Template Library) would be a massive boon to C++ for science. That's somehow my long term objective as a researcher. The state of the art C++ idioms are now matrue enough to help us do it right. The plethora of rarely used half finished C++ linear algebra libraries on the web are a testament to that. Mine being the first alas :/ Joel, as an aside - have people (e.g. you) started looking at using C++ metadata to carry out code transformations that span abstractions - potentially very useful for parallelising? For example being able to concretely make certain guarantees about the dependence of various variables (e.g. regarding aliasing) in a program could allow higher-level optimisations to be performed. Well, I can send you copy of the Europar 08 paper I wrote that deals with introspecting C++ expression using ET to know when the threading is useful and when it's not. This is my main topic of interest but I'm more on the library side than compiler side. My objectives now is to have a
collection of heuristic on domain specific expression AST that helps me know which kind of parallelism or other optimization I can or shoudl apply.
That said, I think the amount of work involved here should not be underestimated. My bet is that there are so many of these 'matrix' libraries out there because people discover object orientation, then template metaprogramming and plough on to write their own library. When it gets good enough for what they want they stop - the full problem as I think Joel is eluding to is huge and very very hard indeed. It is. And it gets uglier and uglier as new fancy machines comes out. I have funding this years for just porting the core NT2 over GPUs and it looks friggin massive. Ideally a project like this should get some sort of sponsorship. If a team of (say) 4 C++ experts could be put together with a team of other stakeholders (mathematicians, physicists and engineers) and FORTRAN90 HPC experts - who will have a wealth of experience, with some industry support (e.g. NVIDIA) truly great things could happen. We're two here doing that : me as the lead C++ and parallelism developer and Jean-Thierry Lapresté which is a professor of mathematics that helps with the algebra algorithm and hit me with a large trout when he found
At an even larger scope, what I want to do is solve the problem of "auto-parallelisation" not by findign *the* general heuristic for doign it but by slicing the problem one domain after the other, find the domain heuristic adn use things like proto and generative programming to stich the domain together. We can go private if you want more details. the interface starts to look to cumbersome for base users. We don't mind heads and hands from any other side of the fences. NT2 is already using boost license so if needed it can become a candidate for boost library status all together. In fact, well, if anyoen interested we can setup some work plans. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
<WARNING! LOT OF LETTERS!> to all on 15.08.2009 at 13:14 joel wrote :
till now i actually don't see any critical flaws in the design implementation will be altered in any way of course Well, the problem is not the design per itself. What usually happens with such lib is that you have tons of different user types that all want disjoint set of features. about tons of user types here is a train of thought (great album by Dream Theater by the way)
(general case) consider there are a matrix_expression class and a matrix class which derives from matrix_expression<matrix<type> > (CRTP) we can now write stuff like matrix<type> m = m1*m2 + m3*a; //a is a scalar then one must think that allocating matrix on the stack is a good idea since such (compile time) decision must be implemented somewhere, why not in a distinct type? no problem! static_matrix<type, 3, 3> m /*= m1*m2 + m3*a*/; //^^here goes size of matrix it derives from matrix_expression<static_matrix<type, 3, 3> > so all operations fall to general case it could actually be 'matrix<type, 3, 3>' but either it is perfectly readable, easy to understand, easy to implement you are welcome... and also one can write void foo(const static_matrix<type, 3, 3> &m); clearly stating that "i really wanna get a 3 by 3 matrix specifically of that type!" of course he (the one) meant 'static_matrix' type "but hey! i also have a symmetric matrix which must be handled a bit special" the one may say again, not a problem lets define 'symmetric_matrix_expression' which derives from matrix_expression we can do this because actually they are connected with 'is-a' relationship, in other words symmetric matrix is a matrix (but not vice versa) so we deliver 'symmetric_matrix' (which derives from symmetric_matrix_expression) and now can optimize some operations: symmetric_matrix<type> m = m1*m2 + m3*a; //m1, m2 & m3 are symmetric now one can clearly state that he void need_symmetric(const symmetric_matrix<type> &m); for a particular operation and if another user write matrix<type> m; //... need_symmetric(m); //need to explicitly turn m to symmetric it won't compile because 'm' is not necessarily symmetric but in an expression m = m1 + symmetric1*symmetric2; operations will fall back to general case isn't it nice? why stopping? then one can define diagonal_matrix_expression which is actually symmetric so it derives from symmetric_matrix_expression bla bla bla... define diagonal_matrix... bla bla bla... (by the way an identity matrix is diagonal) then one can write diagonal_matrix<type> d = identity<type>(v.size()) + diag(v); //v is a vector while symmetric1 - a*identity<type>(N) is still a symmetric expression (and can be handled acordingly) resume: in my opinion this all is convinient, delivers clarity of user code, easy to understand and implement, easy to customize and extend what do you think about it? -- Pavel
about tons of user types No, I was speaking of matrix of user defined nuemrical types ;) But the discussion on shape is good [snip]
resume: in my opinion this all is convinient, delivers clarity of user code, easy to understand and implement, easy to customize and extend
what do you think about it Yet again, use policy. It'll clutter the code to have 34567 names for different object while having the shape as a template policy is
DE wrote: prolly better. ANd the enforcement of shape semantic has to be implicit and static, no need for need_simmetric. matrix<float, settings(diagonal)> m; For checking arguments of elements with same shape, just use tag dispatching or SFINAE instead of concrete typing. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 17.08.2009 at 10:30 joel wrote :
No, I was speaking of matrix of user defined nuemrical types ;) But the discussion on shape is good oops, my bad
Yet again, use policy. It'll clutter the code to have 34567 names for different object while having the shape as a template policy is prolly better. ANd the enforcement of shape semantic has to be implicit and static, no need for need_simmetric.
matrix<float, settings(diagonal)> m;
For checking arguments of elements with same shape, just use tag dispatching or SFINAE instead of concrete typing.
my question is: is a common user able to write just what he wants? e.g. i want to take as a parameter in my function a diagonal matrix, shoud i write void foo(const matrix<float, settings(symmetric)> &m); to me it is more convenient to write void foo(const symmetric_matrix<float> &m); //it's even shorter my point is since we need to implement such features why not in a distinct type? that will provide proper interface to each concrete featured entity e.g. a symmetric matrix can have such an interface: template<...> //parameters omitted for simplicity class symmetric_matrix : public symmetric_matrix_expression<...> { //... explicit symmetric_matrix(size_t size); //since it is square //... //there's no need for void resize(size_t size); //distinct rows/columns //etc... //numbers } so a user will not even be able to write such nonsensical code like symmetric1.resize(10, 10); //note unnecessary duplication because symmetric_matix does not even provide such interface and will not leave user wandering if he missed the key and typed '(10, 19)' with unreadable compiler error somewhere in instantiated templates as far as i know policies can not do this unless it is full specialized and the latter i think is equivalent to a distinct type -- Pavel
DE wrote:
e.g. a symmetric matrix can have such an interface:
template<...> //parameters omitted for simplicity class symmetric_matrix : public symmetric_matrix_expression<...> { //... explicit symmetric_matrix(size_t size); //since it is square //... //there's no need for void resize(size_t size); //distinct rows/columns //etc... //numbers }
so a user will not even be able to write such nonsensical code like
symmetric1.resize(10, 10); //note unnecessary duplication
First, concrete inheritance like this == bad performances. Use CRTP I'm against the proliferation of such types cause it'll just pollute and clutter the namespace when a simple policy things is easy to do and have same set of features. And anyway, your exampel is faulty, you should ask your user to wait for any type T that is a matrix expression with symmetric features or when you'll call f( a+b*c ); you'll get spurious copy. so the actual generic way to write this should be : template<class T> typename enable_if_c< as_matrix<T>::value && is_same< settings<T,shape>, symmetric>::value >::type f( T const& m ); but we can't have user write that so a small macro thingy will be needed.
because symmetric_matix does not even provide such interface and will not leave user wandering if he missed the key and typed '(10, 19)' with unreadable compiler error somewhere in instantiated templates as far as i know policies can not do this unless it is full specialized and the latter i think is equivalent to a distinct type
You should read and learn about : SFINAE ,boost::enable_if and BOOST_MPL_ASSERT. That's ages that cryptic error messages int empalte are no more. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
First, concrete inheritance like this == bad performances. Use CRTP I'm against the proliferation of such types cause it'll just pollute and clutter the namespace when a simple policy things is easy to do and have same set of features. first, it does use crtp i omitted template parameters for simplicity
And anyway, your exampel is faulty, you should ask your user to wait for any type T that is a matrix expression with symmetric features or when you'll call f( a+b*c ); you'll get spurious copy. so the actual generic way to write this should be : template<class T> typename enable_if_c< as_matrix<T>::value && is_same< settings<T,shape>,symmetric>>::value >::type f( T const& m ); but we can't have user write that so a small macro thingy will be needed. actually since symmetric_matrix uses crtp the user gets just what he
on 17.08.2009 at 17:54 joel wrote : there is no performance degradation probably wants if you supply an actual object it will be passed by reference otherwise the result of an expression will be copied to a temporary and that temorary will be passed by reference (probably that's just what the user needs) finally if the user is advanced, he may write template<typename expression_type> void foo(const symmetric_matrix_expression<expression_type> &m); perfectly readable, typesafe, excellent performance, easy to understand and implement
You should read and learn about : SFINAE ,boost::enable_if and BOOST_MPL_ASSERT. That's ages that cryptic error messages int empalte are no more. just this moment there is a discussion about enable_if issues you might be interested
-- Pavel
DE wrote:
first, it does use crtp i omitted template parameters for simplicity there is no performance degradation
OK then.
if you supply an actual object it will be passed by reference otherwise the result of an expression will be copied to a temporary and that temorary will be passed by reference (probably that's just what the user needs)
It may break user expectancies about performance tough.
finally if the user is advanced, he may write
template<typename expression_type> void foo(const symmetric_matrix_expression<expression_type> &m);
perfectly readable, typesafe, excellent performance, easy to understand and implement
Sure.
just this moment there is a discussion about enable_if issues you might be intereste On the ML ? It's abotu C++0X in GCC4.5 support of partial function template parameters, nothing to worry about.
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
DE wrote:
finally if the user is advanced, he may write template<typename expression_type> void foo(const symmetric_matrix_expression<expression_type> &m);
perfectly readable, typesafe, excellent performance, easy to understand and implement
What if you need a function that, this need, need to pass an expression which is statically allocated or with any other policies on ? You can't decently generate the combinatorial nbr of expression class this way ? -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 17.08.2009 at 20:28 joel wrote :
What if you need a function that, this need, need to pass an expression which is statically allocated or with any other policies on ?
template<typename expression_type> void foo(const matrix_expression<expression_type> &m); //^^this type of expression is the least restrictive it's trivial
You can't decently generate the combinatorial nbr of expression class this way ?
why not? matrix<double> m(3, 3); //dynamically allocated matrix<double, 3, 3> static_m; //statically allocated it's just an example what else? shape? define appropriate types (using CRTP of course!) again, my point is: since you need to implement policies themselves somewhere and their relationship and behavor (possibly by specializing some templates) why not to do that by defining distinct types with proper interfaces? it's a very simple, stable, scalable, easily maintainable design and more: it is easier to understand for users oh and it works also -- Pavel
DE wrote:
matrix<double> m(3, 3); //dynamically allocated matrix<double, 3, 3> static_m; //statically allocated I was speaking of the expression class. I also advice you to not multiply tempalte parameters like that as it quickly becomes hard to maintain.
again, my point is: since you need to implement policies themselves somewhere and their relationship and behavor (possibly by specializing some templates) why not to do that by defining distinct types with proper interfaces?
Because you'll need a combinatorial number of such thing.
it's a very simple, Yes stable, Yes scalable No easily maintainable design
No
and more: it is easier to understand for users
Not more than my solution. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 17.08.2009 at 20:58 joel wrote :
matrix<double> m(3, 3); //dynamically allocated matrix<double, 3, 3> static_m; //statically allocated I was speaking of the expression class. for expression classes only shapes to be concerned: rectangular, symmetric, upper- and lower-triangular what i forgot?
I also advice you to not multiply tempalte parameters like that as it quickly becomes hard to maintain. example?
again, my point is: since you need to implement policies themselves somewhere and their relationship and behavor (possibly by specializing some templates) why not to do that by defining distinct types with proper interfaces? Because you'll need a combinatorial number of such thing. but every unique entity can provide perfectly reasonable interface for just that entity e.g. a sparse matrix can provide non_zero_count() which will return the actual number of stored values furhtermore similar entities may (and must) be factored so there will be no code duplication
it's a very simple, Yes stable, Yes scalable No arguments? easily maintainable design No arguments? and more: it is easier to understand for users Not more than my solution. example?
-- Pavel
DE wrote:
for expression classes only shapes to be concerned: rectangular, symmetric, upper- and lower-triangular what i forgot?
I'm not sure you doesn't want to specialize on other thing. But maybe we can have an hybrid solution : named expression for shape + tempalte policy for the remaining. In the same vein, maybe either to have them be expression<Xpr, diagonal> than diagonal_expression<Xpr> so you can use partial tempalte specialization for matching them 'en masse'
example? Well see the Design rationale for boost::parameters but every unique entity can provide perfectly reasonable interface for just that entity e.g. a sparse matrix can provide non_zero_count() which will return the actual number of stored values furhtermore similar entities may (and must) be factored so there will be no code duplication
Hmm, then we really need soemthign hybrid (CRTP+Policy) CRTP leverage the raw things, Policy specialize them.
arguments?
See earlier but now it's maybe not that much valid -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 17.08.2009 at 21:24 joel wrote : ok i think i finally could explain my point i want to try to start from the beginning to be sure we are talking about the same thing consider following code template<typename expr_type> class mat_expr //general matrix expression { expr_type &ref() { return *(expr_type*)this; } //rude but efficient }; mat : public mat_expr<mat> //CRTP! {//matrix class //we use inheritance to state that 'mat' //specific interface //supports the 'matrix expression' //... //concept (and actually mat 'is-a' template<typename expr> //matrix expression) mat(const mat_expr<expr>&); //<-construct from expression }; template<typename expr1, typename expr2> mat_add_expr<...> operator+( //handle all /*general case*/ const mat_expr<expr1>&, //general const mat_expr<expr2>& //matrix ); //expressions mat_add_expr<...> is an expression that holds operands and performs the operation it inherits from mat_expr<mat_add_expr<...> > (CRTP) cool now we want to extend our type system to handle symmetric matrices efficiently template<typename expr_type> class symm_mat_expr : public mat_expr<expr_type> {}; //well, that's all class symm_mat : public symm_mat_expr<symm_mat> {//symmetric matrix //with appropriate interface template<typename expr> //copy from symmetric symm_mat(const symm_mat_expr<expr>&); //matrix expression, not }; //from general one template<typename expr1, typename expr2> symm_mat_add_expr<...> operator+( /*defining special case*/ const symm_mat_expr<expr1>&, const symm_mat_expr<expr2>& ); symm_mat_add_expr<...> is a full analogy to mat_add_expr<...> now we can write mat m1, m2, m3; symm_mat symm1, symm2, symm3; //... m1 = m2 + m3; //general case m1 = m2 + symm; //fall to general case symm1 = symm2 + symm3; //handled by special case symm1 = m1 + symm2; //hah! won't compile! the latter case won't compile because a sum of general matrix and symmetric matrix is not necessary symmetric rather it's a general matrix compiler helps to ensure this design by its overloading resolution rules i tried to show that this design is easily extendable (doing it in a natural c++ form) i hope this will make sense for you -- Pavel ps i have a crazy thought: matrix<double> typename matrix<double>::sparse typename matrix<double>::symmetric::sparse typename matrix<double>::sparse::symmetric //order doesn't matter //etc. please don't consider it serious!
DE wrote:
on 17.08.2009 at 21:24 joel wrote : ok i think i finally could explain my point
<snip>
Yeah I knwo all of that as I have the exact same thing already except it uses policies ... And well, stop reinventing the wheel and use proto already. your mat_add_expr makes my eyes bleed. For your PS, it's ugly :/ -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 17.08.2009 at 23:41 joel wrote :
Yeah I knwo all of that as I have the exact same thing already except it uses policies ... ok then now i know that we talk about the same thing and consider same lets continue tomorrow
And well, stop reinventing the wheel and use proto already. your mat_add_expr makes my eyes bleed. sorry, i tried to simplify things
by the way an idea to mix concrete types with policies seems good to me i'll try to think about it and could you please write an example of policy implementation of yours? -- Pavel
DE wrote:
by the way an idea to mix concrete types with policies seems good to me i'll try to think about it.
I'll give it a shot too but not yet.
and could you please write an example of policy implementation of yours?
Rutger wrote:
Yes, or provide access to the library already ...
I don't like showing incomplete code. I'll build up a small toy example for policies soon. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
about policies on 18.08.2009 at 0:07 joel wrote :
and could you please write an example of policy implementation of yours?
Rutger wrote:
Yes, or provide access to the library already ... I don't like showing incomplete code. I'll build up a small toy example for policies soon.
since i don't know what a policy concept actualy is i'm going to bla bla a little it'll be convenient i suppose to write matrix<double> m; matrix<double, symmetric> symm; matrix<double, upper_triang> upper_tr; //etc. matrix<double, band|symmetric> band_symm; //etc. implementation: enum mode { general = 0, symmetric = 1<<0, upper_triang = 1<<1, lower_triang = 1<<2, band = 1<<3 //etc. }; template<typename type, mode m = general> class matrix; tempplate<typename type> //explicitly specializing class matrix<type, general> //... //legal combinations of modes {/*...*/}; //providing unique interfaces //to unique entities template<typename type> class matrix<type, symmetric> //... {/*...*/}; template<typename type> class matrix<type, band|symmetric> //... {/*...*/}; //etc. since illegal combinations are not specializaed it will be impossible to instantiate them maybe it's a piece of crap but i can't invent a better one yet -- Pavel
DE wrote:
since i don't know what a policy concept actualy is i'm going to bla bla a little
I'll advise to get a copy of "Modern C++ Design" and read it. Will help you nto reinventing tons of wheel. A better to do that is using the result_of protocol on a settings object so you don't have to bother with order of settings. matrix< type, settings(diagonal, c_indexing)> m; matrix< type, settings(fortran_idnexing, symmetric)> m; -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
I'll advise to get a copy of "Modern C++ Design" and read it. Will help you nto reinventing tons of wheel.
on 20.08.2009 at 20:19 joel wrote : thanks is there a more fresh edition of that book? cause it seems not so modern at this moment
A better to do that is using the result_of protocol on a settings object so you don't have to bother with order of settings. blame me but i don't like such non standard features because they are too tricky (in a bad sense) and not general but as a last resort...
-- Pavel
DE wrote:
is there a more fresh edition of that book? cause it seems not so modern at this moment
OK, at this point, I'm startign to wonder if you're like trolling or something.
blame me but i don't like such non standard features because they are too tricky (in a bad sense) and not general but as a last resort...
yeah sure, that's why boost::result_of is sooooo bad to use. Come on, I like discussion but stating incorrect things like this won't get far. So before dissing stuff you don't know about, learn. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 20.08.2009 at 21:14 joel wrote :
is there a more fresh edition of that book? cause it seems not so modern at this moment OK, at this point, I'm startign to wonder if you're like trolling or something. calm down please! i'm just kidding!
blame me but i don't like such non standard features because they are too tricky (in a bad sense) and not general but as a last resort... yeah sure, that's why boost::result_of is sooooo bad to use. Come on, I like discussion but stating incorrect things like this won't get far. So before dissing stuff you don't know about, learn. i didn't say that it is sooooo bad to use it i just said what i said
returning to policies i ran through pediwikia actually (as now i know what exactly policy means) that was one of the first things that i thought about (though i didn't know that there was a name for it) but publicly inheriting an actual implementation... i do hope there is another way (and trying hard to find out) (a thought: maybe some minor things could be harmlessly implemented right that way, but not whole class implementation) -- Pavel
DE wrote:
actually (as now i know what exactly policy means) that was one of the first things that i thought about (though i didn't know that there was a name for it) but publicly inheriting an actual implementation... i do hope there is another way (and trying hard to find out Wiki example is one of the baddest it may exist. NT2 policy don't use any inheritance, you just ahve to bundle functor/meta-function and other code fragment into each policy and insatnciate them when you need them.
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 20.08.2009 at 21:41 joel wrote :
Wiki example is one of the baddest it may exist. NT2 policy don't use any inheritance, you just ahve to bundle functor/meta-function and other code fragment into each policy and insatnciate them when you need them. (i hope i got it right) but this implementation does not allow to define different interfaces for differently tagged entities, does it?
-- Pavel
DE wrote:
(i hope i got it right) but this implementation does not allow to define different interfaces for differently tagged entities, does it? SFINAE and partial specilization allow this yes.
matrix<double> m; matrix<double, settings( OfSize<4,4> ) > n; m.resize( ofSize(6,6) ); // works n.resize( ofSize(6,6) ); // don't works : no matching function matrix<...>::resize( dimen<N,D> const&) -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
SFINAE and partial specilization allow this yes. matrix<double> m; matrix<double, settings( OfSize<4,4> ) > n; m.resize( ofSize(6,6) ); // works n.resize( ofSize(6,6) ); // don't works : no matching function matrix<...>::resize( dimen<N,D> const&) it'll be cool to not provide illegal parts of interface at all rather
on 20.08.2009 at 21:55 joel wrote : than saying "well, not this time, baby!" it's like a broken promise -- Pavel
DE wrote:
it'll be cool to not provide illegal parts of interface at all rather than saying "well, not this time, baby!" it's like a broken promise OK, so can you tell me if your class A don't have member f() what willt he compiler say ? Answer : the same thing as mine ...
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 20.08.2009 at 22:23 joel wrote :
OK, so can you tell me if your class A don't have member f() what willt he compiler say ? Answer : the same thing as mine ... in fact - yes, absolutely
on the other hand can that mechanism provide additional useful members? such as width() for band matrix (just an example) -- Pavel ps found an excellent copy of 'modern c++ design' (a CHM version) so i'm out for a week...
DE wrote:
on the other hand can that mechanism provide additional useful members? such as width() for band matrix (just an example Members are abd in this kind of code. We should prefer free functions.
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 20.08.2009 at 22:43 joel wrote :
on the other hand can that mechanism provide additional useful members? such as width() for band matrix (just an example Members are abd in this kind of code. We should prefer free functions. hah! smart! defeating me with my own weapon!
but seriosly if considering free functions that will end up with a bunch of friends (which are as bad as member function - or as good as) e.g. count_nonzeros(sparse_instance) would perform terribly -- Pavel
DE wrote:
on 20.08.2009 at 22:57 joel wrote :
e.g. count_nonzeros(sparse_instance) would perform terribly
Why ?
why will it perform terribly? because it attempts to count nonzeros by comparing all elements to zero
You can specialize it ... come on -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
why will it perform terribly? because it attempts to count nonzeros by comparing all elements to zero You can specialize it ... come on
on 20.08.2009 at 23:27 joel wrote : then a whole template must be a friend of another template (to grant access to inner structure) rather poor idea, encapsulation suffers where am i wrong? -- Pavel
DE wrote:
then a whole template must be a friend of another template (to grant access to inner structure) Who talked about friend ??? Those function can be implemented without any friend and so no problem on encapsulation. Time to get coffee for you I think...
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 20.08.2009 at 23:48 joel wrote :
DE wrote:
then a whole template must be a friend of another template (to grant access to inner structure) Who talked about friend ??? Those function can be implemented without any friend and so no problem on encapsulation. Time to get coffee for you I think... it was time to go to bed actually
but since a matrix object provides general interface even for, say, sparse matrix, how a specialization can figure out how it should perform on an object with general interface AND perform efficiently? -- Pavel
i got a thought remember my discussion about hierarchy of expression types in general a more specific expression derives from general expression: template<typename type> class specific_expression : public expression<type> {}; suppose you don't want to abandon policy drived creation of objects like 'object<some_type, specific>' then to provide behavior such that operations on specific objects handle them specifically (yielding specific result) we can provide that policies drive also the type of expression an object belongs to struct default_policy { template<typename type> struct expr { typedef expression<type> type; }; }; struct specific //specific policy { template<typename type> struct expr { typedef specific_expression<type> type; }; }; template<typename some_type, typename policy = default_policy> class object : public typename policy::expr<object<some_type, policy> >::type { //^^CRTP here //interface }; then we can write object<t> o1, o2, o3; o3 = some_op(o1, o2); //using general (not specialized) version //... object<t, specific> s1, s2, s3; s3 = some_op(s1, s2); //using specialized version //... o3 = some_op(o1, s2); //using general version s3 = some_op(s1, o2); //error: can not assign result (general //one) to specific object //(or can - design decision) this is also trivially extended by the (naive) user: class myobject : public specific_expression<myobject> {/*...*/}; //... myobject m; s3 = some_op(m, s2); //still using specialized version although it compiles with msvc80 i don't know if it is portable in general (there could be an issue deriving from dependent type) to joel: #1: all of this, i suppose, can be easily implemented within your policy system (if not yet) #2: do you use CRTP for policies itself? to restrict usages like this: matrix<double, settings( symmetric, 42 ) > m; i think it's a good idea, then settings() becomes something like template<typename p1, typename p2> <resulting_policy_type> settings(policy<p1>, policy<p2>); -- Pavel
DE wrote:
#2: do you use CRTP for policies itself? to restrict usages like this:
matrix<double, settings( symmetric, 42 ) > m;
i think it's a good idea, then settings() becomes something like
template<typename p1, typename p2> <resulting_policy_type> settings(policy<p1>, policy<p2>);
Well, you are aware that the first thign is not even writable as it's nto a valid c++ type. As far from now, I'll refrain posting on this thread as it looks like a discussion for C++.moderated. Come back when you know what you are talking about and when you have a proper implementation to show. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 24.08.2009 at 10:51 joel wrote :
Well, you are aware that the first thign is not even writable as it's nto a valid c++ type. since you don't reveal "what it actually is" of what you mean i'm leaved to guess that thing maybe i'm not able to guess 100% of that and maybe i write the crapiest crap, so what? you leave no other option
As far from now, I'll refrain posting on this thread as it looks like a discussion for C++.moderated. Come back when you know what you are talking about and when you have a proper implementation to show. i don't blame you
-- Pavel
a thought about operations tweaks one may want to tile and/or partially unroll operation loops but since such thing characterize operations rather than objects themselves it is wrong to tag the objects with such info consider matrix<double, tile<3, 3> > tiled1; //the first one //... matrix<double, tile<3, 1> > tiled2; //far from the first one //... matrix<double> result = tiled1*tiled2; //what tiling would occure? instead one can tag an operation itself (when needed) for exmple one could write like matrix<double> result = (m1*m2, tile<3, 3>()); and even m = (m1*m2, tile<3, 3>())*m3; //'m1*m2' is tiled; the latter is not even this primitive form is much more expressive -- Pavel
DE wrote:
a thought about operations tweaks
one may want to tile and/or partially unroll operation loops but since such thing characterize operations rather than objects themselves it is wrong to tag the objects with such info consider
matrix<double, tile<3, 3> > tiled1; //the first one //... matrix<double, tile<3, 1> > tiled2; //far from the first one //... matrix<double> result = tiled1*tiled2; //what tiling would occure In those cases, we compute the smallest common multiple of tiling shape as stated in all loop optimization techniques paper.
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 26.08.2009 at 20:38 joel wrote :
a thought about operations tweaks
one may want to tile and/or partially unroll operation loops but since such thing characterize operations rather than objects themselves it is wrong to tag the objects with such info consider
matrix<double, tile<3, 3> > tiled1; //the first one //... matrix<double, tile<3, 1> > tiled2; //far from the first one //... matrix<double> result = tiled1*tiled2; //what tiling would occure In those cases, we compute the smallest common multiple of tiling shape as stated in all loop optimization techniques paper. i consider it a bad (erroneos) practice because in such a case neither of programmers intentions would take place but something totally different instead
'3' is a common number as well as 'power of 2' in such a common case like matrix<double, tile<32, 32> > t32; //... matrix<double, tile<3, 3> > t3; //maybe in some function //... //intention is to tile 3x3 m = t32*t3; //don't know about func' //parameter tiling according to your words, tiling would not occure at all!!! but that is not the programmer's intention indeed! i would prefer at least one of either tiling (most appropriate) to take place but not that totally different thing -- Pavel
DE wrote:
'3' is a common number as well as 'power of 2' in such a common case like
matrix<double, tile<32, 32> > t32; //... matrix<double, tile<3, 3> > t3; //maybe in some function //... //intention is to tile 3x3 m = t32*t3; //don't know about func' //parameter tiling according to your words, tiling would not occure at all!!!
Learn about : Least Common Multiple first then : http://en.wikipedia.org/wiki/Least_common_multiple it'll tile using a 96x96 tile which will -oh snap- fullfill both requirement.
but that is not the programmer's intention indeed!
Tiling is often done with similar values anyway. Like unrolling, this is a expert-user option and should be used with care if you don't know what you are doing.
i would prefer at least one of either tiling (most appropriate) to take place but not that totally different thing
Except the Least Common Multiple do exactly what it should. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 27.08.2009 at 19:36 joel wrote :
Learn about : Least Common Multiple first then : http://en.wikipedia.org/wiki/Least_common_multiple oops! i always confuse LCM and GCD my fault, i'm sorry
it'll tile using a 96x96 tile which will -oh snap- fullfill both requirement.
but that is not the programmer's intention indeed! Tiling is often done with similar values anyway. Like unrolling, this is a expert-user option and should be used with care if you don't know what you are doing. agree
i would prefer at least one of either tiling (most appropriate) to take place but not that totally different thing Except the Least Common Multiple do exactly what it should. that makes sense
but still i think that these things belong to operations rather than objects -- Pavel
DE wrote:
but still i think that these things belong to operations rather than objects Maybe but it leads to ugly syntax and well, having them on objects and composing them can be solved with simple rules and operations on AST.
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 27.08.2009 at 20:09 joel wrote :
but still i think that these things belong to operations rather than objects Maybe but it leads to ugly syntax and well, having them on objects and composing them can be solved with simple rules and operations on AST. i consider it's, again, a matter of tastes but thanks for listetning to me anyway
-- Pavel

"DE" == DE <satan66613@yandex.ru> writes:
DE> on 26.08.2009 at 20:38 joel wrote : >>> a thought about operations tweaks >>> >>> one may want to tile and/or partially unroll operation loops but >>> since such thing characterize operations rather than objects >>> themselves it is wrong to tag the objects with such info >>> consider >>> >>> matrix<double, tile<3, 3> > tiled1; //the first one //... >>> matrix<double, tile<3, 1> > tiled2; //far from the first one >>> //... matrix<double> result = tiled1*tiled2; //what tiling >>> would occure >> In those cases, we compute the smallest common multiple of tiling >> shape as stated in all loop optimization techniques paper. DE> i consider it a bad (erroneos) practice because in such a case DE> neither of programmers intentions would take place but something DE> totally different instead DE> '3' is a common number as well as 'power of 2' in such a common DE> case like Seems like you're determined to keep this thread alive beyond reason. May I humbly suggest that at least you do the following before posting: - read the text you're answering to - make yourself familiar with the relevant literature Had you done so, you would, maybe, discovered that: - a common multiple is not a common number, although they have common in common. - more, a common multiple of a tiling shape is not even a number (although it can represented by one in R^n). - last, that people have written about this profusely and googling for a few keywords would be a good idea. Other than that, yes, 3 is a rather common number. Not as nice as my personal favourite, 42, though. Best regards, Maurizio
on 27.08.2009 at 19:54 Maurizio Vitale wrote :
Seems like you're determined to keep this thread alive beyond reason. May I humbly suggest that at least you do the following before posting: - read the text you're answering to - make yourself familiar with the relevant literature
Had you done so, you would, maybe, discovered that: - a common multiple is not a common number, although they have common in common. - more, a common multiple of a tiling shape is not even a number (although it can represented by one in R^n). - last, that people have written about this profusely and googling for a few keywords would be a good idea. thanks to your patience to write all this for me i always confuse LCM and GCD sorry for that and sorry for confusing you
i meant a common number in a sense that it is ordinary, natural to use but not that it is a prime (did i get it right?)
Other than that, yes, 3 is a rather common number. Not as nice as my personal favourite, 42, though. consider 23
-- Pavel
on 20.08.2009 at 21:55 joel wrote :
(i hope i got it right) but this implementation does not allow to define different interfaces for differently tagged entities, does it? SFINAE and partial specilization allow this yes. matrix<double> m; matrix<double, settings( OfSize<4,4> ) > n; m.resize( ofSize(6,6) ); // works n.resize( ofSize(6,6) ); // don't works : no matching function matrix<...>::resize( dimen<N,D> const&) another example i think we agreed that a 'symmetry' concept must be handled and as i suppose a symmetric matrix is always square how you would handle such illegal attempts?
matrix<double, settings( symmetric ) > m; m.resize( ofSize(6,7) ); (i just thought: maybe restricting to 'm.resize( ofSize(6) );' ?) -- Pavel
DE wrote:
i think we agreed that a 'symmetry' concept must be handled and as i suppose a symmetric matrix is always square how you would handle such illegal attempts?
matrix<double, settings( symmetric ) > m; m.resize( ofSize(6,7) );
(i just thought: maybe restricting to 'm.resize( ofSize(6) );' ? This throw an exception.
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
i think we agreed that a 'symmetry' concept must be handled and as i suppose a symmetric matrix is always square how you would handle such illegal attempts?
matrix<double, settings( symmetric ) > m; m.resize( ofSize(6,7) );
(i just thought: maybe restricting to 'm.resize( ofSize(6) );' ? This throw an exception.
on 20.08.2009 at 23:46 joel wrote : thus you making available a design violation detection only at run time while it should be detected at compile time since you use additional object for resizing it is easy to provide checking of such violation at compile time -- Pavel
i just want to thank you joel you are a excellent opponent! thanks to you i cleared several things for myself and widened my horizons i hope we'll continue to argue constructively till we come to total agreement or till death! or otherwise till you get bored... -- Pavel
DE wrote:
i just want to thank you joel you are a excellent opponent! thanks to you i cleared several things for myself and widened my horizons
I just hope I don't sound unconstructive or harsh. I like tossing area against each other. You also helped me (see the change from matrix to matrix/vector/table).
i hope we'll continue to argue constructively till we come to total agreement or till death!
I do the same :p
or otherwise till you get bored...
Hahaha, you'll be before me :p -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 17.08.2009 at 21:06 joel wrote :
i just want to thank you joel you are a excellent opponent! thanks to you i cleared several things for myself and widened my horizons I just hope I don't sound unconstructive or harsh. I like tossing area against each other. You also helped me (see the change from matrix to matrix/vector/table). i'm very glad!
i hope we'll continue to argue constructively till we come to total agreement or till death! I do the same :p or otherwise till you get bored... Hahaha, you'll be before me :p give up your hope!
-- Pavel
The more I think about it the less inclined I am towards 'tensors are the one true way'. Since we can ultimately represent everything (conceptually) as matrices it may (perversely) make some sense to treat tensors as a special type of matrix, embuing them with certain properties. This way it keeps the development reasonably sane, works for most of the people all the time and could be extended later. I will ponder that....
on 15.08.2009 at 2:16 Edward Grace wrote : that is exactly my point but once things can change (again) only recently (10..20 years) math literature began to write formulas in matrix notation because people in their average become more educated since e.g. 20 years ago so one day we all can turn faces to tensors -- Pavel
Edward Grace wrote:
Well, semantics I know but they are all tensors. A
scalar -> tensor of order 0, vector -> a tensor of order 1, matrix -> a tensor of order 2. ;-) Ok back to this. I had a discussionw ith my co-worker on this matter and our current code state. Well, in fact, in MATLAB, the concept of LinAlg matrix and of multi-diemnsional container are merged. So now, what about the following class set :
- table : matlab like "matrix" ie container of data that can be N-Dimensions. Only suppot elementwise operations. - vector/covector : reuse table component for memory management + add lin. alg. vector semantic. Can be downcasted to table and table can be explciitly turned into vector/covector baring size macthing. - matrix : ditto 2D lin. alg. object, interact with vector/covector as it should. Supprot algebra algorithm. Can have shape etc ... - tensor : ditto with tensor. Duck typing + CRTP + lightweight CT inheritance make all these interoperable. Leads to nice stuff like : vector * vector = outer product covector * vector = scalar product vector* covector = matrix matrix*vector and covector*matrix are properly optimized etc... What do you htink of this then ? -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 15.08.2009 at 21:25 joel wrote :
Ok back to this. I had a discussionw ith my co-worker on this matter and our current code state. Well, in fact, in MATLAB, the concept of LinAlg matrix and of multi-diemnsional container are merged. So now, what about the following class set :
- table : matlab like "matrix" ie container of data that can be N-Dimensions. Only suppot elementwise operations. - vector/covector : reuse table component for memory management + add lin. alg. vector semantic. Can be downcasted to table and table can be explciitly turned into vector/covector baring size macthing. - matrix : ditto 2D lin. alg. object, interact with vector/covector as it should. Supprot algebra algorithm. Can have shape etc ... - tensor : ditto with tensor.
Duck typing + CRTP + lightweight CT inheritance make all these interoperable.
Leads to nice stuff like :
vector * vector = outer product covector * vector = scalar product vector* covector = matrix matrix*vector and covector*matrix are properly optimized etc...
What do you htink of this then ?
to me it's a lot better now -- Pavel
On 15 Aug 2009, at 18:25, joel wrote:
Edward Grace wrote:
Well, semantics I know but they are all tensors. A
scalar -> tensor of order 0, vector -> a tensor of order 1, matrix -> a tensor of order 2. ;-) Ok back to this. I had a discussionw ith my co-worker on this matter and our current code state. Well, in fact, in MATLAB, the concept of LinAlg matrix and of multi-diemnsional container are merged.
Indeed.
So now, what about the following class set :
- table : matlab like "matrix" ie container of data that can be N-Dimensions. Only suppot elementwise operations.
Ok. Sounds good.
- vector/covector : reuse table component for memory management + add lin. alg. vector semantic. Can be downcasted to table and table can be explciitly turned into vector/covector baring size macthing.
Yes. By 'table -> vector/covector' do you mean in a similar manner to 'reshape' in MATLAB? If so good.
- matrix : ditto 2D lin. alg. object, interact with vector/covector as it should. Supprot algebra algorithm. Can have shape etc ... - tensor : ditto with tensor.
Yes, I think that makes a lot of sense.
Duck typing + CRTP + lightweight CT inheritance make all these interoperable.
Duck typing...... (frantically searches the web)... Hah hah ha!!! I'd never come across that phrase before, very funny. "Quack Quack" or should that be "Coin Coin!"?
Leads to nice stuff like :
vector * vector = outer product
By 'outer product' in the above on the RHS do you mean a matrix or a specific object of type 'outer product' which is aware of its structure? As I mentioned before the outer product thus formed will not have N^2 independent components if the two vectors are of length N. Consequently it could be considered a 'special' type of matrix. As a concrete example, consider the following, operator (x) is outer product, . inner (dot) product, I the identity matrix. this forms a projection operator that, when applied to a vector v (from the left), will project it on to the orthogonal subspace of k - (well I think so, I may have made a boo-boo)! As you can see from the structure of the outer product the number of independent components in P_k is actually a lot smaller than the total size of the formed matrix. However, from a typing point of view, what's the type of Pk - it's clearly not of type 'outer_product'? So, could we write something like: P = 2*(identity(4) - outer_product(k,k)/inner_product(k,k)); so that P ends up being aware of its lack of independent components and acts accordingly? When dealing with small vector spaces (e.g. R^4) this wouldn't matter of course - forming a full dense matrix is probably best however if you are in, say, R^1000 why bother with all the redundant repetition? [that's a joke b.t.w. 'repetition' is redundant]
covector * vector = scalar product
Yep.
vector* covector = matrix
Yep.
matrix*vector and covector*matrix are properly optimized etc...
What do you htink of this then ?
Sounds good to me. When's it finished? ;-) -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
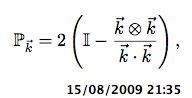{kind=link}
Edward Grace wrote:
Yes. By 'table -> vector/covector' do you mean in a similar manner to 'reshape' in MATLAB? If so good. Yes. Your table has data that can be N-D, when you turn it into a vector, you do somethign akin to v = t(:) in matlab
Leads to nice stuff like :
vector * vector = outer product
By 'outer product' in the above on the RHS do you mean a matrix or a specific object of type 'outer product' which is aware of its structure? [snip] So, could we write something like:
P = 2*(identity(4) - outer_product(k,k)/inner_product(k,k)); [snip]
Ok, I'm maybe dense here, but, can you restate this like I was 4 yo ? What are the "redundant" parts ?
Sounds good to me. When's it finished? ;-) Dunno. I hope soon ;)
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
On 15 Aug 2009, at 21:58, joel wrote:
Edward Grace wrote:
Yes. By 'table -> vector/covector' do you mean in a similar manner to 'reshape' in MATLAB? If so good. Yes. Your table has data that can be N-D, when you turn it into a vector, you do somethign akin to v = t(:) in matlab
Super.
P = 2*(identity(4) - outer_product(k,k)/inner_product(k,k)); [snip]
Ok, I'm maybe dense here, but, can you restate this like I was 4 yo ? What are the "redundant" parts ?
Maybe I'm being a little obscure, you get a symmetric matrix when it's evaluated. Let's just expand it out fully (for a length 3 real vector) v = <a,b,c> assuming that we ignore the inner product and the factor of 2 (scalars). Note that the components above and below the diagonal are the same. In BLAS (or indeed boost::ublas) this would be a matrix of symmetric type (or Hermitian if complex).
Sounds good to me. When's it finished? ;-) Dunno. I hope soon ;)
From my humble experiences, thinking you've finished means you've only just about figured out what the problem actually is! -ed
Edward Grace wrote:
Note that the components above and below the diagonal are the same. In BLAS (or indeed boost::ublas) this would be a matrix of symmetric type (or Hermitian if complex). Ah in this case, we need to look if we can infer the "shape" of the matrix from the AST and then tag the said expression with the proper shape policy. IIRC I have a diag(n) that returns a diagonal matrix with element from the vector n and it was shaped properly. So the engien is here (shaped expression) but we need to be sure at CT that the said matrix has a given property. From my humble experiences, thinking you've finished means you've only just about figured out what the problem actually is! I was half-joking , mind you ;)
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 14.08.2009 at 20:45 joel wrote :
sample 2D code here : http://codepad.org/nDy8z2iG of course this has to be hidden in the implementation. now i get it looks smart and tricky but i don't see any advantages over computed indeces but only wasted spaces and time (for allocating additional storage for pointers) at the same time dereferencing a pointer is like computing an index - no computational advantage again
-- Pavel
DE wrote:
looks smart and tricky but i don't see any advantages over computed indeces but only wasted spaces and time (for allocating additiona storage for pointers)
This si a trade-off. Beware that's only the allocating is slightly slower as the malloc itslef takes more time than the small loop.
at the same time dereferencing a pointer is like computing an index Look at generated assembly and you'll see what happen. At worst it's the same. At best, it replace all the idnex computation by a single LEA on INTEL. Also, it ease writing code that need to deal with multiple idnex.
Index computation with dim > 2 becomes impractical when you ned to do thign like extarcting non rectangular area or doing tile blocking. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 14.08.2009 at 21:32 joel wrote :
looks smart and tricky but i don't see any advantages over computed indeces but only wasted spaces and time (for allocating additiona storage for pointers)
This si a trade-off. Beware that's only the allocating is slightly slower as the malloc itslef takes more time than the small loop.
at the same time dereferencing a pointer is like computing an index Look at generated assembly and you'll see what happen. At worst it's the same. At best, it replace all the idnex computation by a single LEA on INTEL. Also, it ease writing code that need to deal with multiple idnex. for big sizes it might be better i agree
Index computation with dim > 2 becomes impractical when you ned to do thign like extarcting non rectangular area or doing tile blocking. so i guess there should be at least two versions of storages
-- Pavel
DE wrote:
for big sizes it might be better i agree And ofr comple idnexing too. I'll let you as an exercice write the one dimension indexign of a matrix that is tiled in 5x5 blocks and unrolled by a factor 3. so i guess there should be at least two versions of storages
Well, either you let it as a policy or you can use it everytime. The 2D case is the worst case but as benchmarks show, it's only a few percent. There a was a discussion about multi_array months ago where I posted a sample benchmark of this. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 14.08.2009 at 21:56 joel wrote :
for big sizes it might be better i agree And ofr comple idnexing too. I'll let you as an exercice write the one dimension indexign of a matrix that is tiled in 5x5 blocks and unrolled by a factor 3. so i guess there should be at least two versions of storages
Well, either you let it as a policy or you can use it everytime. The 2D case is the worst case but as benchmarks show, it's only a few percent. There a was a discussion about multi_array months ago where I posted a sample benchmark of this. still what about small dynamically alocated entities? i like them very much! i'm afraid about bad performance of them
-- Pavel
DE wrote:
still what about small dynamically alocated entities? i like them very much! i'm afraid about bad performance of the You mean like 4x4 matrix ? In this case, I use static allcoation and guess what :
boost::array< boost::array<T,4>, 4 > acts with the same interface and leads to proper code generation later on. Just specialize when you know your size at CT. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 14.08.2009 at 22:05 joel wrote :
still what about small dynamically alocated entities? i like them very much! i'm afraid about bad performance of the You mean like 4x4 matrix ? In this case, I use static allcoation and guess what : boost::array< boost::array<T,4>, 4 > acts with the same interface and leads to proper code generation later on. Just specialize when you know your size at CT. you might be right i just thought 'why i need arbitrary size _matrix_?' it might turn out there is no such cases
-- Pavel
you might be right. i just thought 'why i need arbitrary size _matrix_?' it might turn out there is no such cases There is. Small matrix like rotation matrix or 3D vector can benefit from a total unrolling of their evaluation. Knowing size of matrix at compile-time opens for a lot of such optimization (tiling, prefethcing, unrolling, strip mining)
DE wrote: that make such a library able to compete with hand written C. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 14.08.2009 at 22:34 joel wrote :
you might be right. i just thought 'why i need arbitrary size _matrix_?' it might turn out there is no such cases There is. Small matrix like rotation matrix or 3D vector can benefit from a total unrolling of their evaluation. Knowing size of matrix at compile-time opens for a lot of such optimization (tiling, prefethcing, unrolling, strip mining) that make such a library able to compete with hand written C. indeed but by the phrase 'arbitrary size' i mean varying at runtime
for 3d rotation one should consider quaterninons - not a matrix and explain please what you mean by unrollin? loop unrolling? so far i suggest separate classes for vector and matrix and a general abstraction for order >2 vector (column) and matrix would have common public interface while less common high order entities would be represented by some tensor<> template or whatever with general interface -- Pavel
DE wrote: > but by the phrase 'arbitrary size' i mean varying at runtime It could. Like you know, loading data from a fiel which size is unkown and can vcary. All those scenarii are valid : * fully dynamic size, dynamic allocation * fully static size, dynamic allocation * fully static size, static allocation > for 3d rotation one should consider quaterninons - not a matrix > We're speaking of users land here. They have the right to choose w/e structure they want. Some API requires you to work with matrix to buidl rotations and except some kind of float** later. > and explain please what you mean by unrollin? loop unrolling? > Yes > so far i suggest separate classes for vector and matrix and a general > abstraction for order >2 > vector (column) and matrix would have common public interface while > less common high order entities would be represented by some tensor<> > template or whatever with general interface I won't discuss this. I have my view on this matter that are given by my own target audience (formar matlab user that want speed). So well, i can just tell you that the less class to manipualte, the happier the users. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
for 3d rotation one should consider quaterninons - not a matrix
We're speaking of users land here. They have the right to choose w/e structure they want. Some API requires you to work with matrix to buidl rotations and except some kind of float** later.
Again - back with my oar. As an aside, quaternions can be *represented* [*] as matrices. In the simpler case, consider a complex number: Z = r*ONE + i*IMAG; where r and i are the scalar real and imaginary components, ONE is the identity 2x2 matrix, 1 0 0 1 and IMAG is the anti-symmetric 2x2 matrix 0 -1 1 0 Conjugating a complex number is identically the same as transposing its matrix representation. Quaternions have a similar isomorphism with 4x4 real matrices. So - and I appreciate this is flirting with absurdity, nothing like making a tricky subject more abstract I guess.... Would it be possible to have entirely abstracted matrices, ones that do not contain any numbers, just rules for their combination (multiplication etc)? For example, if we were to do: abstract_matrix<2> Z; // First template argument is number of dims, second the locations of the +1 elements. Z = 3.0*abstract_symmetric_matrix<2,0>() + 4.0*abstract_antisymmetric_matrix<2,1>(); we would end up with a matrix Z that contains just two independent values (3,4) as before but crucially also contains all the rules for its multiplication so that: double length_squared = Z*transpose(Z); is, for example, an entirely valid operation that reduces to length_squared = 3^2+4^2 and has the type of an abstract_symmetric_matrix<2,0> which is identically castable to a scalar. As another example, the previously quoted: transpose(a)*b outer product when applied to a pair of vectors of length 3 will always result in a matrix with 6 independent components (the same number of degrees of freedom that we started with). The resulting matrix (representing a 2 form) is therefore not a general matrix at all. Therefore when using that resulting matrix why should we use up 9 chunks of memory and repeat calculations when we only need to store 6 and can subsequently reduce the number of calculations. Obviously this is a trivial example, but when the matrix is NxN it can be significant. The parting shot is that if one can see through the layers of abstraction there is a real possibility for building a phenomenally efficient linear algebra library that is practically self aware! -ed [*] Emphasis since I'm trying to invoke the concept of representation theory.
Would it be possible to have entirely abstracted matrices, ones that do not contain any numbers, just rules for their combination (multiplication etc)? For example, if we were to do: abstract_matrix<2> Z; // First template argument is number of dims, second the locations of the +1 elements. Z = 3.0*abstract_symmetric_matrix<2,0>() + 4.0*abstract_antisymmetric_matrix<2,1>(); we would end up with a matrix Z that contains just two independent values (3,4) as before but crucially also contains all the rules for its multiplication so that: double length_squared = Z*transpose(Z); is, for example, an entirely valid operation that reduces to length_squared = 3^2+4^2 and has the type of an abstract_symmetric_matrix<2,0> which is identically castable to a scalar. i think theoretically it's possible since one can compute any computable value thriugh template
on 15.08.2009 at 1:28 Edward Grace wrote : metaprogramming - why not? but i have doubts about profits of all that stuff
As another example, the previously quoted: transpose(a)*b outer product when applied to a pair of vectors of length 3 will always result in a matrix with 6 independent components (the same number of degrees of freedom that we started with). The resulting matrix (representing a 2 form) is therefore not a general matrix at all. Therefore when using that resulting matrix why should we use up 9 chunks of memory and repeat calculations when we only need to store 6 and can subsequently reduce the number of calculations. Obviously this is a trivial example, but when the matrix is NxN it can be significant. The parting shot is that if one can see through the layers of abstraction there is a real possibility for building a phenomenally efficient linear algebra library that is practically self aware! actually, if i got the point right, an implementation might do just what you wrote it doesn't hold the resulting matrix but rather an expression with some rules of computing the elements of resulting matrix
-- Pavel
double length_squared = Z*transpose(Z); is, for example, an entirely valid operation that reduces to length_squared = 3^2+4^2 and has the type of an abstract_symmetric_matrix<2,0> which is identically castable to a scalar. i think theoretically it's possible since one can compute any computable value thriugh template metaprogramming - why not? but i have doubts about profits of all that stuff
Sure. Just because we can doesn't mean we should. Then again, when you look at some of Boost 'because we can' could well be the battle cry! The profits, once the minefield of development is negotiated, may well be surprising and unexpected. It's now been demonstrated that various C++ techniques and deep abstraction not only don't impact performance but can yield excellent performance and vastly improve expressibility. I think, and am sure you agree, expressibility is the number one concern. Being able to write code that is clear and concise under the domain of interest (e.g. linear algebra) is compelling; if it's implemented in a suitable manner high performance will come for free!
significant. The parting shot is that if one can see through the layers of abstraction there is a real possibility for building a phenomenally efficient linear algebra library that is practically self aware! actually, if i got the point right, an implementation might do just what you wrote it doesn't hold the resulting matrix but rather an expression with some rules of computing the elements of resulting matrix
Indeed. Oh, expression templates just got re-invented! ;-) -ed
Edward Grace wrote:
Sure. Just because we can doesn't mean we should. Then again, when you look at some of Boost 'because we can' could well be the battle cry! The profits, once the minefield of development is negotiated, may well be surprising and unexpected. It's now been demonstrated that various C++ techniques and deep abstraction not only don't impact performance but can yield excellent performance and vastly improve expressibility. I think, and am sure you agree, expressibility is the number one concern. Being able to write code that is clear and concise under the domain of interest (e.g. linear algebra) is compelling; if it's implemented in a suitable manner high performance will come for free! Beware of over-engineering. THis kidnof featrues can be added after the core engine works.
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 15.08.2009 at 2:17 Edward Grace wrote :
Sure. Just because we can doesn't mean we should. Then again, when you look at some of Boost 'because we can' could well be the battle cry! The profits, once the minefield of development is negotiated, may well be surprising and unexpected. It's now been demonstrated that various C++ techniques and deep abstraction not only don't impact performance but can yield excellent performance and vastly improve expressibility. I think, and am sure you agree, expressibility is the number one concern. Being able to write code that is clear and concise under the domain of interest (e.g. linear algebra) is compelling; if it's implemented in a suitable manner high performance will come for free! totally agree
-- Pavel
DE wrote:
looks smart and tricky but i don't see any advantages over computed indeces but only wasted spaces and time (for allocating additional storage for pointers) at the same time dereferencing a pointer is like computing an index - no computational advantage agai Back to this issue here is the generated code using
1/ NRC array of dimension 4 mov 0x804c18c,%eax mov %eax,-0x20(%ebp) mov -0x20(%ebp),%eax 1> xor %ebx,%ebx mov (%eax,%edi,1),%eax mov %eax,-0x1c(%ebp) mov -0x1c(%ebp),%eax 2> xor %ecx,%ecx mov (%eax,%ebx,1),%esi mov (%esi,%ecx,1),%eax 3> add $0x4,%ecx mov 0x804c140,%edx cmp $0x8,%ecx mov %edx,(%eax) mov 0x804c140,%edx mov %edx,0x4(%eax) jne 3> add $0x4,%ebx cmp $0x8,%ebx jne 2> add $0x4,%edi cmp $0x8,%edi jne 1> 2/ Same array allocated as a float* with index computation mov %eax,0x804c198 mov %eax,-0x14(%ebp) add $0x40,%eax mov %eax,-0x24(%ebp) mov -0x14(%ebp),%eax 1> xor %esi,%esi mov -0x14(%ebp),%edi add $0x4,%eax mov %eax,-0x18(%ebp) mov -0x18(%ebp),%ecx 2> mov %edi,%ebx xor %edx,%edx mov 0x804c144,%eax 3> add $0x1,%edx mov %eax,(%ebx) mov 0x804c144,%eax add $0x8,%ebx mov %eax,(%ecx) add $0x8,%ecx cmp $0x2,%edx jne 3> add$0x1,%esi add$0x10,%edi addl$0x10,-0x18(%ebp) cmp$0x2,%esi jne 2> addl $0x20,-0x14(%ebp) mov -0x24(%ebp),%eax cmp %eax,-0x14(%ebp) jne 1> Lo and behold ;) Doing the computation of index jump int he allcoation helps tremendously. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 18.08.2009 at 18:59 joel wrote :
DE wrote:
looks smart and tricky but i don't see any advantages over computed indeces but only wasted spaces and time (for allocating additional storage for pointers) at the same time dereferencing a pointer is like computing an index - no computational advantage agai Back to this issue here is the generated code using 1/ NRC array of dimension 4 [code here] Lo and behold ;) Doing the computation of index jump int he allcoation helps tremendously. fewer instructions doesn't mean faster code to find ideal ratio you must take intel arch manual and count the clocks or you can actually measure running time for a variety of cases
i naively (lack of time) implemented nrc (how it is spelled btw?) for 2d case and it performs worse then computed indeces in general i'll try to reimplement it properly and measure again -- Pavel
DE wrote:
fewer instructions doesn't mean faster code Thanks to learn me my job. to find ideal ratio you must take intel arch manual and count the clocks or you can actually measure running time for a variety of cases
Time benchmark is always better. With pipeline in OOCPPU, countign clock in a linear fashion is dumb.
i naively (lack of time) implemented nrc (how it is spelled btw?) for 2d case and it performs worse then computed indeces in general i'll try to reimplement it properly and measure again
It shouldn't. 2D is worse case and perform like only 3-5% less than index. Proper test case is up to 3D. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 18.08.2009 at 20:05 joel wrote :
fewer instructions doesn't mean faster code Thanks to learn me my job. to find ideal ratio you must take intel arch manual and count the clocks or you can actually measure running time for a variety of cases Time benchmark is always better. With pipeline in OOCPPU, countign clock in a linear fashion is dumb. i naively (lack of time) implemented nrc (how it is spelled btw?) for 2d case and it performs worse then computed indeces in general i'll try to reimplement it properly and measure again It shouldn't. 2D is worse case and perform like only 3-5% less than index. Proper test case is up to 3D. ah, ok you might be right (actually i have no chance to prove the contrary)
so why not compute indeces for 2d case and use nrc for N>2? i think it's trivial to implement -- Pavel
DE wrote:
you might be right (actually i have no chance to prove the contrary)
I have a small test code I'm trying to find atm to post.
so why not compute indeces for 2d case and use nrc for N>2? i think it's trivial to implement
Because the loss is so marginal in large computation that I prefer havign an homogeneous allcoation/acces schema. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 18.08.2009 at 20:16 joel wrote :
you might be right (actually i have no chance to prove the contrary)
I have a small test code I'm trying to find atm to post.
so why not compute indeces for 2d case and use nrc for N>2? i think it's trivial to implement
Because the loss is so marginal in large computation that I prefer havign an homogeneous allcoation/acces schema. however there can be benefits (space and time) for small 2d matrices (wich i consider will be a widespread case)
-- Pavel
however there can be benefits (space and time) for small 2d matrices space is irellevant unless working on embedded platform, in which totally different policies are needed. Our work on the CELL show that even there, NRC allocation doesn't
DE wrote: preculde usuability.
(wich i consider will be a widespread case) Define small then. For me, in *my* domain, small matrix are 256*256. Some coworker have small matrix of 10^7 elements ...
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 18.08.2009 at 20:35 joel wrote :
here is the bench program : http://codepad.org/PPN6uRYy what's your score?
-- Pavel
on 18.08.2009 at 21:21 joel wrote :
what's your score Intel Core 2 @ 2Ghz with ubuntu I got something like a difference between -1.43% and +0.9% size?
taking a closer look i'd say this test is not fully representative because you consider only access time regardless of allocation/deallocation effort can you extend it to involve a allocated/deallocated temporary or similar? -- Pavel
DE wrote:
size?
16x16 up to 1024x1024
taking a closer look i'd say this test is not fully representative because you consider only access time regardless of allocation/deallocation effort
In general, what's important is the time I spend computing. allocation/desallocation are done once and has no meaning what so ever w/r to the speed of computation.
can you extend it to involve a allocated/deallocated temporary or similar?
Just add a timer for timing the allocation. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 18.08.2009 at 21:33 joel wrote :
In general, what's important is the time I spend computing. allocation/desallocation are done once and has no meaning what so ever w/r to the speed of computation. arguable
can you extend it to involve a allocated/deallocated temporary or similar? Just add a timer for timing the allocation. i have no boost installed on my machine
-- Pavel
template <typename T> T** alloc_array(int h, int w) { typedef T* ptr_type ; typedef ptr_type* return_type ;
return_type m = new ptr_type[h] ; if (!m) return 0 ; //this is redundant
m[0] = new T[w*h] ; //just to note if new throws 'm' leak if (!m[0]) { delete[] m; return 0 ; }
for (int i=1 ; i < h ; ++i) m[i] = m[i-1] + w ; return m ; }
on 18.08.2009 at 21:33 joel wrote : the redundant line is such because if new fails to allocate memory it throws an exception and control will never reach this line (!m will always be true when checked) the latter i suppose is because of writing on the run -- Pavel
DE wrote:
the redundant line is such because if new fails to allocate memory it throws an exception and control will never reach this line (!m will always be true when checked)
Thansk again for some obvious remark.
the latter i suppose is because of writing on the run
Yes. Actual code use vector anyway as buffer of data. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
On 18 Aug 2009, at 18:21, joel wrote:
DE wrote:
what's your score Intel Core 2 @ 2Ghz with ubuntu I got something like a difference between -1.43% and +0.9%
Hi Joel, Would you mind trying http://www.boostpro.com/vault/index.php? &direction=0&order=&directory=Tools 'ejg-timer-0.0.4.zip' for the comparison? As an aside I'm curious to see if your measured value (presumably no difference) is consistent with this. -ed
I got : Calibrating the clock, for a slow timer this may take a while! Point estimate of clock overhead (t_c): 83.998 Potential jitter on t_c (sigma_c) : 0.0168831 Increasing precision until I can discriminate between function a and b. The nominal confidence interval (minimum, [median], maximum) represents the region: 1-alpha=0.95 Timing at a nominal precision of 50%: We cannot distinguish between A and B: (-2.22045e-14 [-1.11022e-14] 0)% Timing at a nominal precision of 10%: We cannot distinguish between A and B: (-99.9794 [-98.2763] 44.4477)% Timing at a nominal precision of 2%: We cannot distinguish between A and B: (-7.69315 [-4.28203] 1.45846e+06)% Timing at a nominal precision of 0.4%: We cannot distinguish between A and B: (-2.22045e-14 [1.9685] 4.51977)% Timing at a nominal precision of 0.08%: We cannot distinguish between A and B: (-5.22489 [0.0530135] 4.15175)% So what does this means ?
Another run with larger matrix gives : Calibrating the clock, for a slow timer this may take a while! Point estimate of clock overhead (t_c): 155.994 Potential jitter on t_c (sigma_c) : 0.0168831 Increasing precision until I can discriminate between function a and b. The nominal confidence interval (minimum, [median], maximum) represents the region: 1-alpha=0.95 Timing at a nominal precision of 50%: We cannot distinguish between A and B: (-99.9507 [0] 2.22045e-14)% Timing at a nominal precision of 10%: We cannot distinguish between A and B: (-2.22045e-14 [0] 2.22045e-14)% Timing at a nominal precision of 2%: We cannot distinguish between A and B: (-1.11022e-14 [0] 0)% Timing at a nominal precision of 0.4%: A is slower than B by: (-3.16387 [-2.0155] -0.577469)%
Timing at a nominal precision of 0.4%: We cannot distinguish between A and B: (-2.22045e-14 [1.9685] 4.51977)% Timing at a nominal precision of 0.08%: We cannot distinguish between A and B: (-5.22489 [0.0530135] 4.15175)%
So what does this means ?
It means what it says, for the two functions you are timing there is no measurable difference in execution time that cannot be explained by chance. So, if you think A is faster than B or B is faster than A, you are mistaken. The final figure for example, -5.22 --- +4.15, indicates that with a 95% chance the speedup of A relative to B lies between those extremes. Since these extremes clearly include zero you can't say there is a speedup. The best point estimate of the speedup is 0.053% (naff all!). -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Edward Grace wrote:
It means what it says, for the two functions you are timing there is no measurable difference in execution time that cannot be explained by chance. So, if you think A is faster than B or B is faster than A, you are mistaken.
The final figure for example, -5.22 --- +4.15, indicates that with a 95% chance the speedup of A relative to B lies between those extremes. Since these extremes clearly include zero you can't say there is a speedup. The best point estimate of the speedup is 0.053% (naff all!). This means A and B have the same execution time most of the time then ?
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
On 18 Aug 2009, at 19:52, joel wrote:
It means what it says, for the two functions you are timing there is no measurable difference in execution time that cannot be explained by chance. So, if you think A is faster than B or B is faster than A, you are mistaken.
The final figure for example, -5.22 --- +4.15, indicates that with a 95% chance the speedup of A relative to B lies between those extremes. Since these extremes clearly include zero you can't say there is a speedup. The best point estimate of the speedup is 0.053% (naff all!). This means A and B have the same execution time most of the time
Edward Grace wrote: then ?
No, it's more subtle than that. Almost all of the time there will be a difference between A and B, however this difference is just 'noise' around zero. In order for there to be a meaningful difference the natural random variations of the differences should be significantly different from zero. -ed
No, it's more subtle than that. Almost all of the time there will be a difference between A and B, however this difference is just 'noise' around zero. In order for there to be a meaningful difference the natural random variations of the differences should be significantly different from zero. What's the difference between this and "most of the time A and B go at
Edward Grace wrote: the same speed" ? apologize my stats ignorance :) -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
On 18 Aug 2009, at 20:46, joel wrote:
No, it's more subtle than that. Almost all of the time there will be a difference between A and B, however this difference is just 'noise' around zero. In order for there to be a meaningful difference the natural random variations of the differences should be significantly different from zero. What's the difference between this and "most of the time A and B go at
Edward Grace wrote: the same speed" ? apologize my stats ignorance :)
No problem. You are (I think) confusing probability and probability density. If - for the sake of argument and to keep the maths easy - you assume that A and B are both continuous and normally distributed then so will their difference. [In practice neither of these assumptions are true but it doesn't change the basic point.] This normal distribution of the differences will be normal too. This distribution is a probability density - to obtain a probability you must integrate it over a region (dT). http://en.wikipedia.org/wiki/Probability_density_function If that region has zero width then the probability will also be zero. Therefore, the probability that you observe A and B going at the same speed (A-B == 0) is zero. In other words, paraphrasing your comment, "All of the time you will observe A and B do not go at the same speed." [*] That difference however can be an illusion (purely the result of chance). -ed [*] Due to the assumptions above being incorrect this may not be true - the discrete nature of the distribution can lead to differences that are exactly zero. ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
on 18.08.2009 at 18:59 joel wrote :
looks smart and tricky but i don't see any advantages over computed indeces but only wasted spaces and time (for allocating additional storage for pointers) at the same time dereferencing a pointer is like computing an index - no computational advantage agai Back to this issue here is the generated code using 1/ NRC array of dimension 4 [code here] Lo and behold ;) Doing the computation of index jump int he allcoation helps tremendously. i got somewhat unexpected results
i reimplemented 'matrix' in terms of nrc here are results 1. a small mixin to vector operations disadvantage is ~10% - predictable (here by advantage i mean ratio (old_time - nrc_time)/old_time since i assume that nrc would outperform old (non-nrc) code (should be nrc_time<old_time, then ration is >0) if the ratio is negative then it is actually a disadvantage value of ratio is in % for convenience) 2. intensive matrix operations (+-* etc.) advantage is roughly zero - predictable 3. matrix multiplication advantage is roughly zero for best implementation - predictable (see mul.png) 4. matrix inversion (inplace, full pivoting) _advantage_ is ~15% - totally unpredictable (see inv.png) actually it's difficult for me to explain the reason since it implements full pivoting maybe acceleration of the search process defeats the slowness of reducing cycles or maybe i made a mistake however i can explain cases 1-3 disadvantages by the involvement of additional allocation/deallocation and setup process i'm still wondering about the latter case but i consider an invertion such an unwanted corner case and that's why i suggest to implement computed indeces for 2d case however for you, joel, there is nothing to bother since your point is perfectly motivated -- Pavel
{kind=link}
{kind=link}
i got somewhat unexpected results
i reimplemented 'matrix' in terms of nrc here are results
1. a small mixin to vector operations disadvantage is ~10% - predictable (here by advantage i mean ratio (old_time - nrc_time)/old_time since i assume that nrc would outperform old (non-nrc) code (should be nrc_time<old_time, then ration is >0) if the ratio is negative then it is actually a disadvantage value of ratio is in % for convenience)
2. intensive matrix operations (+-* etc.) advantage is roughly zero - predictable
3. matrix multiplication advantage is roughly zero for best implementation - predictable (see mul.png)
4. matrix inversion (inplace, full pivoting) _advantage_ is ~15% - totally unpredictable (see inv.png)
actually it's difficult for me to explain the reason since it implements full pivoting maybe acceleration of the search process defeats the slowness of reducing cycles or maybe i made a mistake
however i can explain cases 1-3 disadvantages by the involvement of additional allocation/deallocation and setup process i'm still wondering about the latter case
but i consider an invertion such an unwanted corner case and that's why i suggest to implement computed indeces for 2d case
however for you, joel, there is nothing to bother since your point is perfectly motivated here is ms excel file
-- Pavel
DE wrote:
i got somewhat unexpected results
Everybody I show that does.
1. a small mixin to vector operations disadvantage is ~10% - predictable (here by advantage i mean ratio (old_time - nrc_time)/old_time since i assume that nrc would outperform old (non-nrc) code (should be nrc_time<old_time, then ration is >0) if the ratio is negative then it is actually a disadvantage value of ratio is in % for convenience)
Hmm for 1D vector, no need for NRC as you have 1D array or am I missing smthg
2. intensive matrix operations (+-* etc.) advantage is roughly zero - predictable
Normal
3. matrix multiplication advantage is roughly zero for best implementation - predictable (see mul.png)
Normal
4. matrix inversion (inplace, full pivoting) _advantage_ is ~15% - totally unpredictable (see inv.png)
actually it's difficult for me to explain the reason since it implements full pivoting maybe acceleration of the search process defeats the slowness of reducing cycles or maybe i made a mistake
You don't trash the cache with index computation. That's the only thing I can see usign cachegrind
however i can explain cases 1-3 disadvantages by the involvement of additional allocation/deallocation and setup process i'm still wondering about the latter case
You're benching alloc/desalloc too ... ??? It makes little sense.
however for you, joel, there is nothing to bother since your point is perfectly motivated
Yup. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 19.08.2009 at 22:15 joel wrote :
Hmm for 1D vector, no need for NRC as you have 1D array or am I missing smthg nrc is only for 2d matrix
however i can explain cases 1-3 disadvantages by the involvement of additional allocation/deallocation and setup process i'm still wondering about the latter case
You're benching alloc/desalloc too ... ??? It makes little sense. benching alloc/dealloc only in cases 1-3 case 4 (inversion) only copies a matrix to temp storage and performs inversion in place like
{ invert(m); } in this case main impact goes from shaking the numbers, not from alloc/dealloc that's a mystery... -- Pavel

-----Original Message----- From: boost-bounces@lists.boost.org [mailto:boost-bounces@lists.boost.org] On Behalf Of joel Sent: 14 August 2009 17:46 To: boost@lists.boost.org Subject: Re: [boost] different matrix library?
You should have one matrix class whose tempalte parameters allow for customization. Want a matrix with static data : matrix<float, settings<static_> >
This is a really good idea - but can appear (and be!) quite complicated - if you want an example of policies and their use, you might like to look at the documentation (and the source code later) of John Maddock's Boost Math Toolkit. In the Math Toolkit, a template parameter allows one to control what happens when a math function call causes trouble - like going to infinity. You can choose to return std::numeric_limits infinity, or max, throw an exception, define your own special policy even, or ignore it completely. All the options have some merit. The most popular is chosen as the default for the math function. If users don't care, or don't understand policies, they get the default - which is hopefully what they wanted anyway. Users still have fine-grained choice that is quite easy to use. The downside is that it badly obscures the source code to readers and is a whole lot of work to implement for the writer. And even more trouble to test - even corner cases mount up horribly. Documenting it takes yet more effort. Finally maintenance later is made more difficult. It may be best to add policies when the code is reasonably stable for what you guess is the default? Good luck. Paul --- Paul A. Bristow Prizet Farmhouse Kendal, UK LA8 8AB +44 1539 561830, mobile +44 7714330204 pbristow@hetp.u-net.com
Paul A. Bristow wrote:
This is a really good idea - but can appear (and be!) quite complicated - if you want an example of policies and their use, you might like to look at the documentation (and the source code later) of John Maddock's Boost Math Toolkit I do something similar. In NT2, the target audience is matlab user with few to no "computer knowledge". So when you go :
matrix<> m; it's a real matlab matrix (2D, contiguous, using double, column first storage). Then you discover you need somethign else, liek using float and have a static storage : matrix<flaot, settings( storage<static_>::OfSize<25,25> ) > m; then a computer savvy guy told you that you're better use dynamic one and turn on unrolling : matrix<float, settings( unroll<8> ) > m; etc ... There is something like 12 policies famillies, all with meaningful default. So the less you know, the less you care.But if you need something, the option is here. Then matrix class is a mere mepty shell that contains a NRC array and tons of meta-functiosn to build itself accrodingly to the policies. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
* separating matrix and vector is a bad idea cause a vector is always a matrix. Moreover, you lead the user to wonder about the "orientation" of the vector. oh and vector indirectly derives from matrix_expression if you ment
on 14.08.2009 at 19:56 Joel Falcou wrote : that so vector is syntactically legal everywhere matrix_expression is legal -- Pavel
on 14.08.2009 at 19:56 Joel Falcou wrote : i meant 'meant' instead of ment damned irregular verbs! -- Pavel
DE wrote:
behold!
i've put my lib in the vault/linalg there are sources as well as documentation (zipped html and CHM file)
if you are interested you might try to use it or even perform some performance testing (would you mind to post results in that case?)
i tried to write documentation so that any user would be able to figure out what's going on and use the lib without difficulties if you'd run through it i hope you get the image of my proposition
any constructive comments are welcome
-- Pavel
Dear Pavel, interesting stuff. Although I think it is promising, what exactly does it have to offer over existing matrix libraries (and uBLAS for that matter)? IMHO, for a next generation C++ linear algebra library to be really successful, I think the following properties are desired * split containers from expressions * split algorithms from expressions, i.e., enable pluggable/customisable back-ends into the expression templates * achieve performance of FORTRAN-based programs (dominant in HPC) What do you think? Kind regards, Rutger
Rutger ter Borg wrote:
IMHO, for a next generation C++ linear algebra library to be really successful, I think the following properties are desired
* split containers from expressions
That's a given no ?
* split algorithms from expressions, i.e., enable pluggable/customisable back-ends into the expression templates
Ultimately, the idea could be to have a way to fall back to BLAS or w/e exists ona given platform when specified.
* achieve performance of FORTRAN-based programs (dominant in HPC)
By handling low level parallelism construct, we can even out perform it. Add also multi-parallel architecture support. Next 10 years will eb full of dense integrated multicores everywhere. So better take time to be prepared for that. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
joel wrote:
That's a given no ?
Stricly speaking, yes, but from a user's point of view I don't think so. Please see my reply to Pavel.
* split algorithms from expressions, i.e., enable pluggable/customisable back-ends into the expression templates
Ultimately, the idea could be to have a way to fall back to BLAS or w/e exists ona given platform when specified.
I would say LAPACK is where the fun starts. Selecting algorithms based on the lowest complexity would be good I guess. One could think of it as a compile-time analytic/semantic preprocessor of an expression.
* achieve performance of FORTRAN-based programs (dominant in HPC)
By handling low level parallelism construct, we can even out perform it.
Add also multi-parallel architecture support. Next 10 years will eb full of dense integrated multicores everywhere. So better take time to be prepared for that.
I would say let's start where they (fortran-based code) are now, and improve from there? I.e., start with plugged BLAS and LAPACK, replace with faster C++ constructs? Cheers, Rutger
Rutger ter Borg wrote:
Stricly speaking, yes, but from a user's point of view I don't think so. Please see my reply to Pavel.
Done and answered ;)
I would say LAPACK is where the fun starts. Selecting algorithms based on the lowest complexity would be good I guess. One could think of it as a compile-time analytic/semantic preprocessor of an expression.
It's what NT2 do.
I would say let's start where they (fortran-based code) are now, and improve from there? I.e., start with plugged BLAS and LAPACK, replace with faster C++ constructs Yes for real tricky stuff (starting with matrix-matrix product). NT2 is for example able to call the proper LAPACK function when doing a*b, a*trans(b), trans(a)*b etc ...
It's really easy to do with proper proto transform for checking composition and generating the proper call. We solved a large part of the interfacing problem by designing a template aware LAPACK bindings (http://lpp.sourceforge.net). -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 16.08.2009 at 23:29 Rutger ter Borg wrote :
Dear Pavel, interesting stuff. Although I think it is promising, what exactly does it have to offer over existing matrix libraries (and uBLAS for that matter)? c++ (read object oriented) handling of entities like
IMHO, for a next generation C++ linear algebra library to be really successful, I think the following properties are desired * split containers from expressions don't get what you mean by that
C = a*A*B + b*C in contrast to uBLAS: C = a*prod(A, B) + b*C //citation from uBLAS docs they are already splitted
* split algorithms from expressions, i.e., enable pluggable/customisable back-ends into the expression templates actually it's rather trivial specialize a template for concrete expression to your taste and you are done
* achieve performance of FORTRAN-based programs (dominant in HPC) that is the hardest part i suppose but i'm sure it is achievable
-- Pavel
DE wrote:
* split containers from expressions don't get what you mean by that they are already splitted
With that I meant that every linear algebra library tends to provide its own implementation of vector and matrix types. Sometimes with different access semantics. One could use std::vector for dense vectors, (unordered) map for sparse vectors/matrices. Perhaps what's missing in the standard containers are matrices? In other words, I would prefer using a traits system to access any container. Suppose if only standard containers were to be used, perhaps let(C) = a*A*B + b*C will be enough to inject template expressions? I've also noted that matrix libraries are usually not exhaustive with their matrix classes. There's all kinds of stuff, like symmetric, triangular, diagonal, banded, bidiagonal, tridiagonal, .... Adaptors / math property wrapper come in handy too, if you have another container which happens to be a symmetric matrix or a symmetric matrix which happens to be positive definite. E.g., suppose A is dense, x = solve( A, b ) x = solve( positive_definite( upper( A ) ), b ) in the second case you say to use the upper triangular part, and make that pos def. in my work for writing a python translator from LAPACK's Fortran source base to C++ bindings code, I've come across the specializations available in LAPACK, that might give a clue for an exhaustive list and write down a good set of orthogonal concepts (e.g., storage traits, structure traits, math properties, etc.).
* split algorithms from expressions, i.e., enable pluggable/customisable back-ends into the expression templates actually it's rather trivial specialize a template for concrete expression to your taste and you are done
Although this sounds good, I think in some cases there will be multiple matches of available algorithms. Then the specialization for the expression with the highest numerical complexity should "win" (assuming the gain is highest there). Is this trivial, too? This would be really neat, I think an entire area of research is writing algorithms for special cases.
* achieve performance of FORTRAN-based programs (dominant in HPC) that is the hardest part i suppose but i'm sure it is achievable
Given the previous point, it's trivial to plug-in BLAS and LAPACK, so plus minus some handling of temporaries, we might already be almost there. What I forgot to mention was error bounds and error propagation. For many users this may be more important than speed. Many algorithms are specialized for this purpose only (same speed, but higher precision). Cheers, Rutger
Rutger ter Borg wrote:
With that I meant that every linear algebra library tends to provide its own implementation of vector and matrix types. Sometimes with different access semantics. One could use std::vector for dense vectors, (unordered) map for sparse vectors/matrices. Perhaps what's missing in the standard containers are matrices? In other words, I would prefer using a traits system to access any container.
Suppose if only standard containers were to be used, perhaps
let(C) = a*A*B + b*C
will be enough to inject template expressions?
NT2 as a as_matrix<T> function std::vector<float> u(100*100); // fill u somehow; matrix<float> r; r = cos(as_matrix(u)) * as_matrix(u); No copy of course of the original vector
I've also noted that matrix libraries are usually not exhaustive with their matrix classes. There's all kinds of stuff, like symmetric, triangular, diagonal, banded, bidiagonal, tridiagonal, .... Adaptors / math property wrapper come in handy too, if you have another container which happens to be a symmetric matrix or a symmetric matrix which happens to be positive definite.
E.g., suppose A is dense,
x = solve( A, b ) x = solve( positive_definite( upper( A ) ), b )
in the second case you say to use the upper triangular part, and make that pos def. in my work for writing a python translator from LAPACK's Fortran source base to C++ bindings code, I've come across the specializations available in LAPACK, that might give a clue for an exhaustive list and write down a good set of orthogonal concepts (e.g., storage traits, structure traits, math properties, etc.).
Policies & lazy-typer. x = solve( as_matrix<settings(positive_definite)>(A), b );
Although this sounds good, I think in some cases there will be multiple matches of available algorithms. Then the specialization for the expression with the highest numerical complexity should "win" (assuming the gain is highest there). Is this trivial, too?
This would be really neat, I think an entire area of research is writing algorithms for special cases.
Introspection on the AST properties of matrix , checking for pattern OR settings usage somewhere. NT2 solve for example is a mapping over the 20+ LAPACK solver and use CT/RT checks to select the best one.
Given the previous point, it's trivial to plug-in BLAS and LAPACK, so plus minus some handling of temporaries, we might already be almost there.
Well, don't forget SIMDifed C is faster than FORTRAN ;)
What I forgot to mention was error bounds and error propagation. For many users this may be more important than speed. Many algorithms are specialized for this purpose only (same speed, but higher precision).
Just drop them in various namespaces. NT2 has plan to have a set of toolbox in which the speed/precision trade-off avry while the base namespace has a middle ground implementation. There is nothing ahrd per se in those, it's just tedious considering the large number of variation. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
joel wrote:
NT2 as a as_matrix<T> function
std::vector<float> u(100*100); // fill u somehow;
matrix<float> r;
r = cos(as_matrix(u)) * as_matrix(u);
No copy of course of the original vector
Nice.
Policies & lazy-typer.
x = solve( as_matrix<settings(positive_definite)>(A), b );
Would it be possible to drop the user-unfriendly stuff? :-) Positive definite alone already implies a vector. x = solve( positive_definite( A ), b ) should do it :-)
Well, don't forget SIMDifed C is faster than FORTRAN ;)
Of course, pick that, then :-) I guess CUBLAS will be faster than SIMD :-)
What I forgot to mention was error bounds and error propagation. For many users this may be more important than speed. Many algorithms are specialized for this purpose only (same speed, but higher precision).
Just drop them in various namespaces. NT2 has plan to have a set of toolbox in which the speed/precision trade-off avry while the base namespace has a middle ground implementation.
Not sure yet.
There is nothing ahrd per se in those, it's just tedious considering the large number of variation.
I see NT2 is under LGPL. Are you considering submitting it for review / changing the license. Suppose in that case I would like to contribute ~60k lines of generated code to glue against (the whole of) BLAS and LAPACK. But, I'm interested in the syntax, first. I think it is probably one of the most important pieces for a user to accept/reject a library. Do you have some documentation on how to write more complex expressions? Cheers, Rutger
Would it be possible to drop the user-unfriendly stuff? :-) Positive definite alone already implies a vector.
x = solve( positive_definite( A ), b )
should do it :-)
We can provide such short-cut of course. as_matrix is needed to apss the complete settings in case like // acces a vector as a diagonal FORTRAN one by lazyly reindex it & reshape it as_matrix<settings(diagonal,FORTRAN_indexing)(v);
Of course, pick that, then :-) I guess CUBLAS will be faster than SIMD :-) I'll tell you this ina bout 8 month when the research project we're running on exactly that is complete.
I see NT2 is under LGPL. Are you considering submitting it for review / changing the license. FYI, v3.x o NT2 (the one on the cooking plant) is using Boost License and not LGPL anymore.
I started by proposing slicing NT2 components into boost library (Boost.SIMD is one). We *will* end up boostifying NT2 and submit it for review but that's a long term goal (read 3-6 months). Currently, our deadline is refurbishing actual code so our own user get an update NT2. Then ONLY after that , we'll do NT2->Boost. Note that I'm really shy on this considering the early response I got from just proposing Boost.SIMD. That's why I also proposed DE to team up so we can brainstorm and don't dilute effort as we already have a huge code base that was working even if it was ugly.
Suppose in that case I would like to contribute ~60k lines of generated code to glue against (the whole of) BLAS and LAPACK.
We have such glue already but sharing/cheking/getting better is of course good.
But, I'm interested in the syntax, first. I think it is probably one of the most important pieces for a user to accept/reject a library. Do you have some documentation on how to write more complex expressions? There is an old documentation (NT2 is beign rewritten form ground up with proto) that show most of what was able at the point on the sourceforge site.
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
joel wrote:
Would it be possible to drop the user-unfriendly stuff? :-) Positive definite alone already implies a vector.
I meant matrix of course
We can provide such short-cut of course. as_matrix is needed to apss the complete settings in case like
// acces a vector as a diagonal FORTRAN one by lazyly reindex it & reshape it as_matrix<settings(diagonal,FORTRAN_indexing)(v);
Of course, pick that, then :-) I guess CUBLAS will be faster than SIMD :-) I'll tell you this ina bout 8 month when the research project we're running on exactly that is complete.
I see NT2 is under LGPL. Are you considering submitting it for review / changing the license. FYI, v3.x o NT2 (the one on the cooking plant) is using Boost License and not LGPL anymore.
I started by proposing slicing NT2 components into boost library (Boost.SIMD is one). We *will* end up boostifying NT2 and submit it for review but that's a long term goal (read 3-6 months). Currently, our deadline is refurbishing actual code so our own user get an update NT2. Then ONLY after that , we'll do NT2->Boost.
Note that I'm really shy on this considering the early response I got from just proposing Boost.SIMD.
That's why I also proposed DE to team up so we can brainstorm and don't dilute effort as we already have a huge code base that was working even if it was ugly.
Let's do that.
We have such glue already but sharing/cheking/getting better is of course good.
I see the glue is yours. The code I'm referring to is at http://svn.boost.org/svn/boost/sandbox/numeric_bindings/boost/numeric/bindin... http://svn.boost.org/svn/boost/sandbox/numeric_bindings/boost/numeric/bindin... it's entirely auto-generated based on the fortran code base, please see http://svn.boost.org/svn/boost/sandbox/numeric_bindings/libs/numeric/binding... so how the code looks and interacts may be adjusted to suit any need. And give you access to algorithms from after 2006 :-)
There is an old documentation (NT2 is beign rewritten form ground up with proto) that show most of what was able at the point on the sourceforge site.
Ok, I'll look into that. Rutger
Rutger ter Borg wrote:
I'm having trouble finding NT2 3.x. Do you have a link? It only exists in our internal SVN server right now. We're working hard to get it out asap. Anyway, it's the exact same set of features except it use proto and better understanding of fusion/MPL and provide an openMP support. Interface is the same except for matrix settings that use round lambda instead of template class.
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
joel wrote:
It only exists in our internal SVN server right now. We're working hard to get it out asap. Anyway, it's the exact same set of features except it use proto and better understanding of fusion/MPL and provide an openMP support. Interface is the same except for matrix settings that use round lambda instead of template class.
Ok. I am looking through the documentation of version 2, there are things I like, and some things to lesser extend, mainly because it tries to mimic Matlab. Have you considered creating a more C++-like domain-specific language, taking elements from various domain-specific languages? Cheers, Rutger
Rutger ter Borg wrote:
Ok. I am looking through the documentation of version 2, there are things I like, and some things to lesser extend, mainly because it tries to mimic Matlab. That's the design rationale of NT2. Main use case is : take a .M, get a .cpp, compile, ???, profit.
Have you considered creating a more C++-like domain-specific language, taking elements from various domain-specific languages?
We started yes. But NT2 is a two men work, so it took times. But in the end, the goal is to have a flexible code base for "optimized computation on N-D table" and plug-in domain-specific interface on top of this. My main research topic is all about that, I just need time+people ;) -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
joel wrote:
Rutger ter Borg wrote:
Ok. I am looking through the documentation of version 2, there are things I like, and some things to lesser extend, mainly because it tries to mimic Matlab. That's the design rationale of NT2. Main use case is : take a .M, get a .cpp, compile, ???, profit.
Doesn't http://www.mathworks.com/products/compiler/ fulfill this purpose? C++ and .m are quite different. My impression is that people at Boost tend to have lengthy discussions about syntax.
We started yes. But NT2 is a two men work, so it took times. But in the end, the goal is to have a flexible code base for "optimized computation on N-D table" and plug-in domain-specific interface on top of this. My main research topic is all about that, I just need time+people ;)
Of course :-) A DSL is not written overnight, either. Perhaps setting up a .qbk in the sandbox would be useful for this purpose? Regards, Rutger
Rutger ter Borg wrote:
Doesn't http://www.mathworks.com/products/compiler/ fulfill this purpose?
When it'll output proper C++ with quality optimization, architectural support, yes. NT2 compiled C++ is uo to 15 faster than this.
C++ and .m are quite different. My impression is that people at Boost tend to have lengthy discussions about syntax.
As I told earlier in this thread, NT2 was designed to help scientist whose main tools was Matlab to port their prototype onto parallel machines. Hence the matlab like syntax. Check what we said we Edward a bit before: C++ user may be able to use a more C++ interface, scientist - which is for me main target audience- won't. So the Matlab interface is something to stay cause no physicist that sometimes don't even know about C++ idioms or lingua will take the time to learn about. They want a tool that allow fast porting of their Matlab or mapple or mathematica prototype. And they don't even want to know about fancy CPU or GPU or clusters. This has to be transparent to us. Matlab is maybe ugly soemtimes but it gets the job done. Me and my coworker had the chance to be right next the users of our library and when I look at the code written with NT2, I maybe can see 1 or 2 that after doign matlab like for pages switch to STL interface cause they need to feed something to a iostream_iterator or w/e. For me, in this case of library design, you have to listen to users, and users want matlab interface. But I have no problem adding another one. NT2 matrix are already stl compliant and in NT2 v3, static matrix are even fusion sequence and support for serialization is planned. Looking like matlab doesn't preclude other interface on top of it. But I won't change the base of this.
Of course :-) A DSL is not written overnight, either. Perhaps setting up a .qbk in the sandbox would be useful for this purpose? You mean ? A tutorial on writting DSL ?
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
joel wrote:
As I told earlier in this thread, NT2 was designed to help scientist whose main tools was Matlab to port their prototype onto parallel machines. Hence the matlab like syntax. Check what we said we Edward a bit before: C++ user may be able to use a more C++ interface, scientist - which is for me main target audience- won't. So the Matlab interface is something to stay cause no physicist that sometimes don't even know about C++ idioms or lingua will take the time to learn about. They want a tool that allow fast porting of their Matlab or mapple or mathematica prototype. And they don't even want to know about fancy CPU or GPU or clusters. This has to be transparent to us. Matlab is maybe ugly soemtimes but it gets the job done. Me and my coworker had the chance to be right next the users of our library and when I look at the code written with NT2, I maybe can see 1 or 2 that after doign matlab like for pages switch to STL interface cause they need to feed something to a iostream_iterator or w/e. For me, in this case of library design, you have to listen to users, and users want matlab interface.
I thought R, http://www.r-project.org/, is a popular tool in science, too. I'm not that convinced a C++ library needs to have a Matlab-like syntax so it can easily understood by users coming from Matlab. A translator would do the trick, too. I'm certainly interested in such a library, but I'm not sure if Boost would be the right forum for it (but let's leave that to the other Boosters).
Of course :-) A DSL is not written overnight, either. Perhaps setting up a .qbk in the sandbox would be useful for this purpose? You mean ? A tutorial on writting DSL ?
Coming up with a DSL-syntax for a C++ linear algebra library. Cheers, Rutger
Rutger ter Borg wrote:
I thought R, http://www.r-project.org/, is a popular tool in science, too.
Yeah, I pondered going this road too.
I'm not that convinced a C++ library needs to have a Matlab-like syntax so it can easily understood by users coming from Matlab. A translator would do the trick, too.
Yes and no. A choice has to be made for the initial interface. We choose matlab at the time because it was convenient for us.
I'm certainly interested in such a library, but I'm not sure if Boost would be the right forum for it (but let's leave that to the other Boosters).
NT2 is living its live outside boost for now. Well, my initial plan was to propose to Boost elements of NT2 that can be reused generically (the SIMD support, memory allocation strategies and the type identification system for example). Now, well, as I said, multiple user interface can coexist anyway so I'm open to suggestion. I'm not tryign to push my design here but well, we spent 5 years on this. I was proposing to reuse this expertise but if the OP or other people want to start from scratch again, well up to you ...
Coming up with a DSL-syntax for a C++ linear algebra library. I don't see why a qbk is neede, can't we discuss this here ?
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
On 17 Aug 2009, at 10:09, Rutger ter Borg wrote:
joel wrote:
It only exists in our internal SVN server right now. We're working hard to get it out asap. Anyway, it's the exact same set of features except it use proto and better understanding of fusion/MPL and provide an openMP support. Interface is the same except for matrix settings that use round lambda instead of template class.
Ok. I am looking through the documentation of version 2, there are things I like, and some things to lesser extend, mainly because it tries to mimic Matlab.
I don't quite understand why you wouldn't want a DSL like MATLAB? After all, MATLAB remember is essentially FORTRAN with different horse shoes, that's why so many scientific / engineering types pick it up so fast - there is very little that's new to learn. For example, alpha(2:10)=alpha(1:9) Is the above MATLAB or FORTRAN? How would you express this in C++ (note the aliasing)? Perhaps alpha(range(2,10))=alpha(range(1,9)); or some-such? How about, vec=mat(:,4) (Again, is that MATLAB or is it FORTRAN?) Presumably something like: vec=matrix_row<matrix<double> >(mat,4); // uBlas style. It's also one of the reasons it's become so successful - well tuned mature libraries (like ATLAS, FFTW) all wrapped up and callable with a simple syntax. I never really develop scientific codes in C++ anymore - it's all pain, no gain! Being able to do x=A\b; % Solve Ax = b to solve a linear algebra problem and be fairly confident that under the hood it's chosen the right routine and is going like the clappers should not be underestimated. FORTRAN syntax is the way it is because of the job it's got to do (scientific computing) - no more - no less.
Have you considered creating a more C++-like domain-specific language, taking elements from various domain-specific languages?
Can you give some examples? If you go and write a whole new paradigm (interface) for linear algebra without at least a nod to it's heritage it will probably be ignored by many of the people who actually *do* it for a living and get used just by hobbyists who enjoy the process rather than the result. (I'm guilty of that myself - hence I'm here). In my humble opinion, for C++ to really take off in next generation scientific applications (believe me I'd love to see it happen), the language should keep out of the way. Ultimately application writers just want the answer - they really don't want to have to figure out how the minutiae of template meta-programming works. Get 'em in the door first with an easy to use intuitive interface -- once they are on board you can break out the hard stuff, then they will be hooked for life! ;-) -ed
I don't quite understand why you wouldn't want a DSL like MATLAB? After all, MATLAB remember is essentially FORTRAN with different horseshoes, that's why so many scientific / engineering types pick it up so fast - there is very little that's new to learn. Exactly For example,
alpha(2:10)=alpha(1:9)
Is the above MATLAB or FORTRAN? How would you express this in C++ (note the aliasing)? Perhaps
alpha(range(2,10))=alpha(range(1,9));
or some-such? How about,
NT2 v3.0 says exactly that : alpha(range(2,10))=alpha(range(1,9));
vec=mat(:,4)
(Again, is that MATLAB or is it FORTRAN?)
Presumably something like:
vec=matrix_row<matrix<double> >(mat,4); // uBlas style.
NT2 v3.0 says : vec=mat(_,4)
In my humble opinion, for C++ to really take off in next generation scientific applications (believe me I'd love to see it happen), the language should keep out of the way. Ultimately application writers just want the answer - they really don't want to have to figure out how the minutiae of template meta-programming works.
Get 'em in the door first with an easy to use intuitive interface -- once they are on board you can break out the hard stuff, then they will be hooked for life! ;-) Massive agreement here :o
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
Edward Grace wrote:
I don't quite understand why you wouldn't want a DSL like MATLAB? After all, MATLAB remember is essentially FORTRAN with different horse shoes, that's why so many scientific / engineering types pick it up so fast - there is very little that's new to learn.
Not saying that I wouldn't want it, saying that perhaps there are some gems in other languages, too. I do not have a Fortran background, but I have to admit that I have used R rather extensively. R/S stuff like A[row(A)==col(A)] <- 2 is easy to use, but does not really match with something like std::fill( diag(A).begin(), diag(A).end(), 2 ); which would perhaps be the C++ way.
For example,
alpha(2:10)=alpha(1:9)
Is the above MATLAB or FORTRAN? How would you express this in C++ (note the aliasing)? Perhaps
alpha(range(2,10))=alpha(range(1,9));
or some-such?
Not sure, but given your example, something like std::rotate( alpha.begin(), alpha.begin()+1, alpha.end() ); :-). I agree the Matlab code is more readable in this case.
How about,
vec=mat(:,4)
(Again, is that MATLAB or is it FORTRAN?)
Are you copying or keeping a reference? Anyway, vec = row(mat,4) vec = diag(mat) etc.
Have you considered creating a more C++-like domain-specific language, taking elements from various domain-specific languages?
Can you give some examples?
E.g., I would prefer x = solve( A, b ) over x = A\b;
If you go and write a whole new paradigm (interface) for linear algebra without at least a nod to it's heritage it will probably be ignored by many of the people who actually *do* it for a living and get used just by hobbyists who enjoy the process rather than the result. (I'm guilty of that myself - hence I'm here).
I'm not after that. I'm just saying that there might be people who actually do stuff in other packages than Matlab (like R et al.). What I also wanted to add is that many (real-life) examples of algorithms do not contain that much linear algebra. I've seen a great deal of .m files which have about 20% linear algebra. About 80% is conditional program flow and bookkeeping stuff. This is where C++ has a clear edge. If we're going to mix them, it should look natural.
In my humble opinion, for C++ to really take off in next generation scientific applications (believe me I'd love to see it happen), the language should keep out of the way. Ultimately application writers just want the answer - they really don't want to have to figure out how the minutiae of template meta-programming works.
Indeed, it should be easy to write. Just as an example, a function "solve" would already cover a large portion of the whole of LAPACK. A DSL for linear algebra does not need to be complex. The more expressiveness, the better, I would say. Cheers, Rutger
on 17.08.2009 at 17:17 Rutger ter Borg wrote :
Indeed, it should be easy to write. Just as an example, a function "solve" would already cover a large portion of the whole of LAPACK. A DSL for linear algebra does not need to be complex. The more expressiveness, the better, I would say.
just to summarize all the discussion above i say that a clear design goes first e.g. "x = solve(A, b);" can be a design statement telling that "the user want to do it that way!" only THEN comes an implementation wich can be whatever you come up with -- Pavel
I don't quite understand why you wouldn't want a DSL like MATLAB? After all, MATLAB remember is essentially FORTRAN with different horse shoes, that's why so many scientific / engineering types pick it up so fast - there is very little that's new to learn.
Not saying that I wouldn't want it, saying that perhaps there are some gems in other languages, too.
Ok, I misunderstood - that I agree with. I like 'breeding' ;-) If you take the best of breeds the animal you can end up with can be so much fitter than the originals. Of course, along the way you might spawn a few freaks too! As I've mentioned to Joel, I don't think a blind carbon copy of MATLAB/FORTRAN-like operation is ultimately what should be done. Learning from the weaknesses and addressing those (e.g. my banging on about tensors) has to be the way forward.
I do not have a Fortran background, but I have to admit that I have used R rather extensively. R/S stuff like
A[row(A)==col(A)] <- 2
Hmm, intriguing.
is easy to use, but does not really match with something like
std::fill( diag(A).begin(), diag(A).end(), 2 );
How about simply A = 2*identity(2);
alpha(range(2,10))=alpha(range(1,9));
or some-such?
Not sure, but given your example, something like
std::rotate( alpha.begin(), alpha.begin()+1, alpha.end() );
Too obscure... Maybe that's what it could map too, but I don't think it's clear. Similarly if you had some other requirement you would end up calling something other than 'rotate' - having a whole bunch of different functions to call based on a subtle indexing change can't be good!
:-). I agree the Matlab code is more readable in this case.
It's actually FORTRAN - (I'm teasing of course - if there were ; s at the end it would have been MATLAB) ;-)
How about,
vec=mat(:,4)
(Again, is that MATLAB or is it FORTRAN?)
Are you copying or keeping a reference?
It could be either. I'm willing to bet that in FORTRAN it will - behind the scenes - pick the best one contingent on what happens next (FORTRAN is always pass by reference for example). Why should the user care as long as they can do vec(1) and get the correct value?
vec = row(mat,4)
Very uBlas (nothing wrong with that). It gets tricker with > 3 dimensions though!
Can you give some examples?
E.g., I would prefer
x = solve( A, b )
over x = A\b;
Sure.
get used just by hobbyists who enjoy the process rather than the result. (I'm guilty of that myself - hence I'm here).
I'm not after that. I'm just saying that there might be people who actually do stuff in other packages than Matlab (like R et al.).
Ok. I agree - 'breeding'!
What I also wanted to add is that many (real-life) examples of algorithms do not contain that much linear algebra.
Usually a single call to 'solve' (in your parlance), in my experience the rest of the code is setting up the problem!
I've seen a great deal of .m files which have about 20% linear algebra. About 80% is conditional program flow and bookkeeping stuff. This is where C++ has a clear edge. If we're going to mix them, it should look natural.
Sure. Most of my above discussion is centred around setting up the problem. For example you need to build some sort of complicated operator (Matrix) to then apply to a state vector. The tricky part is elegantly expressing how to build that - being able to easily refer to subdomains, etc is essential. A concrete example of what I mean is a little function I wrote 'fftnpad' here, http://www.boostpro.com/vault/index.php? direction=0&order=&directory=linalg& this takes an N-dimensional data structure and pads it assuming FFT ordering -- inserting blank space in the middle. In 1D this is trivial, 2D -- ok that's simple enough, how about 4D? (Yes I do occasionally do that). It's conceptually not very difficult but describing the regions you want can be tricky. The secret is the B(tgt{:}) = A(src{:}) at the end which makes life very easy. How would one code this in C++ for example? Give it a bash - it's trickier than it looks (I'm happy for tips to do this better by the way). Perhaps, as a general suggestion, it's worthwhile building a repository of 'gymnastics' such as this in various different languages. That may prove invaluable to people in the future 'breeding' process. -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Edward Grace wrote:
It's conceptually not very difficult but describing the regions you want can be tricky. The secret is the
B(tgt{:}) = A(src{:})
at the end which makes life very easy. How would one code this in C++ for example? Give it a bash - it's trickier than it looks (I'm happy for tips to do this better by the way).
I see B is filled first, and values taken from A later on. In C++, would it make sense to do this assignment inline at the point where you define source and target ranges? Or, by adding (constructing) dimensions to B one at a time once you know what they should contain? For doing assignments, I tend to write functions that set up needed matrices and vectors. Cheers, Rutger
On 17 Aug 2009, at 20:48, DE wrote:
Edward Grace wrote:
It's conceptually not very difficult but describing the regions you want can be tricky. The secret is the
B(tgt{:}) = A(src{:})
at the end which makes life very easy. How would one code this in C++ for example? Give it a bash - it's trickier than it looks (I'm happy for tips to do this better by the way).
I see B is filled first, and values taken from A later on. In C++, would it make sense to do this assignment inline at the point where you define source and target ranges? Or, by adding (constructing) dimensions to B one at a time once you know what they should contain?
Hi Rutger, I'm not sure I understand. Perhaps because, I'm guessing, you don't understand what the B(tgt{:}) = A(src{:}) is doing -- it took me a while to figure out when I first saw it. Can you confirm that you are happy with the following - src on the left tgt on the right? ASCII ART ALERT 1D) (Yes, trivial) +--+--+--+--+ +--+--+--+--+--+--+ |1 |2 |3 |4 | => |1 |2 | | |3 |4 | Two subregions to assign to +--+--+--+--+ +--+--+--+--+--+--+ 2D) (Easy enough...) +--+--+--+--+ +--+--+--+--+--+--+--+ |1 |2 |3 |4 | |1 |2 | | | |3 |4 | +--+--+--+--+ +--+--+--+--+--+--+--+ |5 |6 |7 |8 | => |5 |6 | | | |7 |8 | Four subregions to assign to +--+--+--+--+ +--+--+--+--+--+--+--+ |9 |10|11|12| | | | | | | | | +--+--+--+--+ +--+--+--+--+--+--+--+ |9 |10| | | |11|12| +--+--+--+--+--+--+--+ I won't try and draw the 3D or 4D cases - it's too much work. Suffice to say if you use your imagination, in the 3D case you end up with repeats of the pattern above along the other dimension (out of the screen). In the end the space in the 'middle' of the target cube looks like the cross in [surrealism warning] Salvador Dali's "The Crucifixion". Obviously in the 4D+ case this object is the N- dimensional hyper-crucifix shape. In ND one gets 2^N hypercubes to assign to, the number of subdomains increases exponentially with the number of dimensions. Ultimately of course the actual assignment can be described as a long list of source and target indices assuming the mutidimensional arrays can be flattened in to a single long vector - the equivalent question is, what is the most straightforward way of building this list? I think this is a tricky problem -- while it's possible I'd be interested to see if the code that does the job can be made obvious to understand. The solution I gave in MATLAB, while not as tidy as it could be, is straightforward to code and solves the N-dimensional copy/assignment problem - the secret being the form of the last line. How would *you* do this, elegantly, in C++? That's a genuine question -- I'm curious because, quite frankly, it's foxed me for ages and I would like to do this in C++! ;-) (Hence my suggestion for some sort of assignment / indexing gymnastics resource for people interested in this kind of weirdness) Thanks, -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
Edward Grace wrote:
Hi Rutger,
I'm not sure I understand. Perhaps because, I'm guessing, you don't understand what the
B(tgt{:}) = A(src{:})
is doing -- it took me a while to figure out when I first saw it. Can you confirm that you are happy with the following - src on the left tgt on the right?
I think I understood. Although the statement looks powerful, I think it is a bit of "cheating" because setting up the index vectors tgt and src is done in a loop, by dimension.
How would *you* do this, elegantly, in C++? That's a genuine question -- I'm curious because, quite frankly, it's foxed me for ages and I would like to do this in C++! ;-)
I would say this is a typical example that I would solve by recursion. For the case of a nested std::vector, please see attached. Uncomment lines in main for other dimensions, to see that working. Add some more goodies for sizes and stuff and you're done for any arbitrary nesting and/or dimension of data. Not sure if it is the the most elegant solution, though. Cheers, Rutger
B(tgt{:}) = A(src{:})
is doing -- it took me a while to figure out when I first saw it. Can you confirm that you are happy with the following - src on the left tgt on the right?
I think I understood. Although the statement looks powerful, I think it is a bit of "cheating" because setting up the index vectors tgt and src is done in a loop, by dimension.
I'm not quite sure what you mean by 'cheating' in this context. Do you object to the indirect indexing or the for loop over the dimensions? Please elaborate. What I have in mind for the C++ embodiment of this type of thing is some kind of lazy evaluation of regions of interest (ROIs). Where you can for example 'OR' together dimension regions in a similar manner to constructive solid geometry. For a 2D version of the previous example one would OR together two 1D sub domains along the two different dimensions. This would describe the cross-like structure in the middle. If they were 'AND'ed then it would just be the square section (etc.). A NOT (or equivalently a set difference with the entire structure) would then yield the other part - the disconnected square sections in the corners. Higher dimensions would be identical. The final expression you end up with then only gets concretely evaluated, as and when it's needed, when used to index another expression. So, in this instance, there are no *actual* lists of indices that get calculated. If this can be transformed to a set of contiguous regions in a linear memory view of the arrays then so much the better since the actual copying of the data can be done using something like a low-level memcpy. I don't have sufficiently ninja C++ skills to do this of course!
How would *you* do this, elegantly, in C++? That's a genuine question -- I'm curious because, quite frankly, it's foxed me for ages and I would like to do this in C++! ;-)
I would say this is a typical example that I would solve by recursion. For the case of a nested std::vector, please see attached. Uncomment lines in main for other dimensions, to see that working. Add some more goodies for sizes and stuff and you're done for any arbitrary nesting and/or dimension of data. Not sure if it is the the most elegant solution, though.
Many thanks for 'diving in' to this -- I think it highlights a very different philosophy behind how to approach this problem. Perhaps it is fair to say that the type of (computer) language one uses tends to mould ones approach to given problems. The argument about which is 'simpler' can be left to another day. ;-) -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
about indexing first that comes to my mind is loop cascade like for (... for(... //etc. awful, i know then consider a concept of hyperrange (ND-range) range first(3, 5), second(5, 8); //etc. matrix2d setup; //2d matrix //setting up the setup matrix4d m; //say, 4d matrix m[first][second] = setup; //assign our setup to referenced //hyperrange (here a 2d matrix) don't know if it'll help but seems reasonable to me (i just thought that it's just like slicing) and to setup the 'setup' matrix we are able to write setup[0] = 1, 2, 3; //etc. setup[1] = 4, 5, 6; //note overloaded operator, setup[2] = 7, 8, 9; //etc. actually this has some connection to rutger's earlier code with recursion -- Pavel
about indexin Why no just using matlab extended indexing of a matrix by a cartesian
DE wrote: product of matrix of index ? a(x,y) = ... where x and y are matrix will put the ... in each element a(x(i),y(j)) for all i,j -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 18.08.2009 at 19:51 joel wrote :
Why no just using matlab extended indexing of a matrix by a cartesian product of matrix of index ? a(x,y) = ... where x and y are matrix will put the ... in each element a(x(i),y(j)) for all i,j
i'm not a matlab'ist i'm rather a c++'ist if one can say so i'm not familiar with matlab idioms since that, i consider general cases but not any specific ones from matlab or maple or other by the way i asked a colleague of mine (who is familiar with matlab as well as c++) what syntax does he like more? and he said that he prefers c++ (regardles of performance) so my point is that it's a pure matter of taste -- Pavel
DE wrote:
i'm not a matlab'ist i'm rather a c++'ist if one can say so i'm not familiar with matlab idioms since that, i consider general cases but not any specific ones from matlab or maple or other
by the way i asked a colleague of mine (who is familiar with matlab as well as c++) what syntax does he like more? and he said that he prefers c++ (regardles of performance) so my point is that it's a pure matter of taste
It could be beneficial for the discussion if you weren't ditching stuff all together with not reading what's written. I was porposing to reuse the concept of cartesian product of indexes ... But well, guess your coworker knows better :p -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 18.08.2009 at 20:10 joel wrote :
It could be beneficial for the discussion if you weren't ditching stuff all together with not reading what's written. I was porposing to reuse the concept of cartesian product of indexes ... actually i didn't get the point and so didn't reply to this message
-- Pavel
on 18.08.2009 at 20:10 joel wrote :
It could be beneficial for the discussion if you weren't ditching stuff all together with not reading what's written. I was porposing to reuse the concept of cartesian product of indexes ... sorry for my dumbness i misread your message
it seems reasonable but it can be implemented through non-member function and still be readable even more readable acually set(m, list(x, y), val); or even set(m, list(x, y)) = val; -- Pavel
DE wrote:
it seems reasonable but it can be implemented through non-member function and still be readable even more readable acually
set(m, list(x, y), val);
or even
set(m, list(x, y)) = val how can this be more readable than m(x,y) = val ???
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 18.08.2009 at 20:28 joel wrote :
it seems reasonable but it can be implemented through non-member function and still be readable even more readable acually
set(m, list(x, y), val);
or even
set(m, list(x, y)) = val how can this be more readable than m(x,y) = val ???
set(m)(x, y) = val;//? no? -- Pavel
DE wrote:
on 18.08.2009 at 20:28 joel wrote :
it seems reasonable but it can be implemented through non-member function and still be readable even more readable acually
set(m, list(x, y), val);
or even
set(m, list(x, y)) = val
how can this be more readable than m(x,y) = val ???
set(m)(x, y) = val;//? no?
set is superfluous i think -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
on 19.08.2009 at 21:20 joel wrote :
set(m)(x, y) = val;//? no?
set is superfluous i think yeah but if we continue in same manner we'll end up with overweghted fat disgusting something
and contrary anyone can define a way (to his taste) to fill an entity using complete but compact public interface (here i mean only members) if a funtion can be implemented as nonmember it must be fewer member functions a class have, more incapsulated the data is -- Pavel
i think i've figured out how to provide extesibility for back ends consider 2 ways 1. let operations recognize supported expressions C = a*A*B + b*C; //C = a * prod (A, B) + b * C //from uBLAS docs when parsing we encounter (a*A)*B and an operation yells "i know it! i know it! that's a <some particular operation>! i can do it!" and then introduces compatible templates if needed and fall to back end 2. let evaluating function decide evaluating function recieves an expression which is an AST then it recognizes (or not) particular patterns, introduces templates where appropriate and fall to back end hower this technique is better i suppose because it allows to recognize patterns descently consider C = a*A*B + b*C*D; a pattern is recognized (<a>*<A>*<B> + <1.>*<b*C*D>) and now we need to introduce a temporary for 'b*C*D' and a new pattern appears (scaled product of matrices in this case) either of cases need some templates specializations but in a slightly different manner (i didn't think so for which is harder to implement) -- Pavel
DE wrote:
either of cases need some templates specializations but in a slightly different manner (i didn't think so for which is harder to implement All this is doable with a simpel proto grammar + transform
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
a note on band matrix arithmetic band matrix is square band width is a number of diagonals wich contain numbers band width is always odd (1 main diag + m lower diags + m upper diags) so for a matrix N by N there can be a maximum of (2*n - 1) diagonals (in this case it is an ordinary dense matrix with all diags filled) only equally sized matrices can be involved in operations (+-*) operations on band matrices yield band matrices +- operations on two matrices with bandwidths w1 and w2 evidently yield a band matrix with width = max(w1, w2) multiplication of w1 and w2 widths matrices yields a matrix with width = (w1 + w2 - 1) so i guess there must be a specialization for handling such cases and more: a band matrix can be also symmetric (i don't know yet if this is redundant) -- Pavel
On 19 Aug 2009, at 20:03, joel wrote:
DE wrote:
either of cases need some templates specializations but in a slightly different manner (i didn't think so for which is harder to implement All this is doable with a simpel proto grammar + transform
For extra geek points why not implement an entire algebraic simplification engine to do appropriate vector calculus transforms first [*], http://en.wikipedia.org/wiki/Vector_calculus_identities Like a red rag to a bull! Seriously though, I get the feeling that if one's too clever it will become impossible for the user to know what they are actually doing - therefore a simple expression that would normally be carried out by a single BLAS / LAPACK style library call could end up being de- optimally represented by a set of other calls. -ed [*] My tongue is very firmly in my cheek - I'm not being serious!
on 20.08.2009 at 17:15 Edward Grace wrote :
Seriously though, I get the feeling that if one's too clever it will become impossible for the user to know what they are actually doing - therefore a simple expression that would normally be carried out by a single BLAS / LAPACK style library call could end up being de- optimally represented by a set of other calls. yeah, it might be an issue but that depends on the quality of specific extension in this case actual user can only hope...
-- Pavel
DE wrote:
by the way i asked a colleague of mine (who is familiar with matlab as well as c++) what syntax does he like more? and he said that he prefers c++ (regardles of performance) so my point is that it's a pure matter of taste
Guys, I've looked into GLAS a bit more. Please go read this document of last month, http://www.cs.kuleuven.ac.be/~karlm/glas/tutorial.pdf It supports everything discussed in this thread, and more! It is available on the Internet. It has a Boost community background. Let's stop reinventing the wheel at least three times. Cheers, Rutger
Rutger ter Borg wrote:
It supports everything discussed in this thread, and more! It is available on the Internet. It has a Boost community background. Let's stop reinventing the wheel at least three times Except it has limited functions support, no architectural support. Anyway, let's the OP do what it want anyway. I know I won't dump 4 years of works.
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
joel wrote:
Except it has limited functions support, no architectural support. Anyway, let's the OP do what it want anyway. I know I won't dump 4 years of works.
What do you mean by architectural support? I don't think my suggestion implies that you would have to abandon your entire code base. Cheers, Rutger

On Tue, Aug 18, 2009 at 10:26 PM, Rutger ter Borg<rutger@terborg.net> wrote:
joel wrote:
Except it has limited functions support, no architectural support. Anyway, let's the OP do what it want anyway. I know I won't dump 4 years of works.
What do you mean by architectural support? I don't think my suggestion implies that you would have to abandon your entire code base.
Cheers,
Rutger
Yes, joel could you please give us additional details on what is wrong with GLAS. Moreover, searching for existent lin-alg C++ libraries I've found MTL4 http://www.osl.iu.edu/research/mtl/mtl4/ Its performance makes it very promising http://www.osl.iu.edu/research/mtl/mtl4/doc/performance_athlon.html and it seems it has all the requested features, do you? Cheers, -- Marco
Marco Guazzone wrote:
Yes, joel could you please give us additional details on what is wrong with GLAS.
Its performance makes it very promising Performances is not the problem. All those Expressions Tempaltes
Well, does it generate SIMD code when available, openMP ? MPI code ? address GPU or Cell processor ? Can I tweak the tiling strategy, the unrolling factor of expressions ? What's the added value beside being a E.T based BLAS/LAPACK wrapper ? libraries can't do anythign but get good performances. As I say problem is level of user interface. It's good for C++ savvy people, not for general, common scientist who need to write C++ but dunno a lot about. As i said earlier too, it's a matter of tastes and philosophy so I can't get any arguments out of that. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35

Marco Guazzone wrote:
On Tue, Aug 18, 2009 at 10:26 PM, Rutger ter Borg<rutger@terborg.net> wrote:
joel wrote:
Except it has limited functions support, no architectural support. Anyway, let's the OP do what it want anyway. I know I won't dump 4 years of works.
What do you mean by architectural support? I don't think my suggestion implies that you would have to abandon your entire code base.
Cheers,
Rutger
Yes, joel could you please give us additional details on what is wrong with GLAS.
Moreover, searching for existent lin-alg C++ libraries I've found MTL4
Don't forget about Eigen.
Neal Becker wrote:
Don't forget about Eigen. Eigen's problem is clear : the interface is ugly and over-complicated for the task at hand.
why doing m.row(i) = ... when m(_,i) = .. is possible and do the same thing at same speed. This is an example among other, I already talk about that while discussing boost.SIMD. The Eigen library sells itself at aimed at C++ developper. Again , this is a mistake for a linear algebra library. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
On 18 Aug 2009, at 17:48, Rutger ter Borg wrote:
DE wrote:
by the way i asked a colleague of mine (who is familiar with matlab as well as c++) what syntax does he like more? and he said that he prefers c++ (regardles of performance) so my point is that it's a pure matter of taste
Guys, I've looked into GLAS a bit more. Please go read this document of last month,
http://www.cs.kuleuven.ac.be/~karlm/glas/tutorial.pdf
It supports everything discussed in this thread, and more! It is available on the Internet. It has a Boost community background. Let's stop reinventing the wheel at least three times.
Hah hah, I "Round" "Square" "Elliptical" "Pentagonal" -> Seriously, been done! http://bikehacks.com/china-bike- hack/ I'm just trying to stick my oar in to try and make sure scientists don't get left out in the cold by people developing scientific software... I take some exception to the 'emotional arguments' as the opposition to C++. If the C++ implementation isn't faster [one day I suspect it will be] -- ultimately why should they care? Thanks, -ed ------------------------------------------------ "No more boom and bust." -- Dr. J. G. Brown, 1997
on 18.08.2009 at 20:48 Rutger ter Borg wrote :
Guys, I've looked into GLAS a bit more. Please go read this document of last month,
It supports everything discussed in this thread, and more! It is available on the Internet. It has a Boost community background. Let's stop reinventing the wheel at least three times.
Cheers,
Rutger there are several good stating points
LA toolbox defines operators : [text here] / : Vector divide by scalar: v/a
but this kills me everytime i see it -- Pavel
Rutger ter Borg wrote:
in the second case you say to use the upper triangular part, and make that pos def. in my work for writing a python translator from LAPACK's Fortran source base to C++ bindings code, I've come across the specializations available in LAPACK, that might give a clue for an exhaustive list and write down a good set of orthogonal concepts (e.g., storage traits, structure traits, math properties, etc.).
Missed this part. NT2 has the following concepts as matrix settings. storage mode : conventional (aka dense) and packed (as LAPACK packed) shape : full diagonal, tridiagonal, upper/lower_triangular etc... Note that you can have a diagonal matrix with no packed representation. memory allocation : dynamic or static, dynamic use NRC allocation at runtime, static use NRC allcoation of boost::array dimension : 2D,...,nD Other settings: indexing : numerical value of base idnex. 1 by default to mimic FORTRAN can be set to any signed value (0 = C indexing) All those things are usable as policy types and are checked for non-sensical combination at compile-time. We pondered adding mathematical traits but we foudn no way to enforce them properly without sacrifying performances. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
joel wrote:
Missed this part. NT2 has the following concepts as matrix settings.
storage mode : conventional (aka dense) and packed (as LAPACK packed) shape : full diagonal, tridiagonal, upper/lower_triangular etc... Note that you can have a diagonal matrix with no packed representation. memory allocation : dynamic or static, dynamic use NRC allocation at runtime, static use NRC allcoation of boost::array dimension : 2D,...,nD
Packed Hessenberg? (vector+triangular, or different?) How are banded matrices dealt with?
Other settings: indexing : numerical value of base idnex. 1 by default to mimic FORTRAN can be set to any signed value (0 = C indexing)
All those things are usable as policy types and are checked for non-sensical combination at compile-time.
We pondered adding mathematical traits but we foudn no way to enforce them properly without sacrifying performances.
I would say these are not part of a matrix, rather of the expression? Like unitary and orthogonal? Cheers, Rutger
Rutger ter Borg wrote:
Packed Hessenberg? (vector+triangular, or different?) How are banded matrices dealt with?
Currently in no way. We focused on the one we needed. The extensions can be done for other things.
I would say these are not part of a matrix, rather of the expression? Like unitary and orthogonal? Maybe. That's something we barely touched. Any insight is welcome.
-- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
joel wrote:
Rutger ter Borg wrote:
Packed Hessenberg? (vector+triangular, or different?) How are banded matrices dealt with?
Currently in no way. We focused on the one we needed. The extensions can be done for other things.
I would say these are not part of a matrix, rather of the expression? Like unitary and orthogonal? Maybe. That's something we barely touched. Any insight is welcome.
Maybe if you're able to "add" type-tags to a matrix_expression or something like that? Sorry to keep using the solve example, but say you would have symmetric matrix A, x = solve( A, b ) x = solve( positive_definite( A ), b ) then both expressions in the first argument are matrices, but the second could be identified, e.g., by a meta-function is_positive_definite< expr > which evaluates to a true_type? Cheers, Rutger
Rutger ter Borg wrote:
Maybe if you're able to "add" type-tags to a matrix_expression or something like that? Sorry to keep using the solve example, but say you would have symmetric matrix A,
x = solve( A, b ) x = solve( positive_definite( A ), b )
then both expressions in the first argument are matrices, but the second could be identified, e.g., by a meta-function
is_positive_definite< expr >
which evaluates to a true_type?
Yes. I'll have to find the proper way to add tags in the proto expression I build. If all get worse, I can store a mpl::set of tags in the expression types then have a proto transform that iterate over expression to retrieve the first set tags it founds. This makes solid sense. -- ___________________________________________ Joel Falcou - Assistant Professor PARALL Team - LRI - Universite Paris Sud XI Tel : (+33)1 69 15 66 35
participants (10)
-
 DE
DE -
 dherring@ll.mit.edu
dherring@ll.mit.edu -
 Edward Grace
Edward Grace -
 joel
joel -
Joel Falcou
-
 Marco Guazzone
Marco Guazzone -
 Maurizio Vitale
Maurizio Vitale -
 Neal Becker
Neal Becker -
 Paul A. Bristow
Paul A. Bristow -
 Rutger ter Borg
Rutger ter Borg