[phoenix] V2, V3 and the amount of memory needed by the compiler to just include them

Hello, Phoenix is an outstanding component, I have no doubt about that. However I have had some mixed results for my use case using V2 and now switching to V3. I'm writing a (header only/template) library which uses Boost.Phoenix internally. By nature this library (a mock object library) often ends up in precompiled headers because it's convenient to have it de facto included for whole (unit test) applications. By default Microsoft Visual Studio allocates a certain amount of memory for compiling a precompiled header, and if it actually needs more then it fails to compile. For instance with only : #include <boost/phoenix/phoenix.hpp> Here is the error message with vc80 : ...boost/fusion/container/vector/vector10.hpp(52) : error C3859: virtual memory range for PCH exceeded; please recompile with a command line option of '-Zm160' or greater ...boost/fusion/container/vector/vector10.hpp(52) : fatal error C1076: compiler limit : internal heap limit reached; use /Zm to specify a higher limit The location of the error is irrelevant, the value suggested by the compiler is what matters. Here it suggests to add /Zm160 to the command line. This is pretty huge, the default is actually /Zm100, and I'd say "big" Boost libraries are around 50. /Zm100 now means 75MB since vc90 instead of 50MB for vc80, which helps a bit, but still... Here is a quick survey I did with vc80, using a /Zm1 to trigger an error every time. The number on the right is the required /Zm value for including only the file on the left. boost/phoenix/phoenix.hpp 160 "equivalent of content of boost/phoenix/phoenix.hpp for Phoenix 2" 107 boost/phoenix/core/nothing.hpp 61 boost/spirit/home/phoenix/core/nothing.hpp 52 boost/phoenix/statement/throw.hpp 62 boost/spirit/home/phoenix/statement/throw.hpp 54 boost/phoenix/bind.hpp 43 boost/spirit/home/phoenix/bind.hpp 56 boost/bind.hpp 17 boost/lambda/bind.hpp 27 boost/lambda/lambda.hpp 30 boost/function.hpp 36 boost/function_types/function_type.hpp 31 boost/test/auto_unit_test.hpp 41 boost/concept_check.hpp 16 boost/type_traits/remove_reference.hpp 12 boost/proto/proto.hpp 55 boost/proto/domain.hpp 20 Note that an empty pch requires /Zm11 Now extracting only the includes from Phoenix to other Boost libraries using : grep -rh "include <b" . | sort -u And removing all boost/phoenix, the result is /Zm56 for V3 and /Zm65 for V2. So V3 reduces the code of Phoenix itself but now uses (a lot) more of other Boost libraries, which incidentally is consistent with the main target of V3 switching to Boost.Proto Of course the resulting amount of memory required for my library is not the sum of the memory required for each included library taken separately (mostly because they re-use each others). And furthermore I can mostly work around the issue by using only phoenix::bind and rewrite some of the missing bits (for instance phoenix::throw_ and phoenix::nothing) But even then and with carefully selecting the includes, it ends up pretty close to the default /Zm100. This means that if the users of my library add a couple more libraries to their pch (Boost.Test comes to mind), they will most certainly go over the limit. All right, after boggling a bit, they will add a bigger /Zm and forget about it for a while, until they upgrade either my library or Boost. Suddenly a lot of their test applications fail to compile because instead of some /Zm112 it now requires /Zm113, and they will need to go over all their projects and update them... For having this happening at my day job on a regular basis, I can attest first hand it is indeed annoying ! I started by saying I have had mixed results using Phoenix, this is because on one hand I resorted to rewriting what I needed using only phoenix::bind and I fear for the future usability of Phoenix, but on the other hand switching to V3 boost/phoenix/bind.hpp actually saves some memory compared to V2 boost/spirit/home/phoenix/bind.hpp ! Regards, MAT.

On 2/24/2011 7:58 AM, Mathieu Champlon wrote:
Phoenix is an outstanding component, I have no doubt about that. However I have had some mixed results for my use case using V2 and now switching to V3.
I'm writing a (header only/template) library which uses Boost.Phoenix internally. By nature this library (a mock object library) often ends up in precompiled headers because it's convenient to have it de facto included for whole (unit test) applications. By default Microsoft Visual Studio allocates a certain amount of memory for compiling a precompiled header, and if it actually needs more then it fails to compile.
We push the compilers hard. No doubt about that. The more (TMP) template metaprogramming infrastructure library beneath, the more harder it is for the compiler. Phoenix3 has MPL, Fusion and Proto under the hood. These are very powerful infrastructure libraries (Spirit has all these, plus Phoenix under its hood). I often hear people rant that TMP is not scalable. And you say that you "fear for the future usability of Phoenix". To be honest, I did too. I had a deep sabbatical last year and thought hard about the libraries that I authored (Spirit, Fusion and Phoenix). I was deeply troubled about these legitimate concerns. I was entertaining the idea of keeping things plain and simple again and wondered about how life would be without MPL, Proto and Fusion. Until yesterday... when Bryce Lelbach and Hartmut Kaiser ran the full Spirit regression tests on a 32 core machine with 64 GB of memory in a little more than one minute. Surely, you would say: but we don't have that kind of a machine! And I don't either :-) But here's one thing for sure: such multi-core machines with massive memory will be the norm soon (for a certain definition of "soon"). So to me, this argument goes back again to the days of 8-bit CPUs and 16KB RAM when people rant about the usability of higher level languages vs. plain assembler. And quoting Michael Caisse: "Hello, welcome to 2011. Multicore processors and memory almost grow on trees." So will TMP scale? Definitely! Will there be a future for Phoenix and other template heavy libraries? Unequivocally YES! At the very least I would say: Phoenix3 is ahead of its time. Thomas Heller did an amazing job! Regards, -- Joel de Guzman http://www.boostpro.com http://boost-spirit.com

On 2/24/2011 8:57 AM, Joel de Guzman wrote:
So will TMP scale? Definitely! Will there be a future for Phoenix and other template heavy libraries? Unequivocally YES!
At the very least I would say: Phoenix3 is ahead of its time. Thomas Heller did an amazing job!
Ugh, these valid concerns about compile time and space are ... valid. Yes, it'll get better over time, Joel's right, but there are things that can be done today. Proto and Fusion can be preprocessed like MPL. Proto can use variadic templates and rvalue references where available to bring down the number of overloads. Things /can/ be better today. If only there were more time. Or some volunteers? -- Eric Niebler BoostPro Computing http://www.boostpro.com
On 2/24/2011 11:00 AM, Eric Niebler wrote:
On 2/24/2011 8:57 AM, Joel de Guzman wrote:
So will TMP scale? Definitely! Will there be a future for Phoenix and other template heavy libraries? Unequivocally YES!
At the very least I would say: Phoenix3 is ahead of its time. Thomas Heller did an amazing job!
Ugh, these valid concerns about compile time and space are ... valid. Yes, it'll get better over time, Joel's right, but there are things that can be done today. Proto and Fusion can be preprocessed like MPL. Proto can use variadic templates and rvalue references where available to bring down the number of overloads. Things /can/ be better today. If only there were more time.
If you go back to the Op's main concern, it is about VS PCH limits with Phoenix3 at about /Zm160 and VC8's default: /Zm100 which is at about 75MB and "big" Boost libraries are around /Zm50. Yes, things can be better today, but only to a certain extent. This is one that I do not think we can fix other than to bump to /ZM160 and beyond. Regards, -- Joel de Guzman http://www.boostpro.com http://boost-spirit.com

On 2/24/2011 8:57 AM, Joel de Guzman wrote:
So will TMP scale? Definitely! Will there be a future for Phoenix and other template heavy libraries? Unequivocally YES!
At the very least I would say: Phoenix3 is ahead of its time. Thomas Heller did an amazing job!
Ugh, these valid concerns about compile time and space are ... valid. Yes, it'll get better over time, Joel's right, but there are things that can be done today. Proto and Fusion can be preprocessed like MPL. Proto can use variadic templates and rvalue references where available to bring down the number of overloads. Things /can/ be better today. If only there were more time.
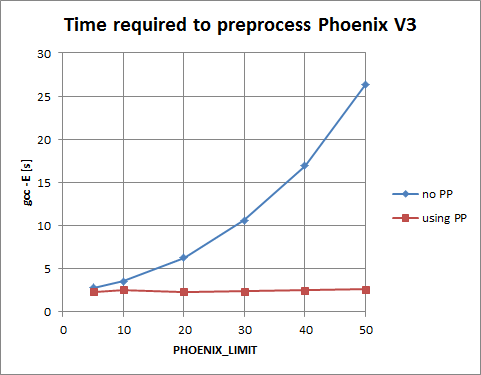
Thomas and I found a nice and simple way to do the preprocessing to Phoenix V3 which required a coupe of hours of hacking for it to be added. The effect was significant (see attached figure). Therefore, I can only encourage to add partial preprocessing to Fusion and Proto! Regards Hartmut --------------- http://boost-spirit.com
{kind=link}
On 2/24/2011 10:26 AM, Hartmut Kaiser wrote:
Thomas and I found a nice and simple way to do the preprocessing to Phoenix V3 which required a coupe of hours of hacking for it to be added. The effect was significant (see attached figure). Therefore, I can only encourage to add partial preprocessing to Fusion and Proto!
I'm not sure I understand this graph, Hartmut. It's entitled, "Time to Preprocess Phoenix", and it plots "No PP" against "Using PP". What does "no pp" and "using pp" signify here? Also, making the PP phase faster is only interesting if it is a significant portion of the overall compilation time. I'd be more interested in plotting overall time, not just PP time. Thanks for doing this! I hope to steal your work for Proto. -- Eric Niebler BoostPro Computing http://www.boostpro.com

On Thursday, February 24, 2011 12:10:17 PM Eric Niebler wrote:
On 2/24/2011 10:26 AM, Hartmut Kaiser wrote:
Thomas and I found a nice and simple way to do the preprocessing to Phoenix V3 which required a coupe of hours of hacking for it to be added. The effect was significant (see attached figure). Therefore, I can only encourage to add partial preprocessing to Fusion and Proto!
I'm not sure I understand this graph, Hartmut. It's entitled, "Time to Preprocess Phoenix", and it plots "No PP" against "Using PP". What does "no pp" and "using pp" signify here?
No PP means no pre pre processing has been done (aka a regular compilation). Using PP means that all the code has been preprocessed prior to the actual compilation.
Also, making the PP phase faster is only interesting if it is a significant portion of the overall compilation time.
The time for preprocessing the fusion/proto/phoenix headers stays constant (if you don't increase the PP limit macros), it is about 2 seconds on my machine. The time spent in the PP phase becomes less signifcant when the actual expressions get more and more complicated, i.e. if we deal with TUs that already take half a minute to compile. However, I believe it is one (little) step in the direction of bringing compile times down. In Phoenix V3 Hartmut contributed PP code that lets us partially preprocess the headers with Boost.Wave, which I think would be a great idea if we could generalize it and deploy that technique in all PP heavy libs.
I'd be more interested in plotting overall time, not just PP time.
Thanks for doing this! I hope to steal your work for Proto.
On 2/24/2011 10:26 AM, Hartmut Kaiser wrote:
Thomas and I found a nice and simple way to do the preprocessing to Phoenix V3 which required a coupe of hours of hacking for it to be added. The effect was significant (see attached figure). Therefore, I can only encourage to add partial preprocessing to Fusion and Proto!
I'm not sure I understand this graph, Hartmut. It's entitled, "Time to Preprocess Phoenix", and it plots "No PP" against "Using PP". What does "no pp" and "using pp" signify here?
Yeah, the captions are a bit misleading, sorry for that. What it shows is the preprocessing time for all of Phoenix with partially preprocessed headers (using PP) and without (no PP).
Also, making the PP phase faster is only interesting if it is a significant portion of the overall compilation time. I'd be more interested in plotting overall time, not just PP time.
Definitely, but the point was to see improvements in the preprocessing phase as the compilation phase is independent of this.
Thanks for doing this! I hope to steal your work for Proto.
Regards Hartmut --------------- http://boost-spirit.com

On 24/02/11 04:00, Eric Niebler wrote:
On 2/24/2011 8:57 AM, Joel de Guzman wrote:
So will TMP scale? Definitely! Will there be a future for Phoenix and other template heavy libraries? Unequivocally YES!
At the very least I would say: Phoenix3 is ahead of its time. Thomas Heller did an amazing job! Ugh, these valid concerns about compile time and space are ... valid. Yes, it'll get better over time, Joel's right, but there are things that can be done today. Proto and Fusion can be preprocessed like MPL. Proto can use variadic templates and rvalue references where available to bring down the number of overloads. Things /can/ be better today. If only there were more time.
Or some volunteers? What about trying a GSoC on this ?
On 2/24/2011 1:22 PM, Joel Falcou wrote:
On 24/02/11 04:00, Eric Niebler wrote:
Proto and Fusion can be preprocessed like MPL. Proto can use variadic templates and rvalue references where available to bring down the number of overloads. Things /can/ be better today. If only there were more time.
Or some volunteers?
What about trying a GSoC on this ?
Forgive me, but that's a crap job that would be wasted on a GSoC project. :-D It's a job for someone who is fed up with compiles times (or with people complaining about them). It's not challenging or glorious. It's just very, very tedious. But maybe Hartmut and Thomas have this problem licked with their semi-automated solution. Hope so! A more interesting GSoC project would be a next-gen EDSL toolkit (Proto 2?) that makes full use of C++0x features. Better compile times could be a goal. My .02, -- Eric Niebler BoostPro Computing http://www.boostpro.com

On Thu, Feb 24, 2011 at 6:09 AM, Eric Niebler <eric@boostpro.com> wrote:
Forgive me, but that's a crap job that would be wasted on a GSoC project. :-D
I think you're projecting a bit, Eric. If I were a GSoC volunteer, making dramatic speedups in important Boost libraries by refactoring them would be very attractive to me. Not everybody feels ready to design a whole new library. -- Dave Abrahams BoostPro Computing http://www.boostpro.com
On 3/1/2011 8:07 AM, Dave Abrahams wrote:
On Thu, Feb 24, 2011 at 6:09 AM, Eric Niebler <eric@boostpro.com> wrote:
Forgive me, but that's a crap job that would be wasted on a GSoC project. :-D
I think you're projecting a bit, Eric. If I were a GSoC volunteer, making dramatic speedups in important Boost libraries by refactoring them would be very attractive to me. Not everybody feels ready to design a whole new library.
Whoops, I've mouthed off again. Sorry about that. I didn't mean to imply that it isn't a worthy goal, just that it requires little creativity. But I'll allow that my notion of what constitutes a worthwhile GSoC project may be biased. But if a student were to also use rvalue refs and variadic templates in places to eliminate unnecessary overloads, that would require something beyond the abilities of a trained monkey. (Oops, I did it again!) -- Eric Niebler BoostPro Computing http://www.boostpro.com
On 01/03/11 04:45, Eric Niebler wrote:
Whoops, I've mouthed off again. Sorry about that. I didn't mean to imply that it isn't a worthy goal, just that it requires little creativity. But I'll allow that my notion of what constitutes a worthwhile GSoC project may be biased.
But if a student were to also use rvalue refs and variadic templates in places to eliminate unnecessary overloads, that would require something beyond the abilities of a trained monkey. (Oops, I did it again!)
I think it cost nothign to propose the project and see what happens

On 1 March 2011 04:45, Eric Niebler <eric@boostpro.com> wrote:
On 3/1/2011 8:07 AM, Dave Abrahams wrote:
On Thu, Feb 24, 2011 at 6:09 AM, Eric Niebler <eric@boostpro.com> wrote:
Forgive me, but that's a crap job that would be wasted on a GSoC project. :-D
I think you're projecting a bit, Eric. If I were a GSoC volunteer, making dramatic speedups in important Boost libraries by refactoring them would be very attractive to me. Not everybody feels ready to design a whole new library.
Whoops, I've mouthed off again. Sorry about that. I didn't mean to imply that it isn't a worthy goal, just that it requires little creativity. But I'll allow that my notion of what constitutes a worthwhile GSoC project may be biased.
But if a student were to also use rvalue refs and variadic templates in places to eliminate unnecessary overloads, that would require something beyond the abilities of a trained monkey. (Oops, I did it again!)
Well as a student I'll give my opinion... I agree with you that a no-brainer project would be a no-go for a GSoC project for sure. Now the problem is in the definition of "no-brainer". Surely if it consists only in a basic search and replace it might be a bit simple (monkey work as you say :p), but if it's a bit more complicated and in the end it decreases compiles time a lot it might be interesting despite the "no-creativity" part. On the other hand, I, for one, do not feel like designing a whole new proto from scratch as a GSoC proto... Mathieu-
On Mon, Feb 28, 2011 at 10:45 PM, Eric Niebler <eric@boostpro.com> wrote:
I think you're projecting a bit, Eric. If I were a GSoC volunteer, making dramatic speedups in important Boost libraries by refactoring them would be very attractive to me. Not everybody feels ready to design a whole new library.
Whoops, I've mouthed off again. Sorry about that. I didn't mean to imply that it isn't a worthy goal, just that it requires little creativity. But I'll allow that my notion of what constitutes a worthwhile GSoC project may be biased.
Not to mention your notion of what constitutes creativity ;-) -- Dave Abrahams BoostPro Computing http://www.boostpro.com

We use Boost quite heavy in our products, but they are build time killers. A comparable product which uses less Boost compiles twice as fast. Currently on my production quad core (a W3530 processor) it takes about 40 minutes. Note that we already use some of the more basic stuff in the pch. Common libraries as operators, variant, multi index and range can make ur compiler cry. Sometimes u have to use the pimpl idiom just to shield header includes from clients. I understand that this is unfortunate. Runtime performance stays more important ofc. Forum item just to inform u.
participants (9)
-
 Dave Abrahams
Dave Abrahams -
 Eric Niebler
Eric Niebler -
 gast128
gast128 -
 Hartmut Kaiser
Hartmut Kaiser -
 Joel de Guzman
Joel de Guzman -
 Joel Falcou
Joel Falcou -
 Mathieu -
Mathieu - -
 Mathieu Champlon
Mathieu Champlon -
 Thomas Heller
Thomas Heller