
Hi, I just wanted to know if anyone succeeded creating a visualizer for multi_index containers. I'd love to spend some time doing that for the good of the community (and my own, of course :-)), but I could not find any data members for exploration in the debugger's watch window. Any suggestions? See the following blog for more info: http://www.virtualdub.org/blog/pivot/entry.php?id=120 Some info can be found in the autoexp.dat file directly - there are pre-defined visualizers for eg. std::map (which works nice). Thanks, Filip

Filip Konvi?ka ha escrito:
Hi,
I just wanted to know if anyone succeeded creating a visualizer for multi_index containers. I'd love to spend some time doing that for the good of the community (and my own, of course :-)), but I could not find any data members for exploration in the debugger's watch window. Any suggestions?
Hello Filip, I know nothing about VS visualizers so I'm afraid I can't help much on that part, but feel free to ask as much as you need on the internal structures of B.MI --publicly of privately if you feel this is going to be a long list of mails. As for the particular problem you refer to above, please read the following: http://lists.boost.org/boost-users/2007/05/27407.php Does this throw some light on your particular issue? Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
I know nothing about VS visualizers so I'm afraid I can't help much on that part, but feel free to ask as much as you need on the internal structures of B.MI --publicly of privately if you feel this is going to be a long list of mails.
As for the particular problem you refer to above, please read the following:
http://lists.boost.org/boost-users/2007/05/27407.php
Does this throw some light on your particular issue?
Thanks very much, Joaquin, I think that will suffice at the moment, at least until I have more specific questions. Cheers, Filip
Joaquín Mª López Muñoz (23.5.2007 18:16):
Hello Filip,
I know nothing about VS visualizers so I'm afraid I can't help much on that part, but feel free to ask as much as you need on the internal structures of B.MI --publicly of privately if you feel this is going to be a long list of mails. [I tried replying to your email address, but I don't know whether this ever reached you, so I retry here...]
I tried some debugging with multi_index_container<int, indexed_by<sequenced<> > >, which is probably the simplest case. I ended up in the "space" member of "pod_value_holder", which seems to handle some alignment issues and from the name I guess it should also contain the data, but I don't see it in the debugger. As for sequenced_index_node_impl, this shows both _prior and _next, but does not expose node data. See the attached snapshot. Do you have an idea how could I see the one int that I inserted into the container? I think that if we can in the end handle at least sequenced<> indices, it's a huge helper. Thanks very much, Filip
{kind=link}
Hello Filip, I did reply this email last Thursday, I guess somehow it didn't make it to your inbox (??) I'm copying and pasting my answer here again: Filip Konvi?ka ha escrito:
JoaquÃn Mª López Muñoz (23.5.2007 18:16):
Hello Filip,
I know nothing about VS visualizers so I'm afraid I can't help much on that part, but feel free to ask as much as you need on the internal structures of B.MI --publicly of privately if you feel this is going to be a long list of mails. [I tried replying to your email address, but I don't know whether this ever reached you, so I retry here...]
I tried some debugging with multi_index_container<int, indexed_by<sequenced<> > >, which is probably the simplest case. I ended up in the "space" member of "pod_value_holder", which seems to handle some alignment issues and from the name I guess it should also contain the data, but I don't see it in the debugger.
That "space" member is used as raw storage upon which the value (of type int in this case) is constructed. So, you have to reinterpret_cast to get to your value. Does the visualizer allow you to do that?
As for sequenced_index_node_impl, this shows both _prior and _next, but does not expose node data. See the attached snapshot. Do you have an idea how could I see the one int that I inserted into the container?
Nodes of a multi-index container consist of several base classes each providing some part of the whole: the value (index_node_base) and pointers for each of the indices (one sequenced_index_node_impl in this case, as there is only one sequenced index.) In schematic form, the node you're deaing with now has the following structure: struct index_node_base { int value; }; struct sequenced_index_node_impl { sequenced_index_node_impl* prior_; sequenced_index_node_impl* next_; } struct node_type: public index_node_base, public sequenced_index_node_impl { }; So when you navigate through the sequenced index using prior_ and next_ pointers, you've got to down cast to node_type to get to the values. Is it clear (more or less)? Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
Joaquín Mª López Muñoz (28.5.2007 7:49):
Hello Filip, I did reply this email last Thursday, I guess somehow it didn't make it to your inbox (??) I'm copying and pasting my answer here again:
Filip Konvi?ka ha escrito:
JoaquÃn Mª López Muñoz (23.5.2007 18:16):
Hello Filip,
I know nothing about VS visualizers so I'm afraid I can't help much on that part, but feel free to ask as much as you need on the internal structures of B.MI --publicly of privately if you feel this is going to be a long list of mails.
[I tried replying to your email address, but I don't know whether this ever reached you, so I retry here...]
I tried some debugging with multi_index_container<int, indexed_by<sequenced<> > >, which is probably the simplest case. I ended up in the "space" member of "pod_value_holder", which seems to handle some alignment issues and from the name I guess it should also contain the data, but I don't see it in the debugger.
That "space" member is used as raw storage upon which the value (of type int in this case) is constructed. So, you have to reinterpret_cast to get to your value. Does the visualizer allow you to do that?
Yes, but if you look at the screenshot, you see that the space (resp. space.data_.buf) is filled with 0xcd = -51 (i.e. uninitialized) values. If I reinterpret the space member as int, I get 0xcdcdcdcd. So my conclusion is that I'm looking at the "rear" node and I need to go to the prior_ or next_ node, right? So I tried next_, but I got garbage again, but this time it is not 0xcdcdcdcd but something a bit different. I have inserted a "1" into the container, so I'd expect that the buffer contained [0x01 0x00 0x00 0x00]. See screenshot - the expression shown is (sorry :-))) (boost::multi_index::detail::index_node_base<int>*)(&(((*(boost::multi_index::detail::sequenced_index_node_impl*)(&(*(boost::multi_index::detail::sequenced_index_node_trampoline<boost::multi_index::detail::index_node_base<int>
*)(&*(((*(boost::multi_index::detail::header_holder<boost::multi_index::detail::sequenced_index_node<boost::multi_index::detail::index_node_base<int> ,boost::multi_index::multi_index_container<int,boost::multi_index::indexed_by<boost::multi_index::sequenced<boost::multi_index::tag<boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na> ,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na>,std::allocator<int>
*)(&x))).member)))))).next_))
which in short is that the "next_" member from the previous screenshot is cast to boost::multi_index::detail::index_node_base<int>. The int value in the "space" member is 0x003aa06c.
As for sequenced_index_node_impl, this shows both _prior and _next, but does not expose node data. See the attached snapshot. Do you have an idea how could I see the one int that I inserted into the container?
Nodes of a multi-index container consist of several base classes each providing some part of the whole: the value (index_node_base) and pointers for each of the indices (one sequenced_index_node_impl in this case, as there is only one sequenced index.) In schematic form, the node you're deaing with now has the following structure:
struct index_node_base { int value; };
struct sequenced_index_node_impl { sequenced_index_node_impl* prior_; sequenced_index_node_impl* next_; }
struct node_type: public index_node_base, public sequenced_index_node_impl { };
So when you navigate through the sequenced index using prior_ and next_ pointers, you've got to down cast to node_type to get to the values.
Is it clear (more or less)?
Yes, thanks. Cheers, Filip
{kind=link}
Filip Konvi?ka ha escrito:
JoaquÃn Mª López Muñoz (28.5.2007 7:49):
Hello Filip, I did reply this email last Thursday, I guess somehow it didn't make it to your inbox (??) I'm copying and pasting my answer here again:
Filip Konvi?ka ha escrito:
JoaquÃÂn Mê López Muñoz (23.5.2007 18:16):
Hello Filip,
I know nothing about VS visualizers so I'm afraid I can't help much on that part, but feel free to ask as much as you need on the internal structures of B.MI --publicly of privately if you feel this is going to be a long list of mails.
[I tried replying to your email address, but I don't know whether this ever reached you, so I retry here...]
I tried some debugging with multi_index_container<int, indexed_by<sequenced<> > >, which is probably the simplest case. I ended up in the "space" member of "pod_value_holder", which seems to handle some alignment issues and from the name I guess it should also contain the data, but I don't see it in the debugger.
That "space" member is used as raw storage upon which the value (of type int in this case) is constructed. So, you have to reinterpret_cast to get to your value. Does the visualizer allow you to do that?
Yes, but if you look at the screenshot, you see that the space (resp. space.data_.buf) is filled with 0xcd = -51 (i.e. uninitialized) values. If I reinterpret the space member as int, I get 0xcdcdcdcd. So my conclusion is that I'm looking at the "rear" node and I need to go to the prior_ or next_ node, right?
Correct, I call it the "header" node. You must go to some other node to see actual values, right.
So I tried next_, but I got garbage again, but this time it is not 0xcdcdcdcd but something a bit different. I have inserted a "1" into the container, so I'd expect that the buffer contained [0x01 0x00 0x00 0x00].
See screenshot - the expression shown is (sorry :-)))
I'm not 100% sure, but I think you're not getting the casts right --if I'm interpreting the expression correctly, you are applying the following casts to the next_ pointer: a) to boost::multi_index::detail::sequenced_index_node_trampoline< boost::multi_index::detail::index_node_base<int> >* b) to boost::multi_index::detail::sequenced_index_node_impl* c) to boost::multi_index::detail::index_node_base<int>* Is this the sequence of casts you're meaning to apply? If so, I think this is wrong, what you should go thru is: a) to boost::multi_index::detail::sequenced_index_node_trampoline< boost::multi_index::detail::index_node_base<int> >* b) to boost::multi_index::detail::sequenced_index_node< boost::multi_index::detail::index_node_base<int> >* c) to boost::multi_index::detail::index_node_base<int>* That is, if x is of type sequenced_index_node_impl you get to the full node by evaluating: (boost::multi_index::detail::index_node_base<int>*) (boost::multi_index::detail::sequenced_index_node< boost::multi_index::detail::index_node_base<int> >*) (boost::multi_index::detail::sequenced_index_node_trampoline< boost::multi_index::detail::index_node_base<int> >*)x HTH, Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
So I tried next_, but I got garbage again, but this time it is not 0xcdcdcdcd but something a bit different. I have inserted a "1" into the container, so I'd expect that the buffer contained [0x01 0x00 0x00 0x00].
See screenshot - the expression shown is (sorry :-)))
I'm not 100% sure, but I think you're not getting the casts right --if I'm interpreting the expression correctly, you are applying the following casts to the next_ pointer:
a) to boost::multi_index::detail::sequenced_index_node_trampoline< boost::multi_index::detail::index_node_base<int> >* b) to boost::multi_index::detail::sequenced_index_node_impl* c) to boost::multi_index::detail::index_node_base<int>*
Actually, not. I was simply drag&dropping the next_ pointer so that the watch window derived the casts (it needs all explicit template parameters, hence the mpl::na everywhere). The only cast I was doing was the boost::multi_index::detail::index_node_base<int>* cast of the next_ pointer, which, as it seems, is not enough.
That is, if x is of type sequenced_index_node_impl you get to the full node by evaluating:
(boost::multi_index::detail::index_node_base<int>*) (boost::multi_index::detail::sequenced_index_node< boost::multi_index::detail::index_node_base<int> >*) (boost::multi_index::detail::sequenced_index_node_trampoline< boost::multi_index::detail::index_node_base<int> >*)x
When I applied the above-mentioned casts to the next_ pointer, I saw the int!! :-) I even tried substituting "next_" with "next_->next_" and I saw the other elements. The entire watch window expression to view the first element of the container is: (int&)((((*(boost::multi_index::detail::pod_value_holder<int>*)(&*(boost::multi_index::detail::index_node_base<int>*)(boost::multi_index::detail::sequenced_index_node<boost::multi_index::detail::index_node_base<int>
*)(boost::multi_index::detail::sequenced_index_node_trampoline<boost::multi_index::detail::index_node_base<int> *)((*(boost::multi_index::detail::sequenced_index_node_impl*)(boost::multi_index::detail::sequenced_index_node_trampoline<boost::multi_index::detail::index_node_base<int> *)((*(boost::multi_index::detail::header_holder<boost::multi_index::detail::sequenced_index_node<boost::multi_index::detail::index_node_base<int> ,boost::multi_index::multi_index_container<int,boost::multi_index::indexed_by<boost::multi_index::sequenced<boost::multi_index::tag<boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na> ,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na,boost::mpl::na>,std::allocator<int>
*)(&x)).member)).next_)))).space).data_).buf
Thanks for now! Now I'll try to make a visualizer for this container and see if that can be extended to other containers. Cheers, Filip
Thanks for now! Now I'll try to make a visualizer for this container and see if that can be extended to other containers.
OK, here is a visualizer for multi_index_container<T, indexed_by<sequenced<> > >. I have not succeeded in expanding this to other index combinations, as the visualizer does not seem to support "::type" to access typedefs. When I want to access the "member" member of the container, I need to explicitly specify the header_holder template instantiation, which seems impossible, since it takes - as the first argument - an index_node type structure, which seems to be declared as boost::multi_index::detail::multi_index_node_type<Value,IndexSpecifierList,Allocator>::type, but this is not accessible in the visualizer (it does not like the "::type" part). I'm afraid that there's no way around this, but I'll try tomorrow. Cheers, Filip ;------------------------------- ; boost::multi_index_container ; template arguments are: ; item type, indexed_by stuff, allocator ; ; *** to get to the member field: A=((boost::multi_index::detail::header_holder<boost::multi_index::detail::sequenced_index_node<boost::multi_index::detail::index_node_base<$T1> >,boost::multi_index::multi_index_container<$T1,$T2,$T3> >*)&$c)->member ; *** to get to the next_ field: B=(boost::multi_index::detail::sequenced_index_node_impl*)(boost::multi_index::detail::sequenced_index_node_trampoline<boost::multi_index::detail::index_node_base<$T1> >*)(A)->next_ ; *** to get to the node: C=(boost::multi_index::detail::index_node_base<$T1>*)(boost::multi_index::detail::sequenced_index_node<boost::multi_index::detail::index_node_base<$T1> >*)(boost::multi_index::detail::sequenced_index_node_trampoline<boost::multi_index::detail::index_node_base<$T1> >*)(B) ; *** (possibly unsafe?) to get to the value: ($T1&)(C) ;------------------------------- boost::multi_index::multi_index_container<*,*,*>{ preview(#($c.node_count, " items")) children( #( #list ( head : *((boost::multi_index::detail::sequenced_index_node_impl*)(boost::multi_index::detail::sequenced_index_node_trampoline<boost::multi_index::detail::index_node_base<$T1> >*)(((boost::multi_index::detail::header_holder<boost::multi_index::detail::sequenced_index_node<boost::multi_index::detail::index_node_base<$T1> >,boost::multi_index::multi_index_container<$T1,$T2,$T3> >*)&$c)->member)->next_), size : $c.node_count, next : next_ ) : ($T1&)(boost::multi_index::detail::index_node_base<$T1>*)(boost::multi_index::detail::sequenced_index_node<boost::multi_index::detail::index_node_base<$T1> >*)(boost::multi_index::detail::sequenced_index_node_trampoline<boost::multi_index::detail::index_node_base<$T1> >*)(&$e), item count: [$c.node_count], original members: [$c,!] ) ) }
OK, here is a visualizer for multi_index_container<T, indexed_by<sequenced<> > >.
I have not succeeded in expanding this to other index combinations, as the visualizer does not seem to support "::type" to access typedefs. When I want to access the "member" member of the container, I need to explicitly specify the header_holder template instantiation, which seems impossible, since it takes - as the first argument - an index_node type structure, which seems to be declared as boost::multi_index::detail::multi_index_node_type<Value,IndexSpecifierList,Allocator>::type, but this is not accessible in the visualizer (it does not like the "::type" part). I'm afraid that there's no way around this, but I'll try tomorrow. Hm, I succeeded, in a way, in visualizing a indexed_by<sequenced<>, hashed_unique<identity<T> > > container, but with some pointer arithmetics and artificial classes derived from the container class in
the compiled code. I think that I'll abandon the clean solution path for now, as with my current knowledge about autoexp.dat, the visualizer language lacks some important type accessors, nor have I found a way to do sub-patterns, either of which would probably enable proper visualization of a generic multi_index_container. As the visualizer language does not seem to enforce cast safety as C++ does, I thought about using some raw pointer arithmetics to access the nodes / data. I succeeded with the above-mentioned case, but when I changed/added new indices, I was lost (I did not try that much, I admit...). From the "binary" point of view, is there some generic scheme that could be used to access the elements in the container? One can access node_count, but being able to display the list / array of elements would be nice (I don't think that it's necessary to be able to display the tree structure of ordered_unique, for instance), even if there are some additional requirements like that there is a sequenced<> index or that it is even the first of the indices. I was also thinking whether it would be possible to somehow augment the multi_index_container class with some helper structures to help the visualizer, however I don't see how that could be done. Such class could for example contain a linked list of all nodes (like the sequenced<> index does, but this time this would be non-optional and accessible in a type-uniform way). Thanks for any ideas :-) Cheers, Filip

Sub-patterns are done by using independent visualizer patterns for that type. Of course, this isn't always practical when using complex templates. I ran into this problem for ptr_map. I wanted to express ptr_map's underyling std::map<key,void*>, but couldn't because there was no way to include a visualizer just for std::map<key,void*>. How could I possibly convert void* without knowing what it is? My workaround was to display the "keys" in the preview and the "values" in the expansion. If I could've defined a sub-pattern than I could've done the same thing as std::map and show both keys and values in the preview and in expansion. For multi-index the templates are complex enough that I'm not sure you'll be able to separate out the sub-members and express them using a unique visualizer. Maybe. -- Bill --
-----Original Message----- From: boost-users-bounces@lists.boost.org [mailto:boost-users- bounces@lists.boost.org] On Behalf Of Filip Konvicka Sent: Tuesday, May 29, 2007 2:25 AM To: boost-users@lists.boost.org Subject: Re: [Boost-users] [multi_index] MSVS 2005 visualizers?
OK, here is a visualizer for multi_index_container<T, indexed_by<sequenced<> > >.
I have not succeeded in expanding this to other index combinations, as the visualizer does not seem to support "::type" to access typedefs. When I want to access the "member" member of the container, I need to explicitly specify the header_holder template instantiation, which seems impossible, since it takes - as the first argument - an index_node type structure, which seems to be declared as
but this is not accessible in the visualizer (it does not like the "::type" part). I'm afraid that there's no way around this, but I'll try tomorrow. Hm, I succeeded, in a way, in visualizing a indexed_by<sequenced<>, hashed_unique<identity<T> > > container, but with some pointer arithmetics and artificial classes derived from the container class in
boost::multi_index::detail::multi_index_node_type<Value,IndexSpecifierList ,Allocator>::type, the compiled code. I think that I'll abandon the clean solution path for now, as with my current knowledge about autoexp.dat, the visualizer language lacks some important type accessors, nor have I found a way to do sub-patterns, either of which would probably enable proper visualization of a generic multi_index_container.
As the visualizer language does not seem to enforce cast safety as C++ does, I thought about using some raw pointer arithmetics to access the nodes / data. I succeeded with the above-mentioned case, but when I changed/added new indices, I was lost (I did not try that much, I admit...).
From the "binary" point of view, is there some generic scheme that could be used to access the elements in the container? One can access node_count, but being able to display the list / array of elements would be nice (I don't think that it's necessary to be able to display the tree structure of ordered_unique, for instance), even if there are some additional requirements like that there is a sequenced<> index or that it is even the first of the indices.
I was also thinking whether it would be possible to somehow augment the multi_index_container class with some helper structures to help the visualizer, however I don't see how that could be done. Such class could for example contain a linked list of all nodes (like the sequenced<> index does, but this time this would be non-optional and accessible in a type-uniform way).
Thanks for any ideas :-)
Cheers, Filip
_______________________________________________ Boost-users mailing list Boost-users@lists.boost.org http://lists.boost.org/mailman/listinfo.cgi/boost-users
Bill Buklis 29.5.2007 18:56:
Sub-patterns are done by using independent visualizer patterns for that type. Of course, this isn't always practical when using complex templates. I ran into this problem for ptr_map. I wanted to express ptr_map's underyling std::map<key,void*>, but couldn't because there was no way to include a visualizer just for std::map<key,void*>. How could I possibly convert void* without knowing what it is?
Sure, but I needed to pattern-match the watched expression's parent class in this way, which is not possible. The primary pattern in my example was multi_index_container<*,*,*>, and I wanted another match as header_holder<*,*> or something like this. The debugger just can not match the header_holder. The problem is that the pattern matching mechanism works at the most-derived-class level, and the parent classes can not be accessed AFAIK.
My workaround was to display the "keys" in the preview and the "values" in the expansion. If I could've defined a sub-pattern than I could've done the same thing as std::map and show both keys and values in the preview and in expansion.
For multi-index the templates are complex enough that I'm not sure you'll be able to separate out the sub-members and express them using a unique visualizer. Maybe.
All I wanted was a simple list-like view of the members, which is possible with indexed_by<sequenced<> >. So I hoped that there would be a way to (perhaps) utilize the raw store, or something like this... Cheers, Filip
Filip Konvička <filip.konvicka <at> logis.cz> writes: [...]
Hm, I succeeded, in a way, in visualizing a indexed_by<sequenced<>, hashed_unique<identity<T> > > container, but with some pointer arithmetics and artificial classes derived from the container class in the compiled code. I think that I'll abandon the clean solution path for now, as with my current knowledge about autoexp.dat, the visualizer language lacks some important type accessors, nor have I found a way to do sub-patterns, either of which would probably enable proper visualization of a generic multi_index_container.
As the visualizer language does not seem to enforce cast safety as C++ does, I thought about using some raw pointer arithmetics to access the nodes / data. I succeeded with the above-mentioned case, but when I changed/added new indices, I was lost (I did not try that much, I admit...).
Doing the arithmetic blindly is impossible, since each index adds some overhead to the overall node structure. I don't think you can follow this approach.
From the "binary" point of view, is there some generic scheme that could be used to access the elements in the container? One can access node_count, but being able to display the list / array of elements would be nice (I don't think that it's necessary to be able to display the tree structure of ordered_unique, for instance), even if there are some additional requirements like that there is a sequenced<> index or that it is even the first of the indices.
If you don't mind relying on index #0 being a sequenced one, then I think you can do it: the assumption about the first index being sequenced is equivalent to specifying that the type of the header node is of the form: sequenced_index_node<Q>* where Q is some complex type involving the rest of indices as well as the value type (that I call T1 according to your convention when writing the visualizer). You already know how to traverse a sequenced index, but just to document it again, the expression to go from a node n (of a sequenced index) to the following is: (sequenced_index_node<Q>*) (sequenced_index_node_trampoline<Q>*) ((sequenced_index_node_trampoline<Q>*)(n)->next_) As for getting the value, the following will do: *(T1*)(index_node_base<T1>*)n; The beautiful thing about this latter expression is that it does not formally depend on Q, so I think you can implement it in the visualizer, can't you? If you're able to implement this (i.e. visualizing arbitrary multi_index_containers with the only restriction that the first index is sequenced) then maybe we can extend this approach and work out how to eliminate the restriction and handle the cases where the first index is ordered, hashed, or random-access. But let's do the simple thing first. Does this help? Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
Doing the arithmetic blindly is impossible, since each index adds some overhead to the overall node structure. I don't think you can follow this approach.
Yeah, I didn't mean it seriously, it was late night and I was bored from all those debugger complaints, so I just wanted to give it a try in that one specific case.
From the "binary" point of view, is there some generic scheme that could be used to access the elements in the container? One can access node_count, but being able to display the list / array of elements would be nice (I don't think that it's necessary to be able to display the tree structure of ordered_unique, for instance), even if there are some additional requirements like that there is a sequenced<> index or that it is even the first of the indices.
If you don't mind relying on index #0 being a sequenced one, then I think you can do it: the assumption about the first index being sequenced is equivalent to specifying that the type of the header node is of the form:
sequenced_index_node<Q>*
where Q is some complex type involving the rest of indices as well as the value type (that I call T1 according to your convention when writing the visualizer). You already know how to traverse a sequenced index, but just to document it again, the expression to go from a node n (of a sequenced index) to the following is:
(sequenced_index_node<Q>*) (sequenced_index_node_trampoline<Q>*) ((sequenced_index_node_trampoline<Q>*)(n)->next_)
This is OK, but first I need to get the node "n", which seems hard. This is because it is the "member" field of the container, which must be accessed via some down-cast to header_holder<T1, Tx>, and Tx depends on T2, but I can not derive Tx from T2 in the visualizer (I could use some typedefs from multi_index::detail to get Tx, but this is not supported by the debugger). Specifically, given the multi_index_container<*,indexed_by<*>,*> > pattern, I need to cast the container variable to header_holder<sequenced_index_node<Q2> >, multi_index_container<T1,indexed_by<T2>,T3> >, where Q2 is something like sequenced_index_node<hashed_index_node<index_node_base<T1> > >, which I don't know how to construct from T2. [... long thinking ...] So I tried to visualize sequenced_index_node instead of multi_index_container, and I have some progress. I'm doing a cast to sequenced_index_node -> sequenced_index_node_trampoline --> sequenced_index_node_impl to get the head of the list, next items of the list are retrieved by applying ".next_", and a node is displayed by casting sequenced_index_node_impl --> sequenced_index_node_trampoline --> sequenced_index_node. This is a next challenge point. The next cast would be *(int*)(boost::multi_index::detail::index_node_base<int>*), which would show the node data, but I don't know where to get the "int" type now :-) [... long thinking ...] I've come up with a solution that uses some compile-time support to derive a type that can be reached in the visualizer, which in essence enables to display the data. See the attached visualizer & sample code & screenshot. Next, I will try to dispose of the neccessity of clicking through to the "member" field. Thanks very much for support! Cheers, Filip #include <string> #include <boost/multi_index_container.hpp> #include <boost/multi_index/sequenced_index.hpp> #include <boost/multi_index/hashed_index.hpp> #include <boost/multi_index/ordered_index.hpp> using namespace boost::multi_index; using std::wstring; template<typename T> struct multi_index_helper { }; #define VISUALIZE_MULTI_INDEX_CONTAINER(ID, Type) \ typedef \ boost::multi_index::detail::multi_index_node_type< \ Type::value_type, \ Type::index_specifier_type_list, \ std::allocator<Type::value_type> >::type \ VisHelper ## ID; \ template<> \ struct multi_index_helper<VisHelper ## ID> { \ Type::value_type value; \ } struct test { wstring x; test(wchar_t const *str) : x(str) {} bool operator<(test const& other) const { return x<other.x; } }; typedef multi_index_container<test, indexed_by<sequenced<>, ordered_unique<identity<test> > > > cont; VISUALIZE_MULTI_INDEX_CONTAINER(testx, cont); int main() { cont x; x.push_back(test(L"aaa")); x.push_back(test(L"bbb")); return 0; // see screenshot } boost::multi_index::detail::sequenced_index_node<*>{ preview(#("multi_index container node")) children( #( #list ( head : *(((boost::multi_index::detail::sequenced_index_node_impl*)(boost::multi_index::detail::sequenced_index_node_trampoline<$T1>*)&$c)->next_), size : 2, next : next_ ) : *(multi_index_helper<boost::multi_index::detail::sequenced_index_node<$T1> >*)(boost::multi_index::detail::sequenced_index_node<$T1>*)(boost::multi_index::detail::sequenced_index_node_trampoline<$T1>*)(&$e), original members: [$c,!] ) ) } multi_index_helper<*> { preview(#($c.value)) }
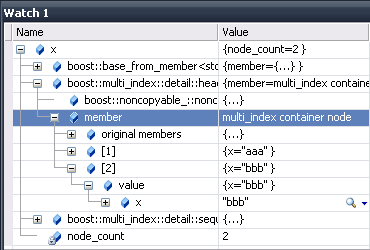{kind=link}
Next, I will try to dispose of the neccessity of clicking through to the "member" field. P.S. I forgot that there is one more limitation - I was not able to retrieve the item count from the node, so the list always displays 2 items (see this constant hardcoded in the visualizer). This is also quite a challenge, see what I can do about it...
F.
Filip Konvi?ka ha escrito: [...]
This is OK, but first I need to get the node "n", which seems hard. This is because it is the "member" field of the container, which must be accessed via some down-cast to header_holder<T1, Tx>, and Tx depends on T2, but I can not derive Tx from T2 in the visualizer (I could use some typedefs from multi_index::detail to get Tx, but this is not supported by the debugger).
Specifically, given the multi_index_container<*,indexed_by<*>,*> > pattern, I need to cast the container variable to
header_holder<sequenced_index_node<Q2> >, multi_index_container<T1,indexed_by<T2>,T3> >,
where Q2 is something like sequenced_index_node<hashed_index_node<index_node_base<T1> > >, which I don't know how to construct from T2.
OK, I think I begin to understand the limitations of the visualizer with respect to type calculation. I think you can circumvent this problem by exercising some hacks similar in spirit to your VISUALIZE_MULTI_INDEX_CONTAINER thing -but less intrusive. Define the following: template<typename Value,typename IndexSpecifierList,typename Allocator> struct header_holder_accessor: private ::boost::base_from_member< typename boost::detail::allocator::rebind_to< Allocator, typename boost::multi_index::detail::multi_index_node_type< Value,IndexSpecifierList,Allocator>::type >::type> { typedef typename boost::multi_index::detail::multi_index_node_type< Value,IndexSpecifierList,Allocator>::type node_type; node_type* value; }; Now you can do the following cast in your visualizer: multi_index_container<T1,T2,T3>* --> header_holder_accessor<T1,T2,T3>* and you get to the header_holder part by applying ".value". Now you can move the rest of the work to a header_holder<Q1,Q2> visualizer. Similarly, if you define template<typename Super> struct sequenced_index_node_value_accessor { typedef typename Super::value_type value_type; value_type value; }; when you're in the sequenced_index_node<T1> visualizer you can do the following cast sequenced_index_node<T1>* --> sequenced_index_node_value_accessor<T1>* and get to the value by applying ".value", which automagically has the right type. Does this help work around the limitations of the visualizer? Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
OK, I think I begin to understand the limitations of the visualizer with respect to type calculation.
This is my first visualizer, too ;-)
I think you can circumvent this problem by exercising some hacks similar in spirit to your VISUALIZE_MULTI_INDEX_CONTAINER thing -but less intrusive. Define the following:
template<typename Value,typename IndexSpecifierList,typename Allocator> struct header_holder_accessor: private ::boost::base_from_member< typename boost::detail::allocator::rebind_to< Allocator, typename boost::multi_index::detail::multi_index_node_type< Value,IndexSpecifierList,Allocator>::type >::type> { typedef typename boost::multi_index::detail::multi_index_node_type< Value,IndexSpecifierList,Allocator>::type node_type;
node_type* value; };
Now you can do the following cast in your visualizer:
multi_index_container<T1,T2,T3>* --> header_holder_accessor<T1,T2,T3>*
and you get to the header_holder part by applying ".value". Now you can move the rest of the work to a header_holder<Q1,Q2> visualizer.
Similarly, if you define
template<typename Super> struct sequenced_index_node_value_accessor { typedef typename Super::value_type value_type; value_type value; };
when you're in the sequenced_index_node<T1> visualizer you can do the following cast
sequenced_index_node<T1>* --> sequenced_index_node_value_accessor<T1>*
and get to the value by applying ".value", which automagically has the right type. Does this help work around the limitations of the visualizer?
Yes, I see we have similar ideas! What did you find intrusive about the macro? The explicit template instantiation is as it seems indispensable, because the debugger can only work with types that are touched (and reported to the debuggger via debug info) by the compiler. This also explains why the debugger does not see type aliases (typedefs, global or local). I did some more experiments last night and today, and I have found a solution that works with any container whose index list starts with sequenced<>. There is a nasty hack which extracts the node count from within a header_holder visualizer (formerly this was a sequenced_index_node visualizer). From my point of view, this is more than I expected that would be possible, thanks very much for your assistance! I'll post the resulting code in a new thread so that it's easier for others to test it or comment on it. Cheers, Filip
... There is a nasty hack which extracts the node count from within a header_holder visualizer (formerly this was a sequenced_index_node visualizer).
I just got rid of this one (it involved some member-pointer arithmetics, ugh, and some static data members, ugh) so it's quite clean now I think. F.
Filip Konvi?ka ha escrito: [...]
Yes, I see we have similar ideas! What did you find intrusive about the macro?
The fact that one needs to do an explicit instantiation to get it working. But I didn't know it was a requirement of the visualizing engine until I read your explanation below. So I guess this is the best we can do. Also, I see that the VISUALIZE_MULTI_INDEX_CONTAINER macro is now cleaner, without the nasty ID parameter.
The explicit template instantiation is as it seems indispensable, because the debugger can only work with types that are touched (and reported to the debuggger via debug info) by the compiler. This also explains why the debugger does not see type aliases (typedefs, global or local).
[...]
From my point of view, this is more than I expected that would be possible, thanks very much for your assistance!
There's an obvious evolution path, namely supporting the rest of node types. Random access should be straightforward, as elements can easily be traversed in a linear fashion much as you're already doing with sequenced nodes --so if you want some clues about that please tell me so. As for the other node types (ordered and hashed) traversal is not that simple, I guess it'd help a lot to see how the built-in visualizers for std::map and stdext::hash_map are doing. Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
There's an obvious evolution path, namely supporting the rest of node types. Random access should be straightforward, as elements can easily be traversed in a linear fashion much as you're already doing with sequenced nodes --so if you want some clues about that please tell me so. As for the other node types (ordered and hashed) traversal is not that simple, I guess it'd help a lot to see how the built-in visualizers for std::map and stdext::hash_map are doing.
The visualizer offers tree traversal: #tree(head:? size:? left:? right:? skip:?) I tried and succeeded partially, with boost::multi_index::detail::header_holder<boost::multi_index::detail::ordered_index_node<*>,*>{ preview(#("multi_index_container data")) children( #( #tree( head : ; the head node (ordered_index_node_compressed_base*) (ordered_index_node_impl*) (ordered_index_node_trampoline<$T1>*) ($c.member), size : ((multi_index_helper_3<$T2>*)&$c)->node_count, left : left_, right : right_, ; skip null nodes skip : 0 ) : ; node formatting *(multi_index_helper<ordered_index_node<$T1> >*) (ordered_index_node<$T1>*) (ordered_index_node_trampoline<$T1>*) (&$e) ) ) } Out of 3 items, I can see the leaf nodes (left_ and right_) correctly, but the head node is displayed incorrectly. When I add some more items, I still see just 2 or 3 items and the rest is garbage. Perhaps there is something about _compressed_base which needs special treatment? BTW, std::map is visualized by #tree ( head : $c._Myhead->_Parent, skip : $c._Myhead, size : $c._Mysize, left : _Left, right : _Right ) : $e._Myval and stdext::hash_map by #list ( head : $c._List._Myhead->_Next, size : $c._List._Mysize, next : _Next ) : $e._Myval Piece of cake :-) Thanks, Filip
Filip Konvi?ka ha escrito: [...]
I guess it'd help a lot to see how the built-in visualizers for std::map and stdext::hash_map are doing.
The visualizer offers tree traversal: #tree(head:? size:? left:? right:? skip:?)
I tried and succeeded partially, with
[...]
Out of 3 items, I can see the leaf nodes (left_ and right_) correctly, but the head node is displayed incorrectly. When I add some more items, I still see just 2 or 3 items and the rest is garbage. Perhaps there is something about _compressed_base which needs special treatment?
Yes, this is related to a special memory-saving technique described at: http://boost.org/libs/multi_index/doc/tutorial/indices.html#ordered_node_com... I cannot check, but I think the correct expression for head should be: *((ordered_index_node_impl*)( ((ordered_index_node_impl*)(ordered_index_node_trampoline<$T1>*)($c.member) )->parentcolor_&~1u)) Does this work? If so, we can move on to the rest of node types :) Joaquín M López Muñoz Telefónica, Investigación y Desarrollo

Hi Filip and Joaquín, Great work!
There's an obvious evolution path, namely supporting the rest of node types.
Please follow it, I need it for my bimaps :) I have tried myself to do this visualizer when this thread started and failed. It is far from trivial, Kudos to tou Filip! Best Regards Matias
Matias Capeletto (31.5.2007 15:48):
Hi Filip and Joaquín,
Great work!
Thanks! The kudos go to Joaquín, his library is excellent! And with such support, it is pleasure to contribute some debugging tools in return.
There's an obvious evolution path, namely supporting the rest of node types.
Please follow it, I need it for my bimaps :)
Sure, I doubt that it would be more complicated than multi_index :-) Cheers, Filip
Out of 3 items, I can see the leaf nodes (left_ and right_) correctly, but the head node is displayed incorrectly. When I add some more items, I still see just 2 or 3 items and the rest is garbage. Perhaps there is something about _compressed_base which needs special treatment?
Yes, this is related to a special memory-saving technique described at:
http://boost.org/libs/multi_index/doc/tutorial/indices.html#ordered_node_com...
I cannot check, but I think the correct expression for head should be:
*((ordered_index_node_impl*)( ((ordered_index_node_impl*)(ordered_index_node_trampoline<$T1>*)($c.member) )->parentcolor_&~1u))
Does this work? If so, we can move on to the rest of node types :)
Yes!! Wow, that was way simpler than I expected. The resulting visualizer works perfectly with the support code that I posted earlier: boost::multi_index::detail::header_holder<boost::multi_index::detail::ordered_index_node<*>,*>{ preview(#("multi_index_container data")) children( #( #tree( head : *(boost::multi_index::detail::ordered_index_node_compressed_base*)(boost::multi_index::detail::ordered_index_node_impl*)(void*)(((boost::multi_index::detail::ordered_index_node_trampoline<$T1>*)($c.member))->parentcolor_&~1U), size : ((multi_index_helper_3<$T2>*)&$c)->node_count, left : left_, right : right_, skip : 0 ) : *(multi_index_helper<boost::multi_index::detail::ordered_index_node<$T1>
*)(boost::multi_index::detail::ordered_index_node<$T1>*)(boost::multi_index::detail::ordered_index_node_trampoline<$T1>*)(&$e) ) ) }
(The visualizer needs all the boost::multi_index::detail:: specification stuff...) I tried hashed_unique right away, and I have another issue: boost::multi_index::detail::header_holder<boost::multi_index::detail::hashed_index_node<*>,*>{ preview(#("multi_index_container hashed data")) children( #( orig : [$c,!], #list( head : *((hashed_index_node_impl*)(hashed_index_node_trampoline<$T1>*)($c.member)), size : ((multi_index_helper_3<$T2>*)((header_holder<hashed_index_node<$T1>,$T2>*)(((char*)&$c)+4)))->node_count, next : next_ ) : *(multi_index_helper<hashed_index_node<$T1>
*)(hashed_index_node<$T1>*)(hashed_index_node_trampoline<$T1>*)(&$e) ) ) }
It seems that accessing node_count using the same technique as with ordered_unique does not work - I'm off by 4 bytes (see the (((char*)&$c)+4) expression). Clicking through the head node's next_ members reveals that I'm cycling between just 2 nodes (there should be 5 of them), and the data is garbage. So perhaps I'm missing some additional cast somewhere, but I don't see where. There is one more issue with hashed indices: the type names tend to get so long, that when I use more than one index with hashed_unique, the name gets cut in the half (some fixed string length...) and fails to match the pattern (there're loads of boost::mpl::na or something like this). If there's no compiler flag to set, this will probably be a limitation. Cheers, Filip
Filip Konvička <filip.konvicka <at> logis.cz> writes: [...]
I tried hashed_unique right away, and I have another issue:
boost::multi_index::detail::header_holder<boost::multi_index::detail::hashed_in dex_node<*>,*>{
preview(#("multi_index_container hashed data")) children( #( orig : [$c,!], #list( head : *((hashed_index_node_impl*)(hashed_index_node_trampoline<$T1>*)($c.member)), size : ((multi_index_helper_3<$T2>*)((header_holder<hashed_index_node<$T1>,$T2>*) (((char*)&$c)+4)))->node_count, next : next_ ) : *(multi_index_helper<hashed_index_node<$T1>
*)(hashed_index_node<$T1>*)(hashed_index_node_trampoline<$T1>*)(&$e) ) ) }
It seems that accessing node_count using the same technique as with ordered_unique does not work - I'm off by 4 bytes (see the (((char*)&$c)+4) expression).
I've examined this carefully and I can't see how the offset should be needed. What's the value the visualizer shows without the offset, i.e. when using the following expression? size : ((multi_index_helper_3<$T2>*)&$c)->node_count
Clicking through the head node's next_ members reveals that I'm cycling between just 2 nodes (there should be 5 of them), and the data is garbage. So perhaps I'm missing some additional cast somewhere, but I don't see where.
I'm afraid traversing a hashed index is no easy chore. There are two popular implementation techniques for TR1 unordered containers and related data structures (prestandard hash_sets and such): a) As a single doubly linked lists of elements. b) As several singly linked lists, one for each nonempty bucket. (for more info on this subject, see section F of http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2003/n1443.html ) With a), which is what Dinkumware's stdext::hash_* containers use, traversing the elements is exactly equivalent to doing so with an std::list, hence the simple visualizer code for stdext::hash_map you brought in here yesterday. With b), however, traversing all elements implies the following: 1. Going to the beginning of the hashed index's bucket array (which is not the header node), whose elements points to the corresponding associated element lists. 2. For each nonempty bucket, traverse the associated list. 3. When finished with a bucket, hop through the bucket array to the next nonempty bucket. In particular, note that the header here, unlike in ordered and sequenced indices, cannot be used as the starting point for the traversal journey. Do you think the visualizer is powerful enough to run this algorithm? If so, I can provide you with more details to begin writing the stuff. Random access indices are also harder than ordered and sequenced, but I think it should be far simpler to support them than hashed indices. Please ping me if you're willing to crack that one.
There is one more issue with hashed indices: the type names tend to get so long, that when I use more than one index with hashed_unique, the name gets cut in the half (some fixed string length...) and fails to match the pattern (there're loads of boost::mpl::na or something like this). If there's no compiler flag to set, this will probably be a limitation.
There's some techniques users can apply to reduce symbol name lengths, as explained at http://boost.org/libs/multi_index/doc/compiler_specifics.html#symbol_reducti... but there's little else to be done from your side in the case the user has not applied some of these techniques of her own accord. Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
It seems that accessing node_count using the same technique as with ordered_unique does not work - I'm off by 4 bytes (see the (((char*)&$c)+4) expression).
I've examined this carefully and I can't see how the offset should be needed. What's the value the visualizer shows without the offset, i.e. when using the following expression?
size : ((multi_index_helper_3<$T2>*)&$c)->node_count
It gives 3. I've had a bad feeling about simulating multi_index_container structure before, and now it finally failed :-) I assume that it is because of structure alignment. When I did (($T2*)(((char*)&$c)-4))->node_count it worked well (i.e. assuming that the first member takes 4 bytes and casting back to the multi_index_container itself). That "4" can be probably calculated automatically, which involves the nasty trick with member pointers that I talked about earlier. But that involved a static int constant, so I'll stick to hard-coded 4 for now...
I'm afraid traversing a hashed index is no easy chore. There are two popular implementation techniques for TR1 unordered containers and related data structures (prestandard hash_sets and such):
a) As a single doubly linked lists of elements. b) As several singly linked lists, one for each nonempty bucket.
(for more info on this subject, see section F of http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2003/n1443.html )
With a), which is what Dinkumware's stdext::hash_* containers use, traversing the elements is exactly equivalent to doing so with an std::list, hence the simple visualizer code for stdext::hash_map you brought in here yesterday. With b), however, traversing all elements implies the following:
1. Going to the beginning of the hashed index's bucket array (which is not the header node), whose elements points to the corresponding associated element lists. 2. For each nonempty bucket, traverse the associated list. 3. When finished with a bucket, hop through the bucket array to the next nonempty bucket.
OK, I looked into buckets.spc.data_, visualized it as an array (I assume that buckets.spc.n_ is the number of buckets), and I got some hashed_index_node_impl nodes. I see that in some nodes, next_ points back to the node (empty bucket?), and with others there seems to be something more. I thought about the algorithm you describe, and I think that this is beyond what we can do (there is some #if ... #else ... stuff, but that is not recursive...). What I think we could do instead is to visualize the hashtable instead - display the buckets and their respective contents. A problem here might be that I don't know whether bucket item count is known. But let's deal with this later... (it's said that there's some anti-loop functionality in visualizer's list iterator, so let's see).
Do you think the visualizer is powerful enough to run this algorithm? If so, I can provide you with more details to begin writing the stuff.
If you can please tell me some info about the buckets.spc.data_ fields (if they really are the buckets, of course). What are the array members? hashed_index_node_impl?
Random access indices are also harder than ordered and sequenced, but I think it should be far simpler to support them than hashed indices. Please ping me if you're willing to crack that one.
Sure, I'll look at them and ask.
There is one more issue with hashed indices: the type names tend to get so long, that when I use more than one index with hashed_unique, the name gets cut in the half (some fixed string length...) and fails to match the pattern (there're loads of boost::mpl::na or something like this). If there's no compiler flag to set, this will probably be a limitation.
There's some techniques users can apply to reduce symbol name lengths, as explained at
http://boost.org/libs/multi_index/doc/compiler_specifics.html#symbol_reducti...
but there's little else to be done from your side in the case the user has not applied some of these techniques of her own accord.
Thanks for the info, I'll try the "intrusive" approach and see what it does to the visualizer (there will be probably a problem with the header_holder pattern...). (However....when a user does this, she can also adjust the visualizer, right? So I give this a low priority....:-)) Anyway, most of the time using the macros will suffice (that's what I'll do in my project). Cheers, Filip
----- Mensaje original ----- De: Filip Konvi?ka <filip.konvicka@logis.cz> Fecha: Sábado, Junio 2, 2007 0:27 am Asunto: Re: [Boost-users] [multi_index] MSVS 2005 visualizers? Para: boost-users@lists.boost.org
It seems that accessing node_count using the same technique as with ordered_unique does not work - I'm off by 4 bytes (see the (((char*)&$c)+4) expression).
I've examined this carefully and I can't see how the offset should be needed. What's the value the visualizer shows without the offset, i.e. when using the following expression?
size : ((multi_index_helper_3<$T2>*)&$c)->node_count
It gives 3.
What is the correct value?
I've had a bad feeling about simulating multi_index_container structure before, and now it finally failed :-) I assume that it is because of structure alignment. When I did
(($T2*)(((char*)&$c)-4))->node_count
it worked well (i.e. assuming that the first member takes 4 bytes and casting back to the multi_index_container itself). That "4" can be probably calculated automatically, which involves the nasty trick with member pointers that I talked about earlier. But that involved a static int constant, so I'll stick to hard-coded 4 for now...
What worries me is that I don't have a clue why having a hashed index as the first one makes a difference... Maybe you should try with more indexed_by combinations, including more than one or two indices, to see if the scheme is robust enough. All in all, I'd say the (($T2*)(((char*)&$c)-4))->node_count approach looks safer than the +4 one, and AFAICS it should work regardless of the header_node type --can you try this?
I'm afraid traversing a hashed index is no easy chore. [...] OK, I looked into buckets.spc.data_, visualized it as an array (I assume that buckets.spc.n_ is the number of buckets),
Almost correct. Strictly speaking, that n_ is bucket_count()+1, as the last position is reserved for a faux bucket pointing to the header node --which is where end() in hashed indices points to.
and I got some hashed_index_node_impl nodes. I see that in some nodes, next_ points back to the node (empty bucket?),
Correct.
and with others there seems to be something more.
Yep, these are nonempty buckets. Elements are linked in a circular fashion, so you know you're finished with the bucket when you're back at the starting position in the bucket array.
I thought about the algorithm you describe, and I think that this is beyond what we can do (there is some #if ... #else ... stuff, but that is not recursive...). What I think we could do instead is to visualize the hashtable instead - display the buckets and their respective contents. A problem here might be that I don't know whether bucket item count is known.
See my comments about circular chaining above.
But let's deal with this later... (it's said that there's some anti-loop functionality in visualizer's list iterator, so let's see).
Do you think the visualizer is powerful enough to run this algorithm? If so, I can provide you with more details to begin writing the stuff.
If you can please tell me some info about the buckets.spc.data_ fields (if they really are the buckets, of course). What are the array members? hashed_index_node_impl?
The bucket array constains elements of type hashed_index_node_impl*. Note that these pointers cannot be downcast to proper hashed_index_nodes, that is, they don't hold values: only the elements they point to are genuine hashed_index_nodes. [...]
There's some techniques users can apply to reduce symbol name lengths, as explained at
http://boost.org/libs/multi_index/doc/ compiler_specifics.html#symbol_reduction
but there's little else to be done from your side in the case the user has not applied some of these techniques of her own accord.
Thanks for the info, I'll try the "intrusive" approach and see what it does to the visualizer (there will be probably a problem with the header_holder pattern...). (However....when a user does this, she can also adjust the visualizer, right?
I'm not getting your question, sorry. Best, Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
----- Mensaje original ----- De: "JOAQUIN LOPEZ MU?Z" <joaquin@tid.es> Fecha: Sábado, Junio 2, 2007 1:48 pm Asunto: Re: [Boost-users] [multi_index] MSVS 2005 visualizers? Para: boost-users@lists.boost.org
----- Mensaje original ----- De: Filip Konvi?ka <filip.konvicka@logis.cz> Fecha: Sábado, Junio 2, 2007 0:27 am Asunto: Re: [Boost-users] [multi_index] MSVS 2005 visualizers? Para: boost-users@lists.boost.org
It seems that accessing node_count using the same technique as with ordered_unique does not work - I'm off by 4 bytes (see the (((char*)&$c)+4) expression).
Umm... I've been thinking a little more about this and it turns out that we can do the downcast legally without resorting to the multi_index_helper_3 hack. The following should work for any kind of header_holder: size : (($T2*)&$c)->node_count because T2 actually derives from header_holder<*,T2>. This would allow us to dispense with multi_index_helper_3 entirely. Can you check this out? Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
It seems that accessing node_count using the same technique as with ordered_unique does not work - I'm off by 4 bytes (see the (((char*)&$c)+4) expression).
Umm... I've been thinking a little more about this and it turns out that we can do the downcast legally without resorting to the multi_index_helper_3 hack. The following should work for any kind of header_holder:
size : (($T2*)&$c)->node_count
because T2 actually derives from header_holder<*,T2>. This would allow us to dispense with multi_index_helper_3 entirely. Can you check this out?
:-D of course it works. It seems that I'm no longer thinking of using the simplest and most obvious solutions. Thanks! I'll use this for all the visualizers. I am now able to display the array of buckets, I am able to tell an empty bucket from a non-empty one, and I am able to display the nodes in each non-empty bucket. Now I need to access the data. You said that the node that is in the array itself is not a data bucket, so I suppose that I need to start from .next_ and try to retrieve the data. What cast should I do here? Thanks, Filip
Filip Konvi?ka ha escrito:
I am now able to display the array of buckets, I am able to tell an empty bucket from a non-empty one, and I am able to display the nodes in each non-empty bucket. Now I need to access the data. You said that the node that is in the array itself is not a data bucket, so I suppose that I need to start from .next_ and try to retrieve the data. What cast should I do here?
The expression to use should be something like: *(multi_index_helper<boost::multi_index::detail::hashed_index_node<$T1>*) (boost::multi_index::detail::hashed_index_node<$T1>*) (boost::multi_index::detail::hashed_index_node_trampoline<$T1>*)(&$e) which is entirely analogous to what you have for ordered and sequenced nodes. Joaquín M López Muñoz Telefónica, Investigación y Desarrollo
The expression to use should be something like:
*(multi_index_helper<boost::multi_index::detail::hashed_index_node<$T1>*) (boost::multi_index::detail::hashed_index_node<$T1>*) (boost::multi_index::detail::hashed_index_node_trampoline<$T1>*)(&$e)
which is entirely analogous to what you have for ordered and sequenced nodes.
*)(void*)&$e ) ) } multi_index_helper_3<boost::multi_index::detail::hashed_index_node<*> >{
Yes, it works well now. I tried that on friday and it did not, but now I realize that I was probably passing a wrong $T1 to it. Just FYI, the visualizer looks like this: boost::multi_index::detail::header_holder<boost::multi_index::detail::hashed_index_node<*>,*>{ preview(#("multi_index_container hashed data")) children( #( #array( expr : (($T2*)&$c)->buckets.spc.data_[$i], size : (($T2*)&$c)->buckets.size_ ) : (multi_index_helper_3<boost::multi_index::detail::hashed_index_node<$T1> preview(#if ( ((boost::multi_index::detail::hashed_index_node_impl*)&$c)->next_==((boost::multi_index::detail::hashed_index_node_impl*)&$c) ) (#("<empty bucket>")) #else ( #("<non-empty bucket>") ) ) children( #( #list( head: ((boost::multi_index::detail::hashed_index_node_impl*)&$c)->next_, next: next_, skip: ((boost::multi_index::detail::hashed_index_node_impl*)&$c) ) : *(multi_index_helper<boost::multi_index::detail::hashed_index_node<$T1>
*)(boost::multi_index::detail::hashed_index_node<$T1>*)(boost::multi_index::detail::hashed_index_node_trampoline<$T1>*)(&$e) ) ) }
So what I do is that I cast each "bucket" (hashed_index_node_impl*) to my own type multi_index_helper_3<...>, which enables to visualize the buckets individually, and to have access to the item type at the same time. multi_index_helper_3 is defined as follows: template<> struct multi_index_helper_3< boost::multi_index::detail::multi_index_node_type<Type::value_type, Type::index_specifier_type_list, std::allocator<Type::value_type> >::type
{ }; where Type is the type of the container. [... some more coding ...] random_access index was not difficult... I tried with the linked list approach, but this was not so straightforward, so I used the array. It looks like everything works, so thanks very much for your time and patience! I'll post the new code, after some polishing, in the other thread. Cheers, Filip
I put in a post a little while ago that had visualizers for all of the boost::ptr_container classes and boost::array. But, unfortunately I haven't done much work yet with multi_index. That is a very nice blog post. I followed that myself when I made my custom entries. -- Bill --
-----Original Message----- From: boost-users-bounces@lists.boost.org [mailto:boost-users- bounces@lists.boost.org] On Behalf Of Filip Konvicka Sent: Wednesday, May 23, 2007 9:22 AM To: boost-users@lists.boost.org Subject: [Boost-users] [multi_index] MSVS 2005 visualizers?
Hi,
I just wanted to know if anyone succeeded creating a visualizer for multi_index containers. I'd love to spend some time doing that for the good of the community (and my own, of course :-)), but I could not find any data members for exploration in the debugger's watch window. Any suggestions?
See the following blog for more info: http://www.virtualdub.org/blog/pivot/entry.php?id=120 Some info can be found in the autoexp.dat file directly - there are pre-defined visualizers for eg. std::map (which works nice).
Thanks, Filip
_______________________________________________ Boost-users mailing list Boost-users@lists.boost.org http://lists.boost.org/mailman/listinfo.cgi/boost-users
I put in a post a little while ago that had visualizers for all of the boost::ptr_container classes and boost::array. But, unfortunately I haven't done much work yet with multi_index.
That is a very nice blog post. I followed that myself when I made my custom entries. Bill, great, I've read the discussion you had with Joaquin so I'm glad
that you were successful. I'll have a look at your visualizers then and see whether this can be somehow extended to multi_index. Cheers, Filip
participants (6)
-
 "JOAQUIN LOPEZ MU?Z"
"JOAQUIN LOPEZ MU?Z" -
 Bill Buklis
Bill Buklis -
 Filip Konvička
Filip Konvička -
Joaquin M Lopez Munoz
-
Joaquín Mª López Muñoz
-
 Matias Capeletto
Matias Capeletto